Was ist Vibe Coding Security? Risiken und Best Practices
Jun 24, 2026
/
Eveline B.
/
17 Min. Lesezeit
Vibe Coding Security ist die Praxis, KI-generierte Anwendungen sicher zu halten, indem Code, Abhängigkeiten, Zugriffskontrollen und Entwicklungs-Workflows überprüft werden.
Vibe-Coding selbst bedeutet, mit KI Code zu erzeugen, indem Sie natürliche Sprachbefehle verwenden, anstatt alles manuell zu schreiben. Das beschleunigt die Entwicklung, bringt jedoch auch Risiken mit sich.
KI kann Funktionen erzeugen, die oberflächlich betrachtet einwandfrei wirken, aber dennoch unsichere Standardeinstellungen, offengelegte Geheimnisse, schwache Authentifizierung oder verwundbare Abhängigkeiten enthalten.
Bei der Entwicklung sicherer, KI-gesteuerter Anwendungen kommt es darauf an, diese Lücken frühzeitig zu erkennen: Sicherheitsprüfungen müssen von Anfang an durchgeführt werden, um den Code auf seine Funktion zu prüfen, und die richtigen Werkzeuge müssen eingesetzt werden, um Probleme zu erkennen, bevor sie in die Produktion gelangen.
Wie erzeugt Vibe Coding Sicherheitsrisiken?
Vibe Coding schafft Sicherheitsrisiken, weil KI Code ohne Sicherheitsprüfung generiert.
Große Sprachmodelle (LLMs) verstehen Sicherheit nicht so, wie es ein Entwickler oder ein Sicherheitsprüfer tut.
Diese Modelle sagen anhand der Trainingsdaten das wahrscheinlich nächste Muster voraus. Das hilft ihnen, Code schnell zu erstellen, aber es hilft ihnen nicht dabei zu beurteilen, ob der Code sicher ist. Ein Modell kann etwas erzeugen, das sauber aussieht, in einer Demo funktioniert und dennoch bei grundlegenden Sicherheitskontrollen versagt.
Das erste Problem ist, dass LLMs Muster vorhersagen, aber keine sichere Logik. Sie übernehmen gängige Code-Muster aus Beispielen, die sie gesehen haben, aber viele dieser Beispiele sind unvollständig, veraltet oder unsicher.
Ein Anmeldeablauf, ein Zahlungsformular, eine Dateiupload-Funktion oder ein API-Endpunkt können auf den ersten Blick korrekt wirken und trotzdem Prüfungen entbehren, die reale Nutzer und Daten schützen.
Das zweite Problem ist ein Mangel an Kontextbewusstsein. Sichere Software hängt vom gesamten sie umgebenden System ab: davon, wie sich Nutzer anmelden, auf welche Daten sie zugreifen können, wo Geheimnisse gespeichert werden, welche Rollen es gibt und was passieren soll, wenn etwas fehlschlägt.
Ein KI-Modell sieht in der Regel nur den Prompt und den kurzen Code-Ausschnitt, den Sie ihm gegeben haben. Es erfasst weder Ihre komplette Anwendung noch Ihr Bedrohungsmodell oder Ihre Compliance-Anforderungen zuverlässig.
Dadurch kann es Code hinzufügen, der mit dem restlichen System in Konflikt gerät oder eine Lücke zwischen Komponenten schafft, die für sich genommen sicher erschienen.
Das dritte Problem besteht darin, dass es während der Generierung keine integrierten Sicherheitsprüfungen gibt. Ein Modell kann Code erzeugen, aber das Erzeugen ist nicht dasselbe wie das Prüfen, Testen oder Validieren.
Sichere Software erfordert zusätzliche Maßnahmen wie Eingabevalidierung, Zugriffskontrolle, sicheren Umgang mit Geheimnissen, Begrenzung von Aufrufraten, Protokollierung, Überprüfung von Abhängigkeiten und Tests zur Missbrauchserkennung. KI fügt diese Schutzmechanismen nicht automatisch hinzu, nur weil sie den Code erstellt hat.
Vibe Coding fördert eine schnelle Entwicklung, und schnelle Entwicklung umgeht häufig Überprüfungen. Wenn eine Funktion auf den ersten Blick zu funktionieren scheint, neigen Teams eher dazu, sie ohne sorgfältige Code- und Sicherheitsprüfung oder angemessene Tests auszuliefern.
So entsteht ein gefährliches Muster: Je schneller Code geliefert wird, desto leichter neigen wir dazu, ihm zu vertrauen – noch bevor irgendjemand überprüft hat, ob er sicher ist.
Hier ist ein solches Szenario. Sie lassen die KI ein Anmeldesystem erstellen. Es generiert ein Formular, überprüft den Benutzernamen und das Passwort und liefert ein Sitzungstoken.
Auf den ersten Blick wirkt alles erledigt. Der Code könnte Passwörter jedoch falsch speichern, die Multi-Faktor-Authentifizierung überspringen, Konten nach wiederholten Versuchen nicht sperren oder zulassen, dass Benutzer zu lange schwache Sitzungstokens behalten.
Das Anmeldesystem funktioniert, aber die Authentifizierung ist nicht stark genug, um echte Konten zu schützen.
Das ist das zentrale Risiko beim „Vibe Coding“: Es nimmt Reibung aus dem Programmierprozess, beseitigt aber zugleich die Leerläufe, in denen Menschen normalerweise die Sicherheitsfehler bemerken.
Was sind die wichtigsten Sicherheitsrisiken beim Vibe Coding?
Die wichtigsten Risiken sind unsichere Codegenerierung, in den Quellcode geschriebene sensible Anmeldeinformationen, verwundbare Abhängigkeiten, fehlende Authentifizierung und Autorisierung, übermäßige Berechtigungen sowie ein trügerisches Sicherheitsgefühl.
Jeder dieser Punkte schwächt einen anderen Teil des Systems – von der Art und Weise, wie Code geschrieben wird, über die Kontrolle des Zugriffs bis hin dazu, wie viel Vertrauen Entwickler in KI-generierte Ergebnisse setzen.
Dies ist kein theoretisches Problem. Im Veracode GenAI Code Security Report 2025 waren nur 55 % des generierten Codes sicher, was bedeutet, dass 45 % eine bekannte Sicherheitslücke enthielten.
1. Unsichere Codegenerierung
KI kann Code erzeugen, der funktioniert, aber dennoch offensichtliche Sicherheitslücken aufweist. Das Problem ist nicht, dass die Funktion fehlschlägt. Das Problem besteht darin, dass alles funktioniert, ohne dass Angreifer abgewehrt werden.
