Prix de Hermes Agent : tarifs mensuels réels et détail des coûts en 2026
Jul 01, 2026
/
Suzy K.
/
10 minutes de lecture
L’exécution de l’agent Hermes coûte entre 5 € et 80 € par mois, selon le modèle de langage utilisé pour le raisonnement.
Le logiciel est gratuit sous licence MIT. Le coût provient donc de deux sources : l’hébergement VPS pour le processus de l’agent et les appels à l’API du LLM à chaque étape de raisonnement.
La facture complète se décompose en quatre parties :
- Hébergement VPS. De 4 € à 25 € par mois pour le serveur qui exécute le processus de l’agent.
- Appels d’API LLM. De 2 € à 60 € par mois, selon le modèle utilisé pour le raisonnement.
- Abonnement optionnel à Nous Portal. 0 € pour l’offre gratuite ou 20 € par mois pour l’offre Plus avec des outils inclus.
- Services d’outils en option. Recherche sur le Web, génération d’images, automatisation du navigateur et synthèse vocale lorsqu’elles ne sont pas incluses.
Comparée à ChatGPT Plus à 20 € par mois ou à Claude Pro à 17 € par mois, une configuration Hermes à petit budget coûte moins de la moitié. Une configuration premium coûte deux à quatre fois plus cher, mais elle ne comporte pas de limites d’utilisation.
La rentabilité de la configuration dépend de l’utilisation que vous en faites. À partir de quelques centaines de sessions d’agent par mois, et au-delà, le rapport coût-efficacité devient plus avantageux. En dessous de ce seuil, un abonnement grand public à tarif fixe est moins cher et plus simple.
Hébergement VPS
L’hébergement VPS correspond au coût mensuel fixe du serveur qui exécute Hermes Agent. Le processus de l’agent est léger. Une instance avec 1 Go de RAM et 1 vCPU convient donc à la plupart des configurations cloud de LLM.
Configuration recommandée selon la charge de travail :
- Minimum : 1 Go de RAM, 1 vCPU, suffisant lorsqu’un LLM cloud gère le raisonnement.
- Automatisation de navigateur. 2 à 4 Go de RAM.
- Ollama en local, de 7B à 13B. 4 Go de RAM minimum.
- Modèles 70B en local. GPU serverless facturé à la seconde, environ 40 à 80 € par mois pour une utilisation légère. Une instance toujours active coûte bien plus cher.
Parmi les fournisseurs courants, on retrouve Hostinger, à partir de €5.49/mois, Hetzner, DigitalOcean, ainsi que des options serverless comme Modal, qui se mettent en veille lorsqu’elles sont inactives. La plupart des configurations coûtent entre 4 € et 25 € par mois.
Le VPS Hostinger avec configuration Docker en 1 clic couvre la plage de 1 à 4 Go de RAM dont Hermes Agent a besoin pour les configurations légères et l’automatisation de navigateur.
L’un des pièges à éviter dans votre budget est que le prix d’appel d’un VPS ne dure pas. Les tarifs de renouvellement sont généralement plus élevés que les tarifs promotionnels. Prévoyez donc votre budget en fonction du prix de renouvellement plutôt que du prix de lancement. Un pack à partir de 4 € par mois peut être renouvelé entre 10 € et 12 € par mois.
La facturation horaire est un autre piège. Une instance à 0,24 € de l’heure coûte environ 173 € par mois si elle reste allumée en continu. Pour les déploiements Hermes toujours actifs, une tarification mensuelle fixe est plus avantageuse qu’une facturation à l’heure.
Appels à l’API des LLM (inférence)
Les appels à l’API LLM constituent le coût variable de chaque requête de modèle effectuée par Hermes Agent. Les fournisseurs facturent en euros par million de jetons d’entrée et de sortie, et la boucle de raisonnement de l’agent peut envoyer des dizaines de requêtes au cours d’une seule session.
Les fournisseurs facturent séparément les jetons d’entrée (input), que vous envoyez au modèle, et les jetons de sortie (output), générés par le modèle en réponse. Voici un aperçu des tarifs pratiqués à la mi-2026 :
- Entrée de gamme. DeepSeek V4 Flash coûte 0,14 € par million de jetons d’entrée et 0,28 € par million de jetons de sortie. GPT-5.4 Nano coûte 0,20 € par million de jetons d’entrée et 1,25 € par million de jetons de sortie. Gemini 3.1 Flash-Lite coûte 0,25 € par million de jetons d’entrée et 1,50€ par million de jetons de sortie.
