Qu’est-ce que la sécurité du vibe coding ? Risques et bonnes pratiques
Jun 18, 2026
/
Faradilla A.
/
20 minutes de lecture
La sécurité du vibe coding consiste à protéger les applications générées par l’IA en vérifiant le code, les dépendances, les contrôles d’accès et les flux de travail de développement.
Le vibe coding consiste à générer du code avec l’IA à l’aide de prompts en langage naturel, au lieu de tout écrire manuellement. Cela accélère le développement, mais cela comporte aussi des risques.
L’IA peut produire des fonctionnalités qui semblent fonctionner en apparence, tout en intégrant des paramètres par défaut non sécurisés, des secrets exposés, une authentification faible ou des dépendances vulnérables.
Créer des applications générées avec l’IA plus sûres dépend de votre capacité à repérer ces lacunes dès le départ. Cela signifie appliquer des contrôles de sécurité dès le départ, vérifier ce que le code fait réellement et utiliser les bons outils pour détecter les problèmes avant qu’ils n’atteignent l’environnement de production.
Comment le vibe coding crée-t-il des risques de sécurité ?
Le vibe coding crée des risques de sécurité, car l’IA génère du code sans validation de sécurité.
Les grands modèles de langage (LLM) ne comprennent pas la sécurité de la même manière qu’un développeur ou qu’un expert en audit de sécurité.
Ces modèles prédisent le schéma le plus probable à partir des données d’entraînement. Cela les aide à produire du code rapidement, mais pas à déterminer si ce code est sécurisé. Un modèle peut générer quelque chose qui semble propre, fonctionne dans une démo et échoue malgré tout aux contrôles de sécurité de base.
Le premier problème, c’est que les LLM prédisent des schémas, pas une logique sécurisée. Ils reproduisent des structures de code courantes à partir d’exemples qu’ils ont vus, et beaucoup de ces exemples sont incomplets, obsolètes ou non sécurisés.
Un flux de connexion, un formulaire de paiement, une fonctionnalité de téléversement de fichiers ou un endpoint d’API peuvent sembler corrects en apparence, tout en ne disposant pas des vérifications nécessaires pour protéger réellement les utilisateurs et les données.
Le deuxième problème est le manque de compréhension du contexte. Un code sécurisé dépend de l’ensemble du système qui l’entoure : la façon dont les utilisateurs se connectent, les données auxquelles ils peuvent accéder, l’emplacement où les secrets sont stockés, les rôles existants et ce qui doit se passer en cas d’échec.
Un modèle d’IA ne voit généralement que le prompt et le petit extrait de code que vous lui avez fourni. Il ne comprend pas de manière fiable l’ensemble de votre application, votre modèle de menace ni vos exigences de conformité.
Par conséquent, il peut ajouter du code qui entre en conflit avec le reste du système ou crée une faille entre des composants qui semblaient sûrs pris isolément.
Le troisième problème est qu’il n’y a aucun contrôle de sécurité intégré pendant la génération. Un modèle peut produire du code, mais la génération n’est pas la même chose que la revue, les tests ou la validation.
Les logiciels sécurisés nécessitent des étapes supplémentaires, comme la validation des entrées, le contrôle d’accès, la gestion des secrets, la limitation du débit, la journalisation, la vérification des dépendances et les tests d’utilisation abusive. L’IA n’ajoute pas ces protections par défaut simplement parce qu’elle a écrit le code.
Le vibe coding encourage un développement rapide, et le développement rapide contourne souvent les phases de vérification. Lorsqu’une fonctionnalité semble fonctionner immédiatement, les équipes sont plus susceptibles de la déployer sans effectuer une revue de code approfondie, un audit de sécurité ou des tests appropriés.
Cela crée une dynamique dangereuse : plus le code arrive vite, plus il devient facile de lui faire confiance avant même que quelqu’un vérifie s’il est sûr.
Voici un exemple concret. Vous demandez à l’IA de générer un système de connexion. Elle crée un formulaire, vérifie le nom d’utilisateur et le mot de passe, puis renvoie un jeton de session.
À première vue, cela semble terminé. Mais le code peut stocker les mots de passe de manière incorrecte, ignorer l’authentification multifacteur, ne pas verrouiller les comptes après plusieurs tentatives, ou permettre aux utilisateurs de conserver des jetons de session faibles trop longtemps.
Le système de connexion fonctionne, mais l’authentification n’est pas assez robuste pour protéger de vrais comptes.
C’est le principal risque du vibe coding : cela réduit les obstacles à l’écriture du code, mais supprime aussi les moments de pause où l’on repère habituellement les erreurs de sécurité.
Quels sont les principaux risques de sécurité du vibe coding ?
Les principaux risques sont la génération de code non sécurisée, les secrets codés en dur, les dépendances vulnérables, l’absence d’authentification et d’autorisation, les autorisations excessives et un faux sentiment de sécurité.
Chacun de ces éléments fragilise une partie différente du système, qu’il s’agisse de la manière dont le code est écrit, de la gestion des accès ou du niveau de confiance que les développeurs accordent au contenu généré par l’IA.
Ce n’est pas un problème théorique. Dans le rapport 2025 de Veracode sur la sécurité du code généré par l’IA générative, seulement 55 % du code généré était sécurisé, ce qui signifie que 45 % contenaient une faille de sécurité connue.
1. Génération de code non sécurisé
L’IA peut produire du code fonctionnel, tout en laissant des failles de sécurité évidentes. Le problème n’est pas que la fonctionnalité échoue. Le problème, c’est qu’il fonctionne sans les vérifications qui empêchent les attaquants d’entrer.
L’une des vérifications les plus souvent négligées concerne la gestion correcte des entrées. Lorsque les données saisies par l’utilisateur ne sont ni validées ni assainies, elles ouvrent la voie à des attaques directes.