Eine der häufigsten fehlenden Prüfungen betrifft die korrekte Verarbeitung von Eingaben. Wenn Benutzereingaben nicht überprüft oder bereinigt werden, entstehen direkte Angriffswege.
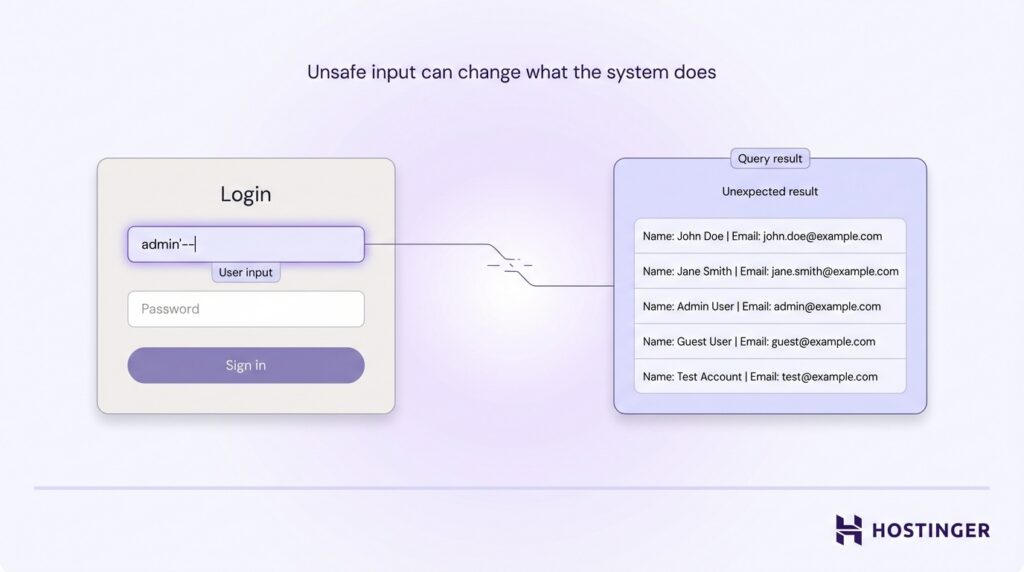
Ein häufiges Problem ist SQL-Injection. Hierbei erstellt eine App eine Datenbankabfrage direkt aus Benutzereingaben. Wenn die Eingabe nicht sicher verarbeitet wird, kann ein Angreifer die Abfrage verändern und Daten auslesen, die er niemals sehen dürfte.
Ein Anmeldeformular fragt zum Beispiel nach einem Benutzernamen und einem Passwort, aber unsicherer Code könnte zulassen, dass jemand eine speziell gestaltete Eingabe macht, die die Abfrage in „Zeig mir alle Benutzer“ statt in „Prüfe dieses eine Konto“ verwandelt.
Ein weiteres Sicherheitsrisiko ist Cross-Site Scripting (XSS). Es tritt auf, wenn eine App Benutzereingaben anzeigt, ohne sie vorher zu bereinigen.
KI erstellt häufig Frontend-Funktionen wie Kommentarbereiche, Formulare oder Benutzerprofile, ohne eine angemessene Bereinigung der Ausgaben vorzunehmen. Der Code funktioniert und zeigt den Inhalt korrekt an, überprüft aber nicht, ob dieser Inhalt sicher angezeigt werden kann.
Ein Angreifer kann bösartigen JavaScript-Code einschleusen, und die Website zeigt diesen Code anschließend anderen Nutzern an, als wäre er normaler Inhalt.
In der Praxis könnte jemand ein Kommentarfeld nutzen, um versteckten schädlichen Code zu veröffentlichen. Wenn ein anderer Benutzer die Seite öffnet, wird dieser Code in seinem Browser ausgeführt und kann seine Login-Sitzung stehlen, sodass der Angreifer Zugriff auf sein Konto erhält.
Ein drittes Problem ist Insecure Direct Object Reference (IDOR). Dies tritt auf, wenn eine App IDs in URLs verwendet, aber nicht überprüft, ob der Benutzer auf diese konkreten Daten zugreifen darf.
Ein Nutzer könnte zum Beispiel eine Seite wie /invoice/123 öffnen, um seine Rechnung anzusehen. Wenn die App nur prüft, ob der Benutzer angemeldet ist, aber nicht, ob die Rechnung zu ihm gehört, kann der Benutzer die Nummer in der URL zu /invoice/124 ändern und so die Rechnung, das Profil oder die Bestelldaten eines anderen Kunden einsehen.
Das kommt beim Vibe Coding häufig vor, weil KI zwar oft funktionierende Seiten und Routen erzeugt, dabei aber die dazugehörigen Berechtigungsprüfungen im Hintergrund auslässt. Die Funktion arbeitet wie vorgesehen, erzwingt aber nicht, wer Zugriff haben sollte.
2. Hart codierte Geheimnisse in KI-generiertem Code
KI kann sensible Daten direkt in den Code einfügen, statt sie sicher zu speichern.
Zu Secrets gehören API-Schlüssel, Datenbankpasswörter, Zugriffstokens und vertrauliche Zugangsdaten. Diese sollten niemals in Quelldateien geschrieben werden. Sie gehören in eine geschützte Umgebung wie Umgebungsvariablen oder Secret-Manager, in der der Zugriff kontrolliert und überwacht werden kann.
Nehmen wir an, Sie lassen von einer KI Code erzeugen, der eine Verbindung zu einer Zahlungs-API herstellt. Die KI gibt ein funktionsfähiges Snippet aus, bei dem ein API-Schlüssel direkt in die Datei geschrieben ist:
API_KEY = "sk-123456789abcdef"
Dieser Schlüssel sieht echt aus, und der Code funktioniert. Aber so darf es niemals direkt in die Datei geschrieben werden.
Die eigentliche Gefahr ist die Bloßstellung. Sobald ein Geheimnis im Code steht, verbreitet es sich schnell. Es kann in der Versionsverwaltung, in gemeinsamen Repositories, in Protokollen, Backups oder sogar auf Screenshots landen. Ab diesem Zeitpunkt kann es jeder verwenden, der es findet.
Dieser Zugriff erfolgt sofort. Ein offengelegter API-Schlüssel ermöglicht es einer Person, Ihr Konto zu verwenden, Anfragen zu senden und Kosten zu verursachen, die von Ihrer App auszugehen scheinen.
