MySQL Setup at Hostinger Explained

At Hostinger, we have various MySQL setups starting from the standalone replica-less instances, Percona XtraDB Cluster (PXC), and ProxySQL based routing, to even absolutely custom and unique solutions which I’m going to describe in this blog post.
We do not have elephant-sized databases for internal services like API, billing, and clients, since high availability is our top priority instead of scalability.
Still, scaling vertically is good enough for our case, as the database size does not exceed 500 GB. One of the top requirements is the ability to access the master node, as we have fairly equal-distanced workloads for reading and writing.
Our current setup for storing all the data about the clients, servers, and so forth is using PXC formed of three nodes without any geo-replication. All nodes are running in the same data center.
We have plans to migrate this cluster to a geo-replicated cluster across three locations: the United States, Netherlands, and Singapore. This would allow us to warrant high availability if one of the locations became unreachable.
Since PXC uses fully synchronous replication, there will be higher latencies for writes. But the reads will be much quicker because of the local replica in every location.
We did some research on MySQL Group Replication, and found out that it requires instances to be closer to each other and is more sensitive to latencies.
Group Replication is designed to be deployed in a cluster environment where server instances are very close to each other, and is impacted by both network latency as well as network bandwidth.
As PXC was used previously, we know how to deal with it under critical circumstances and make it more available.
In 000webhost.com project and an hAPI (Hostinger API) we use our aforementioned unique solution which selects the master node using Layer3 protocol.
One of our best friends is BGP and BGP protocol, which is aged enough to buy its own beer, hence we use it a lot. This implementation also uses BGP as the underlying protocol and helps to point to the real master node. To run the BGP protocol we use the ExaBGP service and announce VIP address as anycast from both master nodes.
You should be asking: but how are you sure MySQL queries go to the one and the same instance instead of hitting both? We use Zookeeper’s ephemeral nodes to acquire the lock as mutually exclusive.
Zookeeper acts like a circuit breaker between BGP speakers and MySQL clients. If the lock is acquired we announce the VIP from the master node and applications send the queries toward this path. If the lock is released, another node can take it over and announce the VIP, so the application will send the queries without any effort.
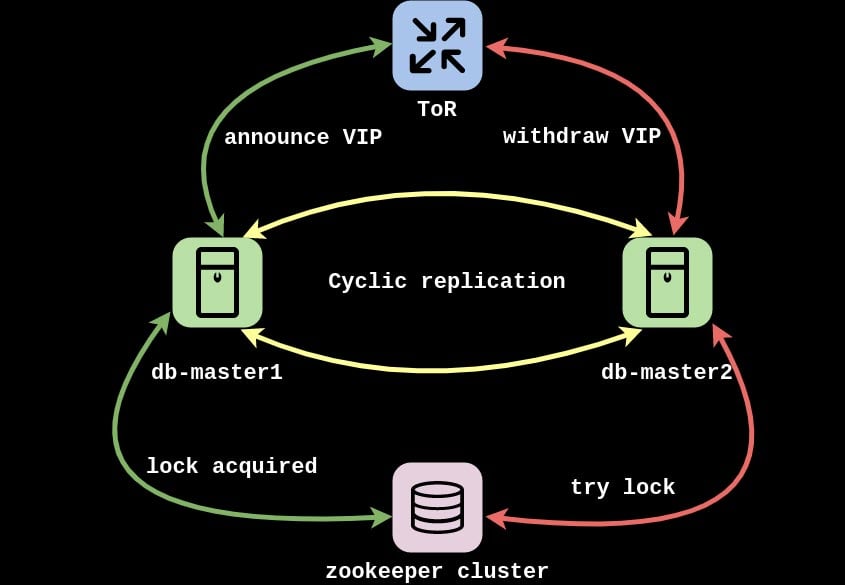
The second question comes: what conditions should be met to stop announcing VIP? This can be implemented differently depending on the use case, but we release the lock if the MySQL process is down using systemd’s Requires in the unit file of ExaBGP:
Besides