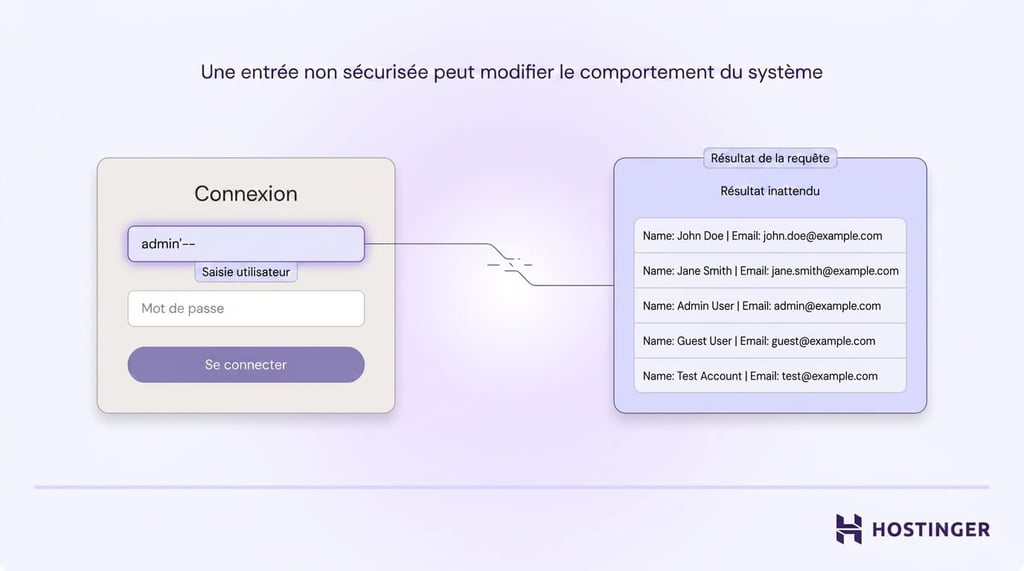
Un problème courant est l’injection SQL. Cela se produit lorsqu’une application construit directement une requête de base de données à partir des données saisies par l’utilisateur. Si l’entrée n’est pas traitée de manière sécurisée, un attaquant peut modifier la requête et extraire des données auxquelles il ne devrait jamais avoir accès.
Par exemple, un formulaire de connexion peut demander un nom d’utilisateur et un mot de passe, mais un code non sécurisé peut permettre à quelqu’un de saisir une entrée spécialement conçue qui transforme la requête en « affiche-moi tous les utilisateurs » au lieu de « vérifie ce compte ».
Un autre risque de sécurité est le cross-site scripting (XSS). Cela se produit lorsqu’une application affiche une saisie utilisateur sans l’avoir préalablement nettoyée.
L’IA génère souvent des fonctionnalités front-end comme des sections de commentaires, des formulaires ou des profils utilisateurs sans assainir correctement les données affichées. Le code fonctionne et affiche correctement le contenu, mais il ne vérifie pas si ce contenu peut être affiché en toute sécurité.
Un attaquant peut injecter un code JavaScript malveillant, que le site affiche ensuite à d’autres utilisateurs comme s’il s’agissait d’un contenu normal.
En pratique, quelqu’un pourrait utiliser une zone de commentaire pour publier un code malveillant caché. Lorsqu’un autre utilisateur ouvre la page, ce code s’exécute dans son navigateur et peut voler sa session de connexion, ce qui permet à l’attaquant d’accéder à son compte.
Un troisième problème est la référence directe non sécurisée à un objet (IDOR). Cela se produit lorsqu’une application utilise des identifiants dans les URL, sans vérifier si l’utilisateur est autorisé à accéder à ces données spécifiques.
Par exemple, un utilisateur peut ouvrir une page comme /invoice/123 pour consulter sa facture. Si l’application vérifie uniquement que l’utilisateur est connecté, sans vérifier si cette facture lui appartient, l’utilisateur peut modifier le numéro dans l’URL en /invoice/124 et consulter la facture, le profil ou les détails de commande d’un autre client.
C’est courant dans le vibe coding, car l’IA génère souvent des pages et des routes fonctionnelles, mais omet les vérifications de propriété qui devraient les accompagner. La fonctionnalité fonctionne, mais elle ne définit pas qui doit y avoir accès.
2. Secrets codés en dur dans le code généré par l’IA
L’IA peut intégrer des données sensibles directement dans le code au lieu de les stocker de manière sécurisée.
Les secrets incluent les clés API, les mots de passe de bases de données, les jetons d’accès et les identifiants privés. Ceux-ci ne doivent jamais être écrits dans les fichiers source. Ils doivent être stockés dans un espace sécurisé, comme des variables d’environnement ou des gestionnaires de secrets, où l’accès peut être contrôlé et surveillé.
Vous demandez à l’IA de générer du code qui se connecte à une API de paiement. Il renvoie un extrait de code fonctionnel avec une clé API écrite directement dans le fichier :
API_KEY = "sk-123456789abcdef"
Cette clé semble authentique, et le code fonctionne. Mais elle ne doit jamais être écrite directement dans le fichier de cette manière.
Le vrai danger, c’est l’exposition. Une fois qu’un secret se trouve dans le code, il se propage rapidement. Il peut se retrouver dans un système de contrôle de version, des dépôts partagés, des journaux, des sauvegardes ou même des captures d’écran. À partir de ce moment-là, toute personne qui le trouve peut l’utiliser.
Cet accès est immédiat. Une clé API exposée permet à quelqu’un d’utiliser votre compte, d’envoyer des requêtes et de générer des coûts comme s’il s’agissait de votre application.
Un mot de passe de base de données compromis peut donner un accès complet aux données stockées. Cela signifie que quelqu’un peut lire, copier ou supprimer l’intégralité de votre base de données.