- Milieu de gamme. Claude Haiku 4.5 coûte 1 € par million de jetons d’entrée et 5 € par million de jetons de sortie.
- Haut de gamme. Claude Sonnet 4.6 coûte 3 € par million de jetons d’entrée et 15 € par million de jetons de sortie. Claude Opus 4.8 coûte 5 € par million de jetons d’entrée et 25 € par million de jetons de sortie.
- Agrégateur. OpenRouter donne accès à plus de 300 modèles via une API unique, moyennant une légère majoration.
Deux mécanismes influencent la facture au-delà du prix affiché. Le premier concerne la tarification des cache hits. Par exemple, pour un million de jetons d’entrée, DeepSeek V4 Flash facture 0,14 € en cas de cache miss et 0,0028 € en cas de cache hit, soit une réduction de 98 %.
La tarification du cache compte davantage pour Hermes que pour les chatbots, car l’agent renvoie à chaque requête une charge utile fixe contenant les définitions des outils. Cela signifie que la réduction se cumule au fil d’une session.
Le deuxième mécanisme est le résumeur par compression. Lorsqu’une conversation dépasse le seuil de contexte par défaut de 50 %, Hermes envoie un appel distinct au LLM pour compresser l’historique, ce qui ajoute davantage de jetons à la facture.
La façon dont vous vous adressez à l’agent a aussi un impact sur la facture. Hermes envoie entre 6 000 et 8 000 jetons de définitions d’outils via la CLI, et entre 15 000 et 20 000 jetons via des passerelles de messagerie comme Telegram ou Discord à chaque requête.
Passer d’une passerelle à la CLI réduit la surcharge par requête d’un facteur de 2 à 3.
Avec une configuration économique basée sur DeepSeek V4 Flash, une journée d’utilisation intensive d’un agent en plusieurs étapes ne coûte que quelques euros en jetons. La même charge de travail sur Claude Opus 4.8 coûte environ 30 fois plus cher, puisque Opus coûte 5 € / 25 € par million de jetons, contre 0,14 € / 0,28 € pour Flash.
Abonnement à Nous Portal (facultatif)

Nous Portal est un abonnement facultatif proposé par Nous Research. Les packs payants regroupent plus de 300 modèles et quatre outils principaux — recherche sur le web, génération d’images, synthèse vocale et automatisation du navigateur — sur une seule facture.
Il a été lancé le 27 avril 2026 et se connecte via une configuration OAuth unique avec hermes setup –portal. Les paliers actuels sont :
- Gratuit. 0 € par mois, avec des crédits à l’usage à partir de 10 €, convertis à l’identique. Ainsi, 10 € vous donnent droit à 10 € d’utilisation. Cela suffit pour une évaluation rapide, mais pas pour des charges de travail réelles.
- Plus. 20 € par mois, avec 22 € de crédit d’utilisation mensuel.
- Parfait. 100 € par mois, avec 110 € de crédit d’utilisation mensuel.
- Ultra. 200 € par mois, avec 220 € de crédit d’utilisation mensuel et les limites de débit les plus élevées de tous les packs.
Chaque pack payant inclut le crédit mensuel indiqué à chaque cycle de facturation. L’offre gratuite fait exception : elle ne comprend aucun crédit inclus et n’inclut pas Tool Gateway. Elle convient donc davantage à une évaluation rapide qu’à un usage prolongé.
Si vous payez déjà séparément pour la recherche sur le web, la génération d’images et l’automatisation du navigateur, l’offre Plus à 20 € est généralement plus économique que de prendre chaque outil séparément. Le portail Nous n’est pas requis : OpenRouter, les clés API Anthropic ou OpenAI directes, ainsi qu’Ollama en local fonctionnent tous sans lui.
Services de l’outil (facultatif)
Les services d’outils sont des API externes qu’Hermes Agent appelle lorsqu’il effectue des recherches sur le web, utilise un navigateur, génère des images ou convertit du texte en parole. Lorsque vous ne les faites pas passer par Nous Portal, chaque service facture ses propres frais basés sur l’utilisation.