Ein geleaktes Datenbankpasswort kann vollständigen Zugriff auf gespeicherte Daten ermöglichen. Das bedeutet, dass jemand Ihre gesamte Datenbank lesen, kopieren oder löschen kann.
Schon ein kurzer Fehler, etwa wenn Sie Code für ein paar Minuten in ein öffentliches Repository pushen, reicht aus, damit automatisierte Bots diese Secrets erkennen und abgreifen. Sobald das geschieht, können Angreifer fast augenblicklich auf Ihr System zugreifen – oft, noch bevor Sie die Sicherheitslücke überhaupt bemerken.
3. Verwundbare oder veraltete Abhängigkeiten
Veraltete oder verwundbare Abhängigkeiten bergen ein Risiko, weil KI Pakete vorschlagen kann, die unsicher, veraltet oder gar nicht real sind.
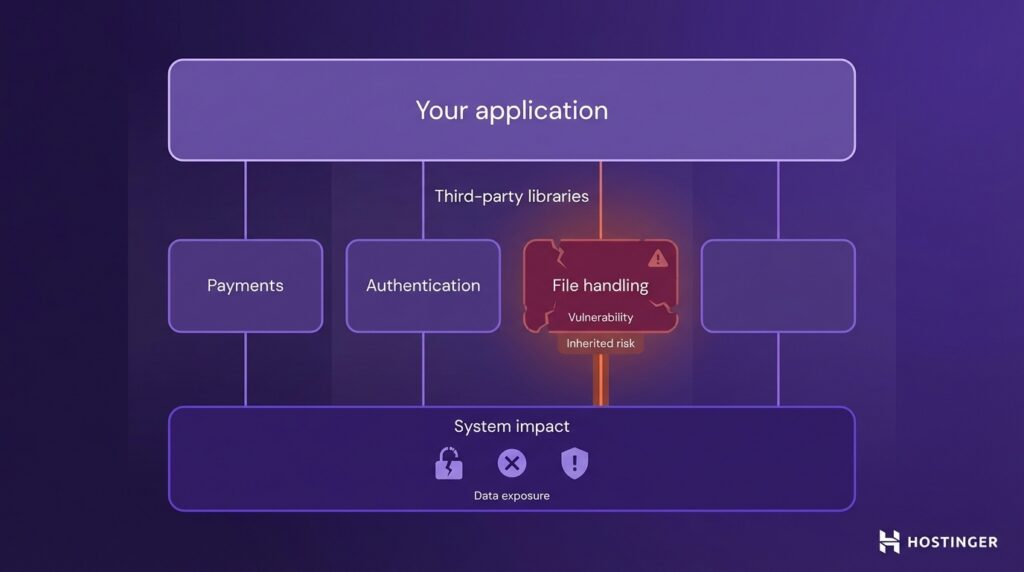
Moderne Anwendungen greifen für Aufgaben wie Zahlungen, Authentifizierung und Dateiverarbeitung auf Bibliotheken von Drittanbietern zurück. Das spart Zeit, bedeutet aber auch, dass Sie Code vertrauen, den jemand anders geschrieben hat.
Wenn diese Bibliothek eine bekannte Sicherheitslücke hat, übernimmt Ihre App diese. Das bedeutet, dass Angreifer diese Schwachstelle ausnutzen können, um auf Daten zuzugreifen, Funktionen zu stören oder schädliche Aktionen innerhalb Ihres Systems auszuführen.
Beim Vibe Coding wird das noch gefährlicher, weil KI nicht das Sichere vorschlägt, sondern das Wahrscheinliche. Es kann veraltete Bibliotheken mit bekannten Problemen empfehlen oder sogar Paketnamen erzeugen, die nicht existieren.
Dadurch entsteht ein Risiko in der Lieferkette. Ihr eigener Code kann einwandfrei sein, aber das von Ihnen installierte Paket kann Ihr System dennoch angreifbar machen. Eine verwundbare Abhängigkeit kann Angreifern über ihre eigenen Schwachstellen einen Einstieg ermöglichen.
Eine gefälschte Bibliothek kann noch weiter gehen, indem sie Geheimnisse stiehlt, Dateien verändert oder während der Installation Schadcode ausführt.
Sie bitten die KI beispielsweise um ein Paket, das Datei-Uploads verarbeitet. Es schlägt eine Bibliothek vor, die vertrauenswürdig wirkt, also installieren Sie sie, ohne sie zu überprüfen.
Die Funktion arbeitet wie vorgesehen, also machen Sie weiter. Aber das Paket ist veraltet und weist eine bekannte Sicherheitslücke auf, oder es handelt sich um ein bösartiges Paket mit einem ähnlichen Namen. Angreifer können diese Abhängigkeit nun ausnutzen, um auf Ihr System oder Ihre Daten zuzugreifen.
4. Fehlende Authentifizierung und Autorisierung
Fehlende Authentifizierung und Autorisierung stellen ein ernstes Risiko dar, weil das System nicht zuverlässig prüft, wer ein Benutzer ist oder was er tun darf.
Authentifizierung und Autorisierung lösen zwei unterschiedliche Probleme. Authentifizierung bestätigt die Identität und stellt sicher, dass der Benutzer tatsächlich die Person ist, für die er sich ausgibt. Autorisierung steuert den Zugriff, also das, was dieser Benutzer sehen oder ändern darf. Wenn einer der beiden Schritte fehlt, gibt das System Daten oder Aktionen an die falschen Personen weiter.