Même une erreur de courte durée, comme publier du code dans un dépôt public pendant quelques minutes, suffit pour que des bots automatisés détectent et récupèrent ces secrets. Une fois que cela se produit, des attaquants peuvent accéder à votre système presque immédiatement, souvent avant même que vous ne remarquiez l’exposition.
3. Dépendances vulnérables ou obsolètes
Les dépendances vulnérables ou obsolètes représentent un risque, car l’IA peut suggérer des packages non sécurisés, dépassés ou inexistants.
Les applications modernes s’appuient sur des bibliothèques tierces pour des tâches telles que les paiements, l’authentification et la gestion des fichiers. Cela fait gagner du temps, mais cela signifie aussi que vous faites confiance à du code écrit par quelqu’un d’autre.
Si cette bibliothèque présente une vulnérabilité connue, votre application en hérite. Cela signifie que des attaquants peuvent exploiter cette faille pour accéder à des données, perturber des fonctionnalités ou exécuter des actions malveillantes au sein de votre système.
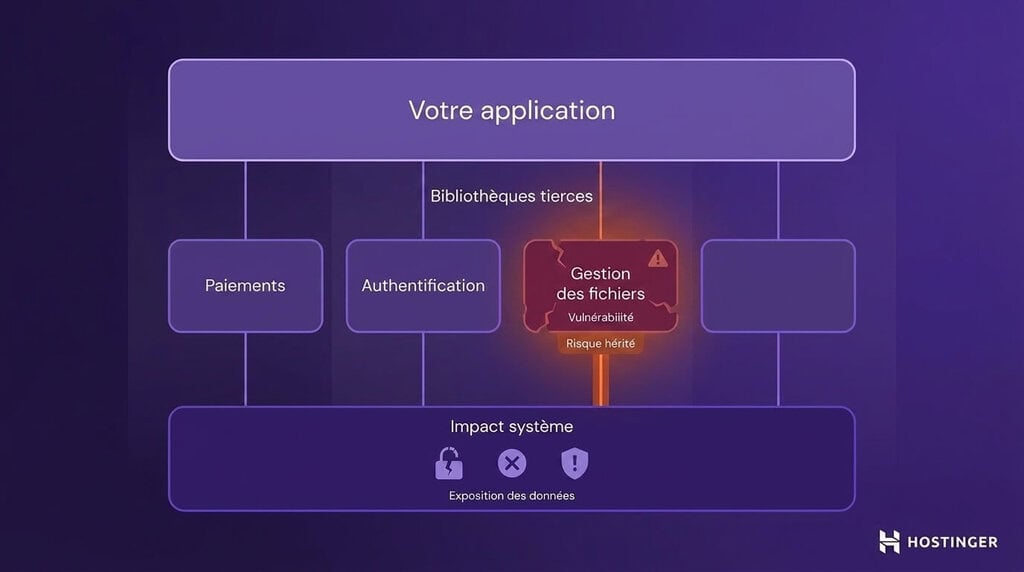
Cela devient encore plus risqué en vibe coding, car l’IA suggère ce qui est probable, pas ce qui est sûr. Elle peut recommander des bibliothèques obsolètes présentant des problèmes connus, voire générer des noms de packages qui n’existent pas.
Cela crée un risque lié à la chaîne d’approvisionnement logicielle. Votre propre code peut être correct, mais le paquet que vous installez peut malgré tout exposer votre système. Une dépendance vulnérable peut offrir aux attaquants un point d’entrée en raison de ses propres failles.
Une bibliothèque frauduleuse peut aller plus loin en volant des données sensibles, en modifiant des fichiers ou en exécutant du code malveillant lors de l’installation.
Par exemple, vous demandez à l’IA un package pour gérer les téléversements de fichiers. Elle suggère une bibliothèque qui semble légitime, alors vous l’installez sans la vérifier.
La fonctionnalité fonctionne, vous passez donc à la suite. Mais le package est obsolète et présente une vulnérabilité connue, ou il s’agit d’un package malveillant portant un nom similaire. Les attaquants peuvent désormais exploiter cette dépendance pour accéder à votre système ou à vos données.
4. Authentification et autorisation absentes
L’absence d’authentification et d’autorisation représente un risque sérieux, car le système ne vérifie pas correctement l’identité de l’utilisateur ni ce qu’il est autorisé à faire.
L’authentification et l’autorisation répondent à deux problèmes différents. L’authentification confirme l’identité, c’est-à-dire que l’utilisateur est bien celui qu’il prétend être. L’autorisation contrôle l’accès, c’est-à-dire ce que cet utilisateur est autorisé à voir ou à modifier. Si l’une de ces étapes manque, le système expose des données ou des actions à des personnes non autorisées.
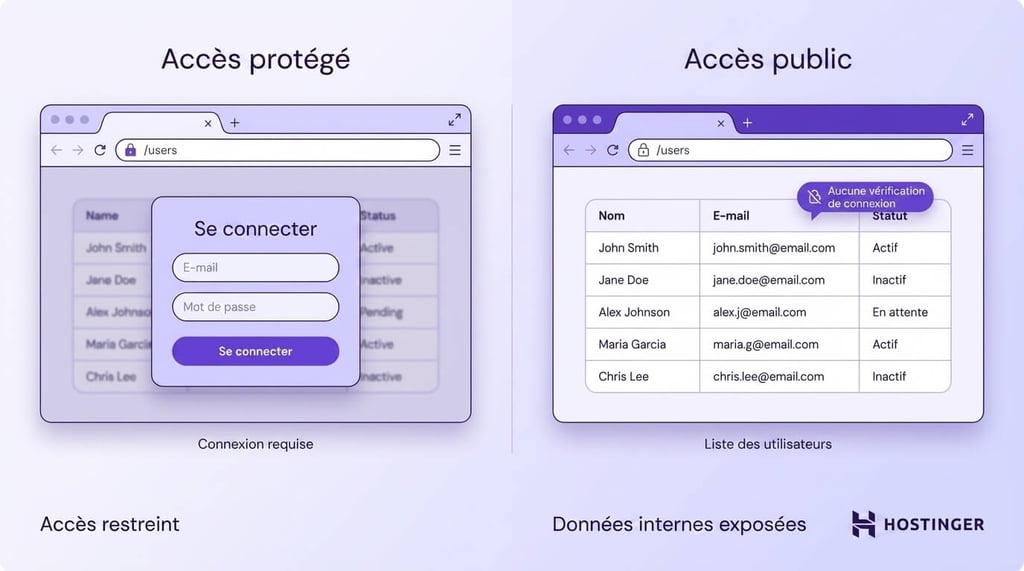
Une défaillance fréquente concerne les endpoints ouverts. Un endpoint est simplement une URL qui affiche des données ou exécute une action. Si cette URL ne nécessite pas de connexion, n’importe qui peut y accéder.