Fournisseurs courants par catégorie :
- Recherche sur le Web. Firecrawl, Tavily, Exa.
- Automatisation du navigateur. Utilisation du navigateur.
- Génération d’images. FAL.
- Synthèse vocale. ElevenLabs, audio OpenAI.
- Bac à sable d’exécution du code. Fenêtre modale.
Pour un usage léger, ces services ne coûtent que quelques euros par mois. C’est en cas d’utilisation plus intensive des outils que l’offre Nous Portal Plus incluse commence à devenir avantageuse.
L’automatisation du navigateur est l’outil qui consomme le plus de CPU et nécessite souvent de passer à un pack supérieur à un VPS avec 1 Go de RAM.
Chemin d’accès du matériel local (alternative)
L’option sur matériel local supprime les coûts mensuels d’inférence, mais vous devrez posséder le matériel nécessaire et accepter une qualité de raisonnement inférieure. Hermes Agent communique avec un modèle exécuté localement via l’API standard compatible avec OpenAI.
Configuration matérielle requise selon la taille du modèle :
- Modèles de 7B à 13B. 4 Go de RAM minimum, ou 6 à 8 Go de VRAM pour l’accélération GPU.
- Modèles 27B. Apple Silicon avec mémoire unifiée. Par exemple, une puce M3 Pro avec 36 Go peut prendre en charge un modèle 27B avec un contexte de 64K.
- Modèles 70B. GPU cloud serverless facturé à la seconde, environ 40 € à 80 € par mois pour une utilisation légère. Une instance toujours active coûte bien plus cher.
Parmi les bons points de départ, vous pouvez choisir Qwen 3 8B pour un bon rapport qualité-prix et Llama 4 Maverick pour des capacités de raisonnement plus poussées.
La plupart des ordinateurs portables de développeur peuvent exécuter Qwen 3 8B. L’étape de compression de l’agent Hermes nécessite un modèle auxiliaire avec une fenêtre de contexte d’au moins 64K. Vous ne pouvez donc pas réutiliser telle quelle une configuration Ollama par défaut de 4K.
Les modèles locaux sont à la traîne par rapport à Claude Sonnet pour le raisonnement complexe en plusieurs étapes. Ils gèrent bien les tâches courantes, mais pas celles où une seule inférence erronée peut entraîner un échec en cascade de l’exécution.
Comment réduire le coût de Hermes Agent
Le moyen le plus rapide de réduire une facture Hermes Agent consiste à vérifier vos paramètres, pas à changer de modèle. Ajuster les outils, le modèle de compression et les plafonds de dépenses du fournisseur peut réduire les coûts sans changer votre LLM principal.
Les paramètres par défaut de l’agent supposent que vous souhaitez activer tous les outils et résumer les conversations de manière agressive. Ces paramètres par défaut peuvent augmenter vos coûts.
Quatre tactiques, par ordre d’impact :
- Passez à un modèle compatible avec le cache. DeepSeek V4 Flash offre une réduction de 98 % sur les accès au cache, qui s’accumule au fil des longues sessions d’agent. Sur les charges de travail fortement dépendantes du cache, les mêmes tâches peuvent coûter deux fois moins cher, voire davantage, que sur Claude Opus.
- Supprimez les outils inutilisés. Passer d’une passerelle de messagerie à la CLI réduit la surcharge de jetons par requête d’un facteur de 2 à 3. Désactiver les outils que vous n’utilisez pas le réduit encore davantage.
- Utilisez un modèle de compression moins coûteux. Hermes envoie une requête de résumé distincte dès qu’une conversation dépasse le seuil de contexte par défaut de 50 %. Acheminer cette requête vers un modèle économique comme DeepSeek V4 Flash ou GPT-5.4 Nano permet de réduire un coût caché.
- Définissez des plafonds de dépenses pour les fournisseurs. OpenRouter, Anthropic et OpenAI proposent tous des plafonds stricts de dépenses mensuelles. Définissez-en un légèrement au-dessus de votre budget cible afin d’éviter qu’une boucle incontrôlée de l’agent ne génère des frais imprévus.