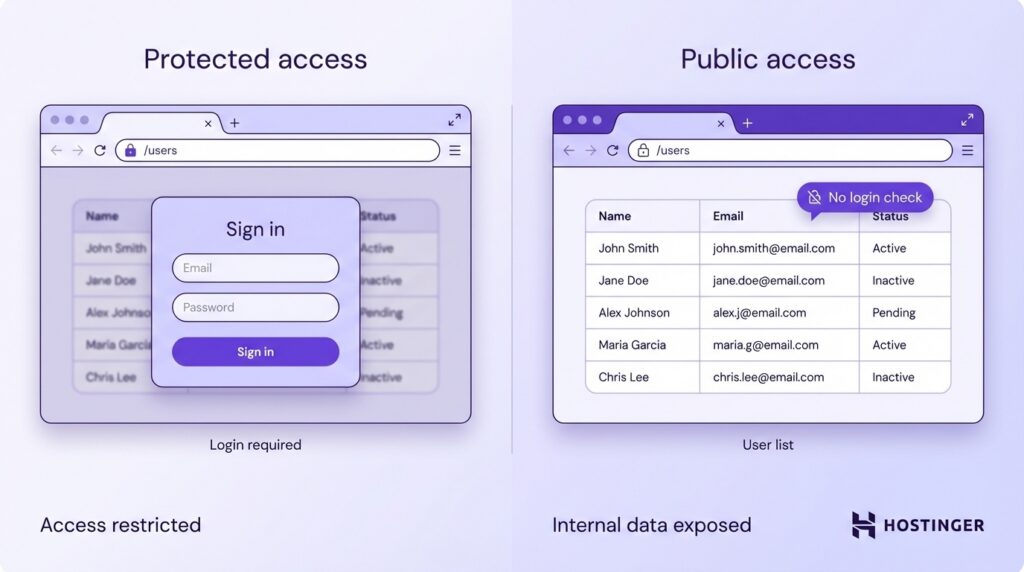
Ein häufiger Fehler sind offene Endpunkte. Ein Endpoint ist einfach eine URL, die Daten anzeigt oder eine Aktion ausführt. Wenn für diese URL keine Anmeldung erforderlich ist, kann jeder darauf zugreifen.
Stellen Sie sich zum Beispiel eine Seite wie /users vor, auf der eine Liste von Kunden angezeigt wird. Wenn es keine Anmeldeprüfung gibt, kann jeder, der diesen Link findet, ihn öffnen. Das bedeutet, dass private Nutzerdaten öffentlich sichtbar sind, selbst wenn sie eigentlich intern bleiben sollten.
Ein weiteres häufiges Problem besteht darin, dass Sicherheitsprüfungen an einigen Stellen angewendet werden, an anderen jedoch fehlen.
Zum Beispiel kann Ihr Dashboard verlangen, dass sich Benutzer anmelden. Dieser Teil funktioniert korrekt. Hinter den Kulissen kann die App jedoch auch eine API-Route wie /api/export-data haben, die dieselben Daten zurückgibt.
Wenn diese API-Route nicht überprüft, ob der Benutzer angemeldet ist, kann jeder direkt darauf zugreifen, indem er die URL aufruft oder eine Anfrage sendet. Auch wenn die Oberfläche sicher wirkt, sind die Daten weiterhin offengelegt.
Problematisch wird es auch, wenn man sich darauf verlässt, dass die Benutzeroberfläche die Berechtigungen durchsetzt.
Sie könnten zum Beispiel die Schaltfläche „Konto löschen“ für reguläre Nutzer ausblenden. Dadurch wirkt es so, als könnten sie keine Konten löschen.
Wenn das Backend die Berechtigungen jedoch nicht prüft, kann ein Benutzer weiterhin manuell eine Anfrage über die Entwicklerwerkzeuge des Browsers oder ein API-Tool senden und damit dieselbe Aktion auslösen.
Mit anderen Worten: Wenn etwas in der Benutzeroberfläche verborgen wird, ist es dadurch nicht geschützt. Der Server muss die Regel durchsetzen.
Das kommt beim Vibe Coding häufig vor, weil KI zwar funktionsfähige Oberflächen und Routen erzeugt, dabei aber keine einheitlichen Prüfungen im gesamten Backend durchsetzt. Die Funktion arbeitet in der Benutzeroberfläche wie erwartet, aber das System steuert nicht vollständig, wer auf diese Aktionen zugreifen oder sie auslösen kann.
5. Übermäßige Berechtigungen bei KI-Agenten
Übermäßige Berechtigungen schaffen Risiken, weil KI-Agenten Zugriff auf mehr Teile Ihres Systems erhalten, als sie tatsächlich benötigen würden.
KI-Agenten sind häufig mit realen Systemen wie Dateien, Datenbanken oder Cloud-Diensten verbunden. Wenn der Zugriff zu umfassend ist, können sie weit über ihre eigentliche Aufgabe hinausgehen.
Ein Agent, der Support-Tickets lesen soll, kann möglicherweise auch Benutzerdaten bearbeiten. Ein Agent, der dafür ausgelegt ist, Protokolle zusammenzufassen, könnte zudem die Berechtigung haben, Dateien zu löschen oder Einstellungen zu ändern.
In der Praxis bedeutet das, dass ein einziger Fehler zu einem schwerwiegenden Vorfall werden kann. Der Agent könnte sensible Daten offenlegen, wichtige Dateien überschreiben oder Änderungen in Produktivsystemen auslösen, ohne dass dies sofort von jemandem bemerkt wird.
Stellen Sie sich einen KI-Agenten vor, der dabei hilft, Dateien in einem gemeinsam genutzten Unternehmenslaufwerk zu organisieren. Er benötigt nur Zugriff auf einen Ordner. Stattdessen erhält es Zugriff auf das gesamte Laufwerk. Die Aufgabe funktioniert, aber nun kann ein missratener Prompt oder ein kleiner Fehler Dateien aus den Bereichen Finanzen, Recht oder Personal verschieben, löschen oder offenlegen.
6. Trügerisches Sicherheitsgefühl bei KI-Ausgaben
Ein trügerisches Sicherheitsgefühl birgt beim Vibe Coding ein erhebliches Risiko, da von KI generierter Code fertig wirken kann, obwohl er nicht sorgfältig geprüft wurde.
Der Code läuft, die Seite lädt, und die Funktion scheint einwandfrei. Dadurch entsteht zu früh Vertrauen. Es wirkt, als würde alles nach gründlicherer Prüfung ausgeliefert. Aber funktionierender Code ist nicht dasselbe wie sicherer Code.
Hier werden wichtige Prüfungen übersprungen. Die Eingabe wird nicht validiert. Berechtigungen werden nicht erzwungen. Sensible Aktionen sind nicht geschützt.
Sie lassen die KI zum Beispiel eine „Passwort vergessen“-Funktion erstellen. Es erstellt ein Formular, in das Benutzer ihre E-Mail-Adresse eingeben, und sendet ihnen einen Link zum Zurücksetzen.
Der Link funktioniert. Sie klicken darauf, legen ein neues Passwort fest, und alles sieht korrekt aus.
Aber der Link läuft nicht ab und ist nicht dem richtigen Benutzer zugeordnet. Wenn ein Angreifer Zugriff auf diesen Link erhält, kann er das Passwort zurücksetzen und das Konto übernehmen.
Warum versagen herkömmliche Sicherheitsprozesse beim Vibe Coding?
Wenn Sie Vibe Coding mit traditionellem Coding vergleichen, besteht der entscheidende Unterschied darin, wie schnell Code von der Idee in die Produktion gelangt – häufig werden dabei Überprüfungsphasen übersprungen, in denen Sicherheitsprobleme erkannt werden.