Par exemple, imaginez une page comme /users qui affiche une liste de clients. S’il n’y a pas de vérification de connexion, toute personne qui trouve ce lien peut l’ouvrir. Cela signifie que des données privées d’utilisateurs sont visibles publiquement, alors qu’elles étaient censées rester internes.
Un autre problème fréquent est que des vérifications de sécurité sont appliquées à certains endroits, mais absentes ailleurs.
Par exemple, votre tableau de bord peut exiger que les utilisateurs se connectent. Cette partie fonctionne correctement. Mais en arrière-plan, l’application peut aussi avoir une route API comme /api/export-data qui renvoie les mêmes données.
Si cette route d’API ne vérifie pas si l’utilisateur est connecté, n’importe qui peut y accéder directement en visitant l’URL ou en envoyant une requête. Ainsi, même si l’interface semble sécurisée, les données restent exposées.
Un autre problème consiste à s’appuyer sur l’interface pour appliquer les autorisations.
Par exemple, vous pouvez masquer le bouton « Supprimer le compte » pour les utilisateurs standards. Cela donne l’impression qu’ils ne peuvent pas supprimer de comptes.
Mais si le backend ne vérifie pas les autorisations, un utilisateur peut quand même envoyer une requête manuellement à l’aide des outils de développement du navigateur ou d’un outil d’API et déclencher la même action.
En d’autres termes, masquer quelque chose dans l’interface utilisateur ne le protège pas. Le serveur doit appliquer cette règle.
C’est fréquent dans le vibe coding, car l’IA génère souvent des interfaces et des routes fonctionnelles sans appliquer de vérifications cohérentes sur l’ensemble du backend. La fonctionnalité fonctionne comme prévu dans l’interface utilisateur, mais le système ne contrôle pas entièrement qui peut accéder à ces actions ou les déclencher.
5. Autorisations excessives des agents IA
Des autorisations excessives créent un risque, car les agents IA ont accès à davantage de parties de votre système qu’ils n’en ont réellement besoin.
Les agents IA se connectent souvent à des systèmes réels, comme des fichiers, des bases de données ou des services cloud. Si l’accès est trop large, ils peuvent aller bien au-delà de la tâche qui leur était destinée.
Un agent conçu pour lire les tickets d’assistance peut aussi être capable de modifier les données des utilisateurs. Un agent conçu pour résumer des journaux peut aussi être autorisé à supprimer des fichiers ou à modifier des paramètres.
En pratique, cela signifie qu’une seule erreur peut se transformer en incident majeur. L’agent pourrait exposer des données sensibles, écraser des fichiers importants ou déclencher des modifications dans des systèmes de production sans que personne ne s’en aperçoive immédiatement.
Imaginez un agent IA qui aide à organiser les fichiers dans un espace de stockage partagé de l’entreprise. Il a seulement besoin d’accéder à un seul dossier. Au lieu de cela, il a accès à l’ensemble du disque. La tâche fonctionne, mais désormais, un mauvais prompt ou une petite erreur peut déplacer, supprimer ou exposer des fichiers de la finance, du service juridique ou des ressources humaines.
6. Faux sentiment de sécurité face aux réponses de l’IA
Un faux sentiment de sécurité est un risque majeur du vibe coding, car le code généré par l’IA peut sembler complet même lorsqu’il n’a pas été correctement vérifié.
Le code s’exécute, la page se charge et la fonctionnalité semble fonctionner. Cela donne confiance trop tôt. Cela semble terminé, donc le code est livré sans examen plus approfondi. Mais un code qui fonctionne n’est pas forcément un code sécurisé.
En pratique, cela signifie que des vérifications importantes sont ignorées. La saisie n’est pas validée. Les permissions ne sont pas appliquées. Les actions sensibles ne sont pas protégées.
Par exemple, vous demandez à l’IA de créer une fonctionnalité de « mot de passe oublié ». Elle crée un formulaire dans lequel les utilisateurs saisissent leur e-mail, puis leur envoie un lien de réinitialisation.
Le lien fonctionne. Vous cliquez dessus, définissez un nouveau mot de passe, et tout semble correct.
Mais le lien n’a pas de date d’expiration et n’est pas associé au bon utilisateur. Si un attaquant obtient l’accès à ce lien, il peut réinitialiser le mot de passe et prendre le contrôle du compte.
Pourquoi les processus de sécurité traditionnels échouent-ils avec le vibe coding ?
Lorsque l’on compare le vibe coding au codage traditionnel, la principale différence réside dans la rapidité avec laquelle le code passe de l’idée à la production, en sautant souvent les étapes de révision où les failles de sécurité sont détectées.
Par exemple, imaginez que vous créez une fonctionnalité de téléversement de fichiers permettant aux utilisateurs de mettre en ligne leur photo de profil. La fonctionnalité fonctionne : les utilisateurs téléversent un fichier, et celui-ci apparaît sur la page.