Les deux surprises de facturation les plus courantes sont les frais liés à la définition des outils et le résumeur de compression. Si votre facture augmente soudainement de façon inattendue, vérifiez d’abord la passerelle choisie.
Passer de Telegram à l’interface en ligne de commande est souvent la solution la plus rapide. Vérifiez ensuite si votre modèle principal prend en charge la tarification du cache. Passer à DeepSeek V4 Flash peut réduire de 50 % ou plus une facture fortement axée sur Claude pour les charges de travail qui utilisent beaucoup le cache.
Coût de Hermes Agent par rapport à ChatGPT Plus, Claude Pro et OpenClaw Cloud
Par rapport aux forfaits grand public à tarif fixe, une configuration Hermes économique coûte moins cher, tandis qu’une configuration premium échange une facture mensuelle plus élevée contre une utilisation illimitée. Le tableau ci-dessous compare les coûts mensuels typiques pour un développeur indépendant, sur la base des tarifs publics en vigueur en juin 2026.
Pack | Coût mensuel | Type de coût | Idéal pour |
Agent Hermes (budget) | 5–8 € | Variable (hébergement + jetons) | Développeurs indépendants avec des charges de travail légères |
Agent Hermes (premium) | 40–80 € | Variable | Des workflows de modèles de pointe sans limites d’utilisation |
ChatGPT Plus | 20 € | Abonnement à tarif fixe | Chat mono-utilisateur avec utilisation limitée |
Claude Pro | 17 € | Abonnement forfaitaire | Utilisateurs d’Anthropic avec une utilisation plafonnée |
OpenClaw Cloud | 59 € | Service géré à tarif fixe | Les équipes qui souhaitent une infrastructure d’agents prévisible |
Choisissez Hermes Agent si vous souhaitez un contrôle total et que votre charge de travail reste inférieure à 1 million de jetons par jour. Choisissez un abonnement grand public à tarif fixe si vous préférez une facture mensuelle prévisible et que vous n’avez pas besoin de flux de travail d’agents autonomes.
OpenClaw Cloud est la seule alternative gérée de cette comparaison. Les différences entre Hermes Agent et OpenClaw se résument au modèle de déploiement et au coût total.
Hermes Agent est-il moins cher que ChatGPT Plus ?
Cela dépend du modèle que vous utilisez. Une configuration économique de Hermes Agent sur Hetzner avec DeepSeek V4 Flash coûte à partir d’environ 5 € par mois, soit bien moins que ChatGPT Plus à 20 € par mois. Une configuration premium utilisant Claude Sonnet 4.6 coûte plus cher.
Le seuil de rentabilité dépend de deux facteurs. L’utilisation de jetons détermine à partir de quel moment une configuration premium devient plus coûteuse que l’abonnement fixe à 20 €, tandis que le volume de sessions permet de savoir si le temps consacré à la configuration et à la maintenance de Hermes Agent justifie les économies réalisées.
Quand le coût de Hermes Agent est justifié (et quand il ne l’est pas)
Le coût de Hermes Agent est pertinent lorsque votre utilisation est régulière et repose sur des workflows intensifs, plutôt que sur des questions occasionnelles. Les cas d’usage d’Hermes Agent les plus rentables sont les tâches en plusieurs étapes qui déclenchent de nombreux appels au modèle, lorsqu’une configuration permanente peut justifier son coût.
En dessous de quelques centaines de sessions d’agent par mois, les abonnements grand public à tarif fixe sont généralement plus avantageux, car leurs frais fixes se répartissent sur un volume d’utilisation que vous n’avez pas à gérer directement.