Stellen Sie sich zum Beispiel vor, Sie entwickeln eine Funktion zum Hochladen von Dateien, mit der Nutzer Profilbilder hochladen können. Die Funktion arbeitet wie vorgesehen: Benutzer laden eine Datei hoch, und sie erscheint auf der Seite.
Aber niemand überprüft, welche Dateitypen erlaubt sind.
Ein Angreifer kann eine schädliche Datei hochladen, zum Beispiel ein Skript, das als Bild getarnt ist. Wenn das System diese Datei verarbeitet oder ausliefert, kann es schädlichen Code ausführen oder die Anwendung gefährden.
In einem herkömmlichen Arbeitsablauf würde ein Prüfer dies frühzeitig bemerken. Sie würden Dateitypbeschränkungen durchsetzen, Uploads validieren und ausführbare Dateien vor der Freigabe blockieren.
In einem Vibe-Coding-Workflow wird dieser Überprüfungsschritt oft ausgelassen, weil die Funktion bereits fertig zu sein scheint.
So sichern Sie Vibe-Coding-Workflows ab
Um Ihren Workflow bei der Nutzung von KI sicher zu halten, sollten Sie in Ihrem Entwicklungsprozess diese Schritte befolgen:
- Schritt 1: Prüfen Sie Ihren KI-generierten Code. Prüfen Sie jede Ausgabe, bevor Sie sie verwenden, und testen Sie, wie sie mit Eingaben, Berechtigungen und Fehlern umgeht.
- Schritt 2: Halten Sie Geheimnisse aus Ihrem Code heraus. Speichern Sie API-Schlüssel und Tokens in Umgebungsvariablen oder einem Secret-Manager.
- Schritt 3: Richten Sie von Anfang an Authentifizierung und Autorisierung ein. Verlangen Sie eine Anmeldung und erzwingen Sie bei jeder Anfrage die Zugriffskontrolle.
- Schritt 4: Säubern und überprüfen Sie alle Benutzereingaben. Akzeptieren Sie nur erwartete Formate und verarbeiten Sie Daten sicher, bevor Sie sie verwenden.
- Schritt 5: Verfolgen Sie Abhängigkeiten regelmäßig. Scannen Sie auf Schwachstellen und halten Sie Pakete aktuell.
- Schritt 6: Grenzen Sie ein, worauf KI-Agenten zugreifen können. Gewähren Sie nur erforderliche Zugriffsrechte und beschränken Sie alles andere.
1. Validieren Sie sämtlichen KI-generierten Code
Überprüfen Sie jede von KI generierte Ausgabe, bevor Sie sie in Ihrem Codebestand verwenden.
Testen Sie zunächst, wie der Code mit Benutzereingaben umgeht. Geben Sie ungültige Daten direkt in der Benutzeroberfläche oder der API ein:
- Buchstaben in numerische Felder eingeben
- Leere Formulare absenden
- Skripte wie alert(1) einfügen
Das System sollte diese Eingaben mit eindeutigen Fehlermeldungen zurückweisen. Wenn sie akzeptiert werden oder das System abstürzt, fehlt eine Validierung.
Überprüfen Sie als Nächstes die Zugriffskontrolle, indem Sie Anfragen ändern. Melden Sie sich als ein Benutzer an und führen Sie dann Folgendes aus:
- IDs in URLs ändern (z. B. /orders/123 → /orders/124)
- API-Anfragen mit unterschiedlichen Benutzerdaten wiederholen
Wenn Sie auf die Daten eines anderen Benutzers zugreifen können, fehlt die Autorisierung.
Scannen Sie den Code nach Geheimnissen. Durchsuchen Sie Ihr Projekt nach Mustern wie:
- API_KEY =
- Passwort =
Entfernen Sie alle hart codierten Werte und verschieben Sie sie in Umgebungsvariablen.
Überprüfen Sie von der KI eingeführte Abhängigkeiten. Sehen Sie sich die Datei package.json oder die Requirements-Dateien an und:
- Suchen Sie den Paketnamen auf Google oder GitHub.
- Prüfen Sie das Datum der letzten Aktualisierung und die Anzahl der Nutzer
- Führen Sie einen Scan mit Tools wie Snyk oder npm audit aus
Installieren Sie keine Pakete, die Sie nicht überprüfen können.
Testen Sie Fehlerfälle direkt. Bringen Sie die Funktion absichtlich zum Absturz, etwa durch:
- Unvollständige Anfragen senden
- Pflichtfelder entfernen
- Abgelaufene Sitzungen simulieren
Das System sollte Fehlermeldungen ausgeben und weder abstürzen noch Daten preisgeben.
Vergleichen Sie abschließend den Code mit den vorhandenen Mustern in Ihrem Projekt. Prüfen Sie, wie ähnliche Funktionen Validierung, Berechtigungen und Datenzugriff handhaben, und stellen Sie sicher, dass der neue Code derselben Struktur folgt.
2. Vermeiden Sie das Hardcodieren von Secrets
Speichern Sie niemals Geheimnisse direkt in Ihrem Code.
Verwenden Sie keine fest im Code hinterlegten Secrets. Speichern Sie API-Schlüssel, Passwörter und Tokens außerhalb Ihres Codes.
Definieren Sie sie in Ihrer Umgebung:
API_KEY=abc123
Greifen Sie dann in Ihrem Code darauf zu:
const apiKey = process.env.API_KEY;
Dadurch bleiben vertrauliche Daten außerhalb Ihres Codebestands.
Überprüfen Sie vor jedem Commit mit Tools wie git-secrets oder Gitleaks, ob geheime Informationen offengelegt werden. Diese Tools scannen Ihren Code und blockieren Commits, die vertrauliche Daten enthalten.
Speichern Sie vertrauliche Zugangsdaten für Produktivsysteme in einem Secret Manager. Verwenden Sie Tools wie AWS Secrets Manager, HashiCorp Vault oder Doppler, um Secrets zur Laufzeit sicher zu speichern und darauf zuzugreifen, anstatt sie in lokalen Dateien zu halten.
Schränken Sie den Zugriff auf jedes Secret ein. Nur die Dienste oder Teile Ihres Systems, die ein Secret benötigen, sollten es lesen können.
Rotieren Sie Geheimnisse regelmäßig. Ersetzen Sie API-Schlüssel und Passwörter nach einem festen Zeitplan oder sofort nach jedem vermuteten Vorfall einer Offenlegung.