Mais personne ne vérifie quels types de fichiers sont autorisés.
Un attaquant peut téléverser un fichier malveillant, comme un script déguisé en image. Lorsque le système traite ou sert ce fichier, il peut exécuter du code malveillant ou exposer l’application.
Dans un flux de travail traditionnel, un relecteur le repérerait dès le début. Il appliquerait des restrictions sur les types de fichiers, validerait les fichiers téléversés et bloquerait les fichiers exécutables avant leur mise en ligne.
Dans un flux de travail de vibe coding, cette étape de vérification est souvent ignorée, car la fonctionnalité semble déjà terminée.
Comment sécuriser vos flux de travail de vibe coding ?
Pour sécuriser votre flux de travail lorsque vous utilisez l’IA, suivez ces étapes dans votre processus de développement :
- Étape 1 : auditez votre code généré par l’IA. Vérifiez chaque résultat avant de l’utiliser et testez sa gestion des entrées, des autorisations et des erreurs.
- Étape 2 : gardez les secrets en dehors de votre code. Stockez les clés d’API et les jetons dans des variables d’environnement ou un gestionnaire de secrets.
- Étape 3 : configurez l’authentification et l’autorisation dès le départ. Exigez une connexion et appliquez un contrôle d’accès à chaque requête.
- Étape 4 : validez et assainissez toutes les entrées utilisateur. Acceptez uniquement les formats attendus et traitez les données de manière sécurisée avant de les utiliser.
- Étape 5 : suivez régulièrement les dépendances. Analysez les vulnérabilités et gardez les packages à jour.
- Étape 6 : limitez ce à quoi les agents IA peuvent accéder. Accordez uniquement les accès nécessaires et limitez tout le reste.
1. Vérifiez tout le code généré par l’IA
Vérifiez chaque extrait de code généré par l’IA avant de l’utiliser dans votre base de code.
Commencez par tester la manière dont le code gère les entrées utilisateur. Saisissez des données invalides directement dans l’interface utilisateur ou l’API :
- Saisissez des lettres dans les champs numériques
- Envoyez des formulaires vides
- Collez des scripts comme <script>alert(1)</script>
Le système doit rejeter ces entrées avec des erreurs claires. S’il les accepte ou que cela casse, la validation est absente.
Ensuite, vérifiez le contrôle d’accès en modifiant les requêtes. Connectez-vous en tant qu’utilisateur, puis :
- Modifiez les identifiants dans les URL (par exemple, /orders/123 → /orders/124)
- Répétez les requêtes API avec différentes données utilisateur
Si vous pouvez accéder aux données d’un autre utilisateur, cela signifie qu’une autorisation manque.
Analysez le code pour détecter les secrets. Recherchez dans votre projet des motifs comme :
- API_KEY =
- password =
Supprimez toutes les valeurs codées en dur et placez-les dans des variables d’environnement.
Vérifiez les dépendances introduites par l’IA. Consultez le fichier package.json ou les fichiers requirements et :
- Recherchez le nom du package sur Google ou GitHub
- Vérifiez la date de la dernière mise à jour et le nombre d’utilisateurs
- Lancez une analyse avec des outils comme Snyk ou npm audit
N’installez pas de packages dont vous ne pouvez pas vérifier l’origine.
Testez directement les cas d’échec. Cassez volontairement la fonctionnalité :
- Envoyez des requêtes incomplètes
- Supprimez les champs obligatoires
- Simulez l’expiration des sessions
Le système doit renvoyer des erreurs, sans planter ni exposer de données.
Enfin, comparez le code avec les modèles existants dans votre projet. Vérifiez comment des fonctionnalités similaires gèrent la validation, les autorisations et l’accès aux données, et assurez-vous que le nouveau code suit la même structure.
2. Évitez les secrets codés en dur
Ne stockez jamais de secrets directement dans votre code.
Ne codez pas les secrets en dur. Stockez les clés d’API, les mots de passe et les jetons en dehors de votre code.
Définissez-les dans votre environnement :
API_KEY=abc123
Accédez-y ensuite dans votre code :
const apiKey = process.env.API_KEY;
Cela permet de ne pas stocker de secrets dans votre base de code.
Avant chaque commit, vérifiez qu’il n’y a pas de fuite à l’aide d’outils comme git-secrets ou Gitleaks. Ces outils analysent votre code et bloquent les commits qui contiennent des données sensibles.
Stockez les identifiants sensibles dans un gestionnaire de secrets pour les systèmes de production. Utilisez des outils comme AWS Secrets Manager, HashiCorp Vault ou Doppler pour stocker et accéder aux secrets en toute sécurité au moment de l’exécution, au lieu de les conserver dans des fichiers locaux.
Limitez l’accès à chaque secret. Seuls les services ou les parties de votre système qui ont besoin d’un secret doivent pouvoir y accéder.
Renouvelez régulièrement les secrets. Remplacez les clés API et les mots de passe à intervalles réguliers ou immédiatement après toute suspicion de compromission.
Enfin, vérifiez qu’aucun secret n’est exposé. Envoyez le code vers un dépôt privé et vérifiez qu’aucun secret n’apparaît dans :
- Historique des commits
- Journaux
- Messages d’erreur
Si un secret apparaît n’importe où dans votre base de code ou vos journaux, considérez-le comme compromis et remplacez-le immédiatement.
3. Mettez en place l’authentification et l’autorisation dès le départ
Configurez l’authentification et l’autorisation dès le début de votre projet.
Ajoutez des vérifications d’authentification à toutes les routes non publiques. Dans votre backend, protégez les routes à l’aide d’un middleware ou de gardes (par exemple, un middleware JWT ou des vérifications de session). Chaque requête doit vérifier que l’utilisateur est connecté avant de renvoyer des données.