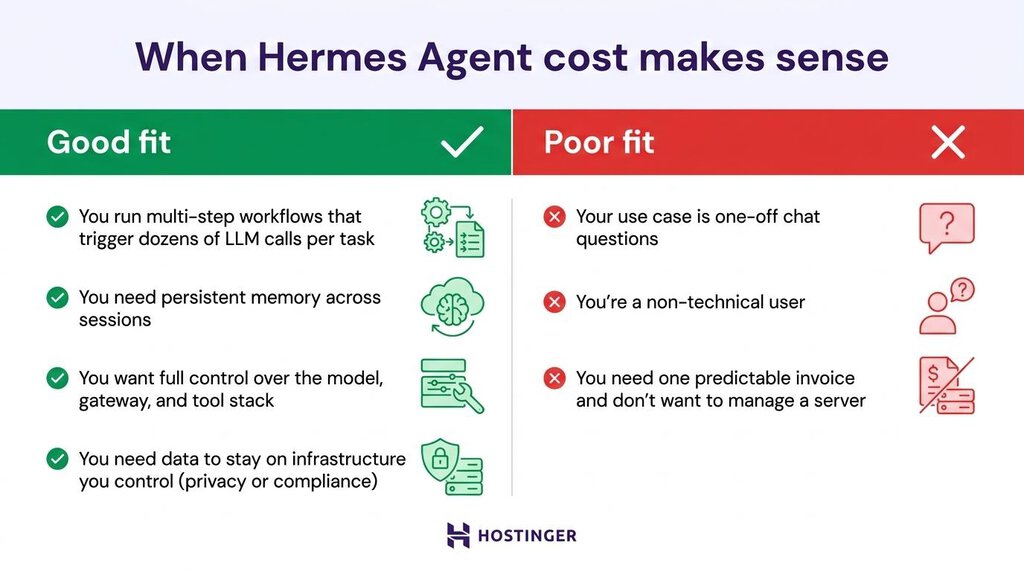
Adapté si :
- Vous exécutez des flux de travail en plusieurs étapes qui déclenchent des dizaines d’appels à des LLM pour chaque tâche.
- Vous avez besoin d’une mémoire persistante entre les sessions, ce que Hermes gère nativement.
- Vous souhaitez garder un contrôle total sur le modèle, la passerelle et la pile d’outils.
- Vous avez besoin que les données restent sur une infrastructure que vous contrôlez, pour des raisons de confidentialité ou de conformité.
À éviter lorsque :
- Votre cas d’usage concerne des questions ponctuelles dans un chat, et non des flux de travail autonomes.
- Vous n’êtes pas à l’aise avec la technique, car configurer Hermes Agent pourrait vous faire perdre plus de temps que cela ne vous en ferait gagner.
- Vous avez besoin d’une facture prévisible et vous ne voulez pas gérer un serveur.
Si votre principal cas d’usage consiste à poser des questions ponctuelles, restez sur ChatGPT ou Claude. Au-delà de quelques centaines de sessions par mois, les économies réalisées et le niveau de contrôle peuvent justifier la charge de gestion supplémentaire.
Définir le budget de votre agent Hermes
Pour définir le budget de votre agent Hermes, choisissez d’abord le modèle, puis le fournisseur. Cette seule décision peut multiplier votre coût mensuel par 30, bien davantage que n’importe quel choix d’hébergement.
Un LLM économique exécuté sur un serveur à 4 € par mois et un LLM de pointe exécuté sur le même serveur peuvent générer des factures dont le montant diffère d’environ 30 fois. C’est pourquoi votre première décision de planification doit porter sur le modèle dont votre charge de travail a réellement besoin.
Une fois que vous avez choisi un niveau de modèle, surveillez deux métriques dans le tableau de bord de votre fournisseur. Le premier est le taux de réussite du cache. Avec un modèle optimisé pour le cache comme DeepSeek V4 Flash, les définitions d’outils répétées sont mises en cache et donnent droit à une tarification réduite. Ce ratio devrait donc augmenter au fil du temps.
Le second correspond au nombre de jetons par requête. Une configuration CLI ajoute généralement 6 000 à 8 000 jetons de surcharge par requête. Si ce nombre passe soudainement à 15 000 ou 20 000 jetons, il se peut que vous soyez passé à une passerelle de messagerie comme Telegram ou Discord, ou que vous ayez ajouté un outil qui passe par l’une d’elles.
Enfin, définissez un rappel deux semaines avant la date de renouvellement de votre VPS afin qu’une augmentation de prix ne vous prenne pas au dépourvu.
Tout le contenu des tutoriels de ce site est soumis aux normes éditoriales et aux valeurs rigoureuses de Hostinger.

Spécialiste de la localisation et du marketing digital depuis plus de dix ans, Suzy se passionne pour les nouvelles technologies et cultive également un penchant très français pour les arts de la table, les vins et les spiritueux. Le reste du temps, elle se consacre aux voyages et aux promenades avec son chien.



Commentaires
0 responses