Führen Sie abschließend einen Test auf Exposition durch. Pushen Sie Code in ein privates Repository und prüfen Sie, ob Secrets hier erscheinen:
- Commit-Verlauf
- Protokolle
- Fehlermeldungen
Wenn ein Secret irgendwo in Ihrem Codebestand oder in Logs auftaucht, müssen Sie es als kompromittiert behandeln und umgehend ersetzen.
3. Authentifizierung und Autorisierung frühzeitig implementieren
Richten Sie Authentifizierung und Autorisierung gleich zu Beginn Ihres Projekts ein.
Fügen Sie zu jeder nicht öffentlichen Route Authentifizierungsprüfungen hinzu. Schützen Sie im Backend Routen mit Middleware oder Guards (zum Beispiel JWT-Middleware oder Sitzungsprüfungen). Jede Anfrage sollte prüfen, ob der Benutzer angemeldet ist, bevor Daten zurückgegeben werden.
Testen Sie dies, indem Sie Routen in einem privaten Browser öffnen oder ein Tool wie Postman verwenden, ohne sich anzumelden. Die Anfrage sollte einen Fehler wie 401 Unauthorized zurückgeben.
Erzwingen Sie anschließend bei jeder Anfrage eine Autorisierung. Nachdem Sie bestätigt haben, dass der Benutzer angemeldet ist, sollten Sie nun überprüfen, auf welche Inhalte er zugreifen darf. Vergleichen Sie in Ihrer Backend-Logik die ID des authentifizierten Benutzers mit dem Eigentümer der Ressource.
Wenn Sie beispielsweise eine Anfrage wie /orders/123 verarbeiten, dann rufen Sie den Auftrag ab und überprüfen Sie Folgendes:
if (order.userId!== currentUser.id) { return res.status(403).send("Forbidden");
}Testen Sie dies, indem Sie sich als ein Benutzer anmelden und versuchen, auf die Daten eines anderen Benutzers zuzugreifen, indem Sie die IDs in der URL oder in der API-Anfrage ändern. Das System sollte den Statuscode 403 Forbidden zurückgeben.
Vertrauen Sie IDs, die vom Client kommen, nicht. Validieren Sie sie immer auf dem Server. Selbst wenn das Frontend bestimmte Daten ausblendet, sollten Sie davon ausgehen, dass Benutzer Anfragen manuell verändern können.
Wenden Sie in der gesamten Anwendung dieselbe Zugriffskontrolllogik an. Verwenden Sie gemeinsame Middleware, Helper oder Richtlinien, anstatt für jeden Endpunkt eigene Prüfungen zu schreiben. So werden Lücken vermieden, in denen einige Routen ungeschützt bleiben.
Testen Sie nicht autorisierte Szenarien direkt. Verwenden Sie Tools wie Postman oder die Entwicklertools des Browsers, um:
- Authentifizierungs-Token entfernen
- Anfrage-Payloads bearbeiten
- Anfragen mit unterschiedlichen Benutzerdaten erneut senden
Jede unautorisierte Anfrage sollte blockiert werden.
Schließlich sollten Sie bei jeder neuen Funktion Authentifizierungs- und Autorisierungsprüfungen einbauen. Fügen Sie sie nicht später hinzu. Fangen Sie beim Erstellen eines neuen Endpunkts zuerst mit dem Schutz an und implementieren Sie anschließend die Funktionslogik.
4. Benutzereingaben bereinigen und validieren
Behandeln Sie alle Benutzereingaben als unsicher und validieren Sie diese, bevor Sie sie irgendwo in Ihrem System verwenden.
Beginnen Sie damit, Validierungsregeln in Ihrem Backend hinzuzufügen. Verwenden Sie eine Validierungsbibliothek wie Joi, Zod oder die integrierten Validatoren Ihres Frameworks, um festzulegen, welche Werte jedes Feld akzeptieren soll.
Zum Beispiel:
const schema = z.object({
email: z.string().email(),
age: z.number().int().min(0)
});Führen Sie diese Validierung aus, bevor Sie die Anfrage verarbeiten. Wenn die Eingabe nicht dem Schema entspricht, geben Sie einen Fehler zurück und beenden Sie die Ausführung:
if (!schema.safeParse(req.body).success) {
return res.status(400).send("Invalid input");
}Versuchen Sie nicht, ungültige Eingaben zu korrigieren. Weisen Sie es zurück und verlangen Sie vom Benutzer, dass er korrekte Daten sendet.
Als Nächstes sollten Sie die Daten bereinigen, bevor Sie sie in Abfragen verwenden oder auf einer Seite ausgeben. Verwenden Sie integrierte Schutzmechanismen wie Template-Engines, die HTML standardmäßig escapen, sowie Bibliotheken wie DOMPurify für von Benutzern erstellte Inhalte.
Für Datenbankabfragen sollten Sie stets parametrisierte Abfragen anstelle von String-Konkatenation verwenden.
// safe
db.query("SELECT * FROM users WHERE email = ?", [email]);
// unsafe
db.query(`SELECT * FROM users WHERE email = '${email}'`);Testen Sie Ihre Eingabeverarbeitung direkt. Probieren Sie Folgendes aus:
- Eingabe von Skripten wie <script>alert(1)</script>
- Übermittlung langer oder unerwarteter Zeichenfolgen
- Ungültige Formate mit API-Tools wie Postman senden
Das System sollte die Eingabe zurückweisen oder sie sicher maskieren. Es darf niemals Code ausführen oder unerwartete Daten zurückgeben.
Wenn Ihre App Datei-Uploads umfasst, dann beschränken Sie die Dateitypen und -größen auf dem Server. Verlassen Sie sich nicht auf Prüfungen auf der Client-Seite.
Wenden Sie schließlich für jede Eingabequelle dieselben Validierungs- und Bereinigungsregeln an. Dazu gehören Formulare, API-Anfragen, URL-Parameter und Datei-Uploads. Gehen Sie niemals davon aus, dass eine Eingabe sicher ist, nur weil sie aus Ihrem Frontend stammt.
5. Abhängigkeiten kontinuierlich überwachen
Verfolgen Sie jede Abhängigkeit in Ihrem Projekt und überprüfen Sie sie regelmäßig auf bekannte Sicherheitslücken.
Führen Sie zunächst lokal einen Abhängigkeits-Scan aus. Verwenden Sie integrierte Tools wie:
npm audit
oder
pip-audit
Hier werden bekannte Schwachstellen in Ihren aktuellen Abhängigkeiten angezeigt.