Testez cela en ouvrant les routes dans une fenêtre de navigation privée ou en utilisant un outil comme Postman sans vous connecter. La requête doit renvoyer une erreur telle que 401 Unauthorized.
Ensuite, appliquez l’autorisation à chaque requête. Après avoir confirmé que l’utilisateur est connecté, vérifiez à quoi il est autorisé à accéder. Dans votre logique back-end, comparez l’identifiant de l’utilisateur authentifié avec celui du propriétaire de la ressource.
Par exemple, lorsque vous traitez une requête comme /orders/123, récupérez la commande et vérifiez :
if (order.userId !== currentUser.id) {
return res.status(403).send("Forbidden");
}Testez cela en vous connectant avec un compte utilisateur, puis en essayant d’accéder aux données d’un autre utilisateur en modifiant les ID dans l’URL ou la requête API. Le système doit renvoyer 403 Forbidden.
Ne faites pas confiance aux ID fournis par le client. Validez-les toujours sur le serveur. Même si le frontend masque certaines données, partez du principe que les utilisateurs peuvent modifier les requêtes manuellement.
Appliquez la même logique de contrôle d’accès dans toute l’application. Utilisez des middlewares, des helpers ou des politiques partagés au lieu d’écrire des vérifications personnalisées pour chaque endpoint. Cela évite les failles où certaines routes restent non protégées.
Testez directement les scénarios non autorisés. Utilisez des outils comme Postman ou les outils de développement du navigateur pour :
- Supprimer les jetons d’authentification
- Modifier le corps des requêtes
- Relancez les requêtes avec des données utilisateur différentes
Toute requête non autorisée doit être bloquée.
Enfin, veillez à inclure des vérifications d’authentification et d’autorisation lors du développement de chaque nouvelle fonctionnalité. Ne les ajoutez pas plus tard. Lorsque vous créez un nouvel endpoint, commencez par ajouter la protection, puis implémentez la logique de la fonctionnalité.
4. Validez et assainissez les entrées utilisateur
Traitez toutes les entrées utilisateur comme non fiables et validez-les avant de les utiliser où que ce soit dans votre système.
Commencez par ajouter des règles de validation dans votre backend. Utilisez une bibliothèque de validation comme Joi, Zod ou les validateurs intégrés du framework pour définir ce que chaque champ doit accepter.
Par exemple :
const schema = z.object({
email: z.string().email(),
age: z.number().int().min(0)
});Exécutez cette validation avant de traiter la demande. Si l’entrée ne correspond pas au schéma, renvoyez une erreur et arrêtez l’exécution :
if (!schema.safeParse(req.body).success) {
return res.status(400).send("Invalid input");
}N’essayez pas de corriger une entrée invalide. Rejetez-la et demandez à l’utilisateur d’envoyer des données correctes.
Ensuite, assainissez les données avant de les utiliser dans des requêtes ou de les afficher sur une page. Utilisez des protections intégrées, comme des moteurs de templates qui échappent le HTML par défaut, ainsi que des bibliothèques comme DOMPurify pour le contenu généré par les utilisateurs.
Pour les requêtes de base de données, utilisez toujours des requêtes paramétrées plutôt que la concaténation de chaînes de caractères :
// safe
db.query("SELECT * FROM users WHERE email = ?", [email]);
// unsafe
db.query(`SELECT * FROM users WHERE email = '${email}'`);Testez directement la gestion de vos entrées. Essayez :
- Saisir des scripts comme <script>alert(1)</script>
- Soumettre des chaînes longues ou inattendues
- Envoyer des formats non valides via des outils d’API comme Postman
Le système doit rejeter l’entrée ou l’échapper de manière sécurisée. Il ne doit jamais exécuter de code ni renvoyer de données inattendues.
Si votre application permet de téléverser des fichiers, limitez les types et la taille des fichiers côté serveur. Ne vous fiez pas aux vérifications côté client.
Enfin, appliquez les mêmes règles de validation et d’assainissement à chaque source d’entrée. Cela inclut les formulaires, les requêtes API, les paramètres d’URL et les téléversements de fichiers. Ne partez pas du principe qu’une entrée est sûre simplement parce qu’elle provient de votre interface front-end.
5. Surveillez les dépendances en continu
Recensez chaque dépendance de votre projet et vérifiez régulièrement si elle présente des vulnérabilités connues.
Commencez par exécuter une analyse des dépendances en local. Utilisez des outils intégrés comme :
npm audit
ou
pip-audit
Cela affiche les vulnérabilités connues dans vos dépendances actuelles.
Ensuite, automatisez cela dans votre flux de travail. Ajoutez un scanner de dépendances comme Dependabot, Snyk ou Aikido à votre dépôt. Par exemple, activez Dependabot dans GitHub afin qu’il analyse automatiquement vos dépendances et ouvre des pull requests avec des correctifs de sécurité.
Cela évite de devoir effectuer la vérification manuellement.
Avant d’installer un package, vérifiez-le manuellement :
- Recherchez le nom du package sur npm ou PyPI
- Vérifiez la date de la dernière mise à jour
- Vérifiez le nombre de téléchargements ou d’étoiles sur GitHub
Si le paquet ne présente aucune activité ou semble suspect, ne l’installez pas.
Verrouillez les versions de vos dépendances pour éviter les changements inattendus. Utilisez des fichiers de verrouillage comme :
- package-lock.json
- yarn.lock
- requirements.txt
Évitez les versions trop approximatives comme :
"library": "^1.0.0"
Utilisez plutôt des versions fixes :
"library": "1.0.0"
Mettez régulièrement à jour les dépendances. Lorsqu’un outil signale une vulnérabilité :
- Exécutez la mise à jour (npm update ou une commande similaire)
- Vérifiez ce qui a changé
- Testez la fonctionnalité concernée
Ne retardez pas les mises à jour, car les vulnérabilités connues sont activement exploitées.