Automatisieren Sie dies anschließend in Ihrem Workflow. Fügen Sie Ihrem Repository einen Dependency-Scanner wie Dependabot, Snyk oder Aikido hinzu. Aktivieren Sie beispielsweise Dependabot in GitHub, damit es Ihre Abhängigkeiten automatisch scannt und Pull Requests mit Sicherheitskorrekturen erstellt.
Dadurch entfällt die manuelle Kontrolle.
Bevor Sie ein Paket installieren, sollten Sie es manuell überprüfen:
- Suchen Sie den Paketnamen auf npm oder PyPI
- Überprüfen Sie das Datum der letzten Aktualisierung
- Überprüfen Sie die Anzahl der Downloads oder GitHub-Sterne
Wenn das Paket keine Aktivität aufweist oder verdächtig wirkt, dann installieren Sie es nicht.
Fixieren Sie Ihre Abhängigkeitsversionen, um unerwartete Änderungen zu verhindern. Verwenden Sie Lockfiles wie:
- package-lock.json
- yarn.lock
- requirements.txt
Vermeiden Sie vage Formulierungen wie:
"library": "^1.0.0"
Verwenden Sie stattdessen feste Versionen:
"library": "1.0.0"
Aktualisieren Sie Abhängigkeiten regelmäßig. Wenn ein Tool eine Sicherheitslücke meldet, dann:
- Update ausführen (npm update oder ähnlich)
- Änderungen überprüfen
- Die betroffene Funktion testen
Zögern Sie Aktualisierungen nicht hinaus, da bekannte Schwachstellen aktiv ausgenutzt werden.
Entfernen Sie ungenutzte Abhängigkeiten, indem Sie Ihre Projektdateien überprüfen. Wenn ein Paket nirgends importiert oder verwendet wird, dann löschen Sie es und führen Sie Folgendes aus:
npm uninstall package-name
Dadurch verringert sich unnötiges Risiko.
Nach jedem Update sollten Sie die Funktion testen, die von diesem Paket abhängt. Zum Beispiel:
- Upload-Bibliothek aktualisieren → Datei-Uploads testen
- Auth-Bibliothek aktualisieren → Anmeldeablauf testen
Überprüfen Sie abschließend, ob alles funktioniert und keine Schwachstellen mehr vorhanden sind:
npm audit
Der Scan sollte keine kritischen Probleme zurückgeben.
6. Berechtigungen von KI-Agenten einschränken
Gewähren Sie jedem KI-Agenten nur den Zugriff, den er zur Erfüllung seiner Aufgabe benötigt.
Beginnen Sie damit, den Aufgabenbereich des Agenten konkret zu definieren. Schreiben Sie genau auf, was es tun soll, zum Beispiel: „Support-Tickets aus der /tickets -API lesen“ oder „Dateien aus dem Ordner /reports zusammenfassen.“ Fahren Sie erst fort, wenn dieser Umfang eindeutig ist.
Erstellen Sie eingeschränkte Zugangsdaten, anstatt Schlüssel mit Vollzugriff zu verwenden. Wenn Sie einen API-Schlüssel oder ein Token erstellen, dann konfigurieren Sie die Berechtigungen so, dass nur bestimmte Aktionen erlaubt sind. Zum Beispiel:
- Zulassen – GET /tickets
- Block – POST- DELETE- oder Admin-Aktionen
Vermeiden Sie die Verwendung von Root-, Admin- oder Vollzugriffs-Zugangsdaten.
Den Zugriff auf bestimmte Ressourcen beschränken. In Ihrem System oder bei Ihrem Cloud-Anbieter:
- Zugriff auf einen Ordner statt auf den gesamten Storage-Bucket gewähren
- Eine einzelne Datenbanktabelle anstelle der gesamten Datenbank zulassen
- APIs auf bestimmte Endpunkte beschränken
Erzwingen Sie dies mithilfe von IAM-Rollen oder Berechtigungsrichtlinien.
Beginnen Sie mit schreibgeschütztem Zugriff. Weisen Sie Berechtigungen zu, die ausschließlich das Lesen von Daten erlauben. Testen Sie anschließend den Agenten. Fügen Sie Schreib- oder Löschberechtigungen nur hinzu, wenn die Aufgabe ohne diese Berechtigungen fehlschlägt.
Führen Sie den Agenten zunächst in einer Testumgebung aus. Verbinden Sie es mit Staging-Daten statt mit Produktionsdaten. Überprüfen Sie sein Verhalten, bevor Sie ihm Zugriff auf echte Benutzer oder Systeme gewähren.
Testen Sie Berechtigungen, indem Sie versuchen, sie zu umgehen. Verwenden Sie den Agenten oder die API manuell, um:
- Auf einen anderen Ordner zugreifen
- Daten ändern, obwohl sie nur gelesen werden sollten
- Endpunkte außerhalb seines Geltungsbereichs aufrufen
Jeder Versuch sollte mit einer Meldung „Zugriff verweigert“ oder einer Antwort mit dem Statuscode 403 Forbidden fehlschlagen.
Aktivieren Sie die Protokollierung für alle Agentenaktionen. Aufzeichnung:
- Welche Dateien es aufruft
- Welche APIs aufgerufen werden
- Welche Aktionen es ausführt
Überprüfen Sie die Protokolle, nachdem Sie den Agenten ausgeführt haben. Bestätigen Sie, dass nur die Aktionen ausgeführt werden, die Sie zuvor definiert haben.
Wenn der Agent mehr tun kann als vorgesehen, dann verringern Sie seine Berechtigungen und testen Sie erneut.
Welche Tools helfen dabei, von KI generierten Code abzusichern?
Vibe-Coding-Tools helfen Ihnen, Anwendungen schnell zu entwickeln, sichern sie jedoch nicht standardmäßig ab. Um KI-generierten Code zu schützen, benötigen Sie einen eigenen Satz von Tools, die in drei Gruppen fallen: Code-Scanning, Dependency-Scanning und Laufzeitschutz.
Tools wie Aikido, Snyk und CodeAnt decken unterschiedliche Teile dieses Workflows ab, während CSAs AI Controls Matrix dabei hilft festzulegen, welche Kontrollen anzuwenden sind.
Code-Scanning (SAST)
Static Application Security Testing, kurz SAST, durchsucht den Quellcode nach riskanten Mustern, bevor Sie ausliefern.
Dies ist hilfreich, um Probleme in von KI generiertem Code zu erkennen, etwa unsichere Verarbeitung von Eingaben, offengelegte Geheimnisse oder schwache Logik in Pull Requests und IDEs. Zu den Tools in dieser Gruppe gehören Aikido, CodeAnt und Snyk Code.
Abhängigkeitsprüfung
Abhängigkeits-Scanner überprüfen die Drittanbieter-Pakete, von denen Ihr Code abhängt, und melden bekannte Sicherheitslücken. Das ist beim Vibe Coding wichtig, weil KI veraltete Bibliotheken oder sogar Paketnamen vorschlagen kann, die vor der Installation überprüft werden sollten.
Snyk und Aikido scannen beide Open-Source-Abhängigkeiten, und CodeAnt umfasst in seiner Plattform ebenfalls eine Softwarezusammensetzungsanalyse.
Laufzeitschutz
Manche Probleme treten nur unter realem Traffic auf, nicht während des Code-Reviews. Laufzeitschutz überwacht, was nach der Bereitstellung des Codes geschieht, und hilft dabei, laufende Angriffe zu erkennen oder zu blockieren.
Aikido ist ein Beispiel für eine Plattform, die über Code- und Abhängigkeits-Scans hinaus bis in die Erkennung und Blockierung von Bedrohungen zur Laufzeit reicht.
Wo CSA einzuordnen ist
CSA unterscheidet sich von den oben genannten Tools. Es ist kein Scanner. Die AI Controls Matrix der Cloud Security Alliance ist ein anbieterneutrales Kontrollrahmenwerk für die Absicherung von KI-Systemen. Am besten eignet sie sich, um Ihren Prozess festzulegen, Anforderungen zu überprüfen und eine Sicherheitsbaseline für KI-generierten Code zu definieren.
Checkliste für sicheres Vibe-Coding

Verwenden Sie diese Checkliste, um die häufigsten Risiken schnell zu erkennen, bevor Code in die Produktion gelangt.
- Verwenden Sie keine fest im Code hinterlegten Secrets – halten Sie API-Schlüssel, Passwörter und Tokens aus Ihrem Code heraus, indem Sie sie in Umgebungsvariablen oder einem Secret-Manager speichern.
- Prüfen Sie allen KI-generierten Code – behandeln Sie KI-Ausgaben als Entwurf und kontrollieren Sie, wie damit Eingaben, Zugriffskontrollen und sensible Daten verarbeitet werden, bevor Sie den Code verwenden.
- Verlangen Sie Standardmäßig Authentifizierung – machen Sie die Anmeldung zur Vorgabe für alle nicht öffentlichen Funktionen, damit Endpunkte nicht versehentlich offen bleiben.
- Prüfen Sie Abhängigkeiten auf bekannte Schwachstellen – kontrollieren Sie externe Pakete regelmäßig, um zu verhindern, dass unsicherer oder veralteter Code in Ihre App gelangt.
- Validieren und bereinigen Sie Benutzereingaben – stellen Sie sicher, dass alle Eingaben den erwarteten Formaten entsprechen und nicht zur Einschleusung schädlichen Codes verwendet werden können.
- Beschränken Sie Berechtigungen für KI-Agenten und Tools auf das unbedingt erforderliche Minimum, damit Fehler oder Missbrauch begrenzt bleiben.
Wissenswertes, bevor Sie Vibe Coding in der Produktion einsetzen
Vibe Coding verschafft Ihnen Tempo, erhöht aber auch das Sicherheitsrisiko.
Mit KI können Sie schnell funktionsfähige Features erstellen, aber schnellerer Code ist nicht unbedingt auch sichererer Code. Wenn in kürzerer Zeit mehr Code entsteht, werden Reviews schneller ausgelassen und Sicherheitsprobleme leichter übersehen.
Dadurch müssen Sie Ihre Sicht auf Entwicklung grundlegend ändern. Betrachten Sie von KI generierten Code nicht als vertrauenswürdig. Behandeln Sie ihn als Entwurf, der vor der Veröffentlichung überprüft, getestet und validiert werden muss.
Zum Beispiel kann KI in Minuten ein funktionsfähiges Dashboard erstellen. Die Seiten werden geladen und die Daten angezeigt, aber ohne ordentliche Zugriffskontrollen sehen Benutzer möglicherweise Daten, die sie nicht sehen sollten. Die Funktion arbeitet zwar, ist aber nicht sicher.
Um Vibe-Coding sicher in der Produktion zu nutzen, befolgen Sie standardmäßig die Best Practices für die Sicherheit von Webanwendungen: Authentifizierung verlangen, Eingaben prüfen, Geheimnisse schützen, Abhängigkeiten überprüfen und Berechtigungen einschränken.
Sicherheit muss außerdem fester Bestandteil Ihres Workflows sein. Verlassen Sie sich nicht auf manuelle Prüfungen am Ende: Automatisierte Scans hinzufügen, Reviews erzwingen und Edge Cases als Teil der Entwicklung testen.
Die Plattform, die Sie verwenden, beeinflusst auch, wie sicher Sie KI-generierte Apps entwickeln und bereitstellen können. Hostinger Horizons Vibe-Coding-Tool vereint zum Beispiel promptbasiertes App-Building, integriertes Hosting und 1-Klick-Veröffentlichung in einer einzigen Umgebung und verringert so den Einrichtungsaufwand, der bei der Bereitstellung häufig zu Fehlern führt.
Es umfasst außerdem Schutzmechanismen auf Infrastrukturebene wie eine Firewall, Malware-Scans und DDoS-Schutz sowie Funktionen wie die Versionshistorie von Projekten und integrierte Back-End-Unterstützung für Konten, Logins und Datenspeicherung.
Dies trägt zur schnelleren Inbetriebnahme und zur betrieblichen Sicherheit bei, ersetzt jedoch keine Sicherheit auf Anwendungsebene. Sie müssen die generierte Logik weiterhin überprüfen, Eingaben validieren, Authentifizierung und Autorisierung durchsetzen, Geheimnisse schützen und testen, wie sich die App verhält, bevor Sie sie veröffentlichen.
Alle Tutorial-Inhalte auf dieser Website unterliegen Hostingers strengen redaktionellen Standards und Normen.

Eveline ist Lokalisierungsexpertin mit langjähriger Erfahrung in der Transkreation von Inhalten für den deutschen Markt. Sie unterstützt Hostinger dabei, die Kernwerte und die Markenbotschaft des Unternehmens an ein internationales Publikum zu vermitteln und Hostingers hochwertige Tutorials für alle zugänglich zu machen.
Comments
0 responses