Supprimez les dépendances inutilisées en vérifiant les fichiers de votre projet. Si un package n’est importé ni utilisé nulle part, supprimez-le et exécutez :
npm uninstall package-name
Cela réduit les risques inutiles.
Après chaque mise à jour, testez la fonctionnalité qui dépend de ce package. Par exemple :
- mettre à jour la bibliothèque de téléversement → tester le téléversement de fichiers
- mettre à jour la bibliothèque d’authentification → tester le flux de connexion
Enfin, vérifiez que tout fonctionne et qu’il ne reste aucune vulnérabilité :
npm audit
L’analyse ne doit détecter aucun problème critique.
6. Limitez les autorisations des agents IA
Accordez à chaque agent IA uniquement les accès dont il a besoin pour accomplir sa tâche.
Commencez par définir concrètement le périmètre de l’agent. Indiquez précisément ce qu’il doit faire, par exemple : « lire les tickets d’assistance depuis l’API /tickets » ou « résumer les fichiers du dossier /reports ». Ne poursuivez pas tant que ce périmètre n’est pas clair.
Créez des identifiants à accès restreint au lieu d’utiliser des clés avec accès complet. Lors de la génération d’une clé API ou d’un jeton, configurez les autorisations pour n’autoriser que des actions spécifiques. Par exemple :
- Autoriser – GET /tickets
- Bloquer – requêtes POST, DELETE ou actions d’administration
Évitez d’utiliser les identifiants root, admin ou ceux disposant d’un accès complet.
Limitez l’accès à des ressources spécifiques. Dans votre système ou chez votre fournisseur cloud :
- Accordez l’accès à un seul dossier au lieu de l’ensemble du bucket de stockage
- Autorisez une seule table de base de données au lieu de toute la base de données
- Restreignez les API à des endpoints spécifiques
Utilisez des rôles IAM ou des politiques d’autorisation pour appliquer cette règle.
Commencez par un accès en lecture seule. Attribuez des autorisations qui permettent uniquement de lire les données. Testez ensuite l’agent. Ajoutez uniquement les autorisations d’écriture ou de suppression si la tâche échoue sans elles.
Exécutez d’abord l’agent dans un environnement de test. Connectez-le aux données de préproduction plutôt qu’à celles de production. Vérifiez son fonctionnement avant de lui donner accès à de vrais utilisateurs ou à des systèmes réels.
Testez les permissions en essayant de les contourner. Utilisez l’agent ou l’API manuellement pour :
- Accéder à un autre dossier
- Modifier des données alors qu’il devrait seulement les lire
- Appeler des endpoints en dehors de son périmètre
Chaque tentative doit échouer avec une réponse « accès refusé » ou 403 Forbidden.
Activez la journalisation de toutes les actions de l’agent. Enregistrez :
- Les fichiers auxquels il accède
- Les API qu’il appelle
- Les actions qu’il effectue
Consultez les journaux après avoir exécuté l’agent. Vérifiez qu’il exécute uniquement les actions que vous avez définies précédemment.
Si l’agent peut faire plus que prévu, réduisez ses autorisations et testez de nouveau.
Quels outils permettent de sécuriser le code généré par l’IA ?
Les outils de vibe coding vous aident à créer des applications rapidement, mais ils ne les sécurisent pas par défaut. Pour protéger le code généré par l’IA, vous avez besoin d’un ensemble d’outils distinct répartis en trois catégories : l’analyse du code, l’analyse des dépendances et la protection à l’exécution.
Des outils comme Aikido, Snyk et CodeAnt couvrent différentes parties de ce flux de travail, tandis que l’AI Controls Matrix de la CSA aide à définir les contrôles à appliquer.
Analyse de code (SAST)
Les tests de sécurité statique des applications, ou SAST, analysent le code source à la recherche de schémas risqués avant la mise en production.
Cela permet de détecter les problèmes dans le code généré par l’IA, comme une gestion non sécurisée des entrées, des secrets exposés ou une logique faible dans les pull requests et les IDE. Les outils de ce groupe incluent Aikido, CodeAnt et Snyk Code.
Analyse des dépendances
Les scanners de dépendances analysent les packages tiers dont votre code dépend et signalent les vulnérabilités connues. C’est important en vibe coding, car l’IA peut suggérer des bibliothèques obsolètes ou même des noms de packages qui doivent être vérifiés avant l’installation.
Snyk et Aikido analysent tous deux les dépendances open source, et CodeAnt inclut également l’analyse de composition logicielle dans sa plateforme.
Protection à l’exécution
Certains problèmes n’apparaissent que sous un trafic réel, pas lors de la révision du code. La protection à l’exécution surveille ce qui se passe après le déploiement du code et aide à détecter ou bloquer les attaques en cours.
Aikido est un exemple de plateforme qui va de l’analyse du code et des dépendances à la détection et au blocage des menaces en temps réel.
Où se situe la CSA
La CSA est différente des outils ci-dessus. Ce n’est pas un outil d’analyse. L’AI Controls Matrix de la Cloud Security Alliance est un cadre de contrôle neutre vis-à-vis des fournisseurs pour sécuriser les systèmes d’IA. Elle est donc particulièrement utile pour définir votre processus, examiner les exigences et établir une base de référence de sécurité autour du code généré par l’IA.
Checklist de sécurité pour le vibe coding
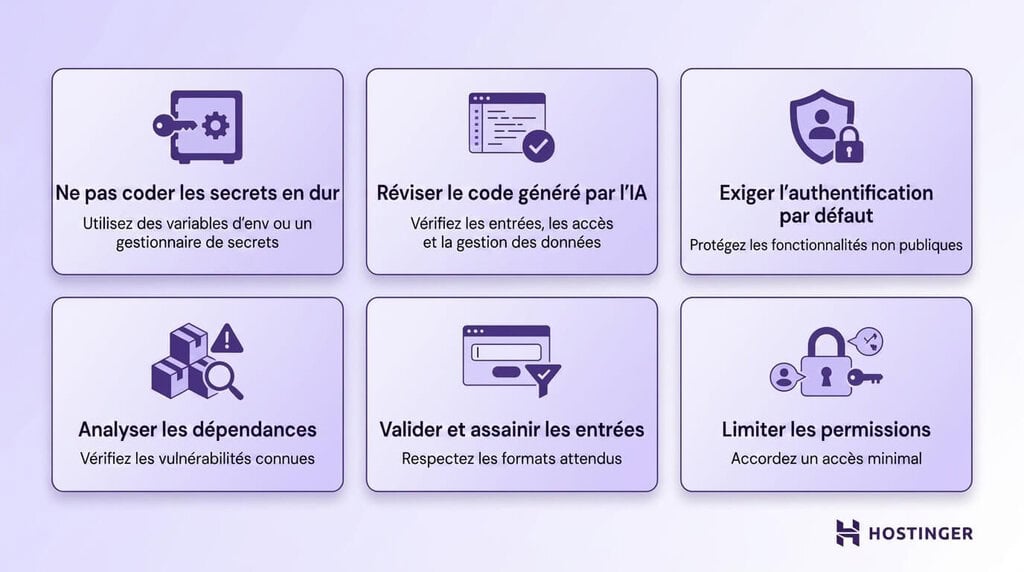
Utilisez cette checklist pour repérer rapidement les risques les plus courants avant que le code ne soit mis en production.
- Ne codez jamais les secrets en dur : gardez les clés d’API, mots de passe et jetons hors de votre code en les stockant dans des variables d’environnement ou dans un gestionnaire de secrets.
- Vérifiez tout le code généré par l’IA : considérez le résultat produit par l’IA comme un brouillon et contrôlez la manière dont il gère les entrées, le contrôle d’accès et les données sensibles avant de l’utiliser.
- Exigez l’authentification par défaut : imposez la connexion comme norme pour toute fonctionnalité non publique, afin d’éviter que des endpoints ne restent ouverts par accident.
- Analysez les dépendances pour détecter les vulnérabilités connues : vérifiez régulièrement les packages tiers afin d’éviter d’intégrer à votre application du code non sécurisé ou obsolète.
- Validez et assainissez les entrées utilisateur : assurez-vous que toutes les données saisies correspondent aux formats attendus et qu’elles ne peuvent pas servir à injecter du code malveillant.
- Limitez les autorisations des agents et outils d’IA : accordez uniquement l’accès minimum nécessaire afin de limiter les conséquences d’éventuelles erreurs ou d’un usage abusif.
Ce qu’il faut savoir avant d’utiliser le vibe coding en environnement de production
Le vibe coding vous fait gagner du temps, mais il augmente aussi les risques de sécurité.
L’IA vous permet de générer rapidement des fonctionnalités opérationnelles, mais un code généré plus vite n’est pas forcément plus sûr. Quand davantage de code est produit en moins de temps, il devient plus facile de négliger les revues et de passer à côté de problèmes de sécurité.
Cela change votre façon d’aborder le développement. Ne considérez pas le code généré par l’IA comme fiable. Considérez-le comme une version préliminaire qui doit être révisée, testée et validée avant sa publication.
Par exemple, l’IA peut générer un tableau de bord fonctionnel en quelques minutes. Les pages se chargent et les données s’affichent, mais sans contrôles d’accès appropriés, les utilisateurs peuvent voir des informations auxquelles ils ne devraient pas avoir accès. La fonctionnalité fonctionne, mais elle n’est pas sécurisée.
Pour utiliser le vibe coding en toute sécurité en production, appliquez par défaut les bonnes pratiques de sécurité des applications web. Exigez une authentification, validez les entrées, protégez les secrets, vérifiez les dépendances et limitez les autorisations.
La sécurité doit aussi faire partie intégrante de votre flux de travail. Ne vous reposez pas sur des vérifications manuelles à la fin. Ajoutez des analyses automatisées, imposez des revues et testez les cas limites dans le cadre du développement.
La plateforme que vous utilisez influence aussi le niveau de sécurité avec lequel vous pouvez créer et lancer des applications avec l’IA. Par exemple, l’outil de vibe coding Hostinger Horizons réunit dans un seul environnement la création d’applications à partir de prompts, l’hébergement intégré et la publication en un clic, ce qui réduit le travail de configuration souvent à l’origine d’erreurs lors du déploiement.
Il inclut également des protections au niveau de l’infrastructure, comme un pare-feu, l’analyse des logiciels malveillants et une protection contre les attaques DDoS, ainsi que des fonctionnalités comme l’historique des versions du projet et une prise en charge backend intégrée pour les comptes, les connexions et le stockage des données.
Cela améliore la rapidité de lancement et la sécurité opérationnelle, mais ne remplace pas la sécurité au niveau de l’application. Vous devez toujours vérifier la logique générée, valider les entrées, appliquer l’authentification et l’autorisation, protéger les secrets et tester le comportement de l’application avant de la publier.

Tout le contenu des tutoriels de ce site est soumis aux normes éditoriales et aux valeurs rigoureuses de Hostinger.

Faradilla, plus connue sous le nom de Ninda, possède 10 ans d’expérience en tant que linguiste et 5 ans en tant que spécialiste du marketing de contenu chez Hostinger. Elle aime suivre les tendances technologiques et aider les autres à résoudre leurs problèmes. Pendant son temps libre, Ninda aime apprendre de nouvelles langues et s’intéresser aux sciences de la vie, ainsi que regarder des vidéos d’animaux. Pour en savoir plus sur Ninda, retrouvez-la sur LinkedIn.


Commentaires
0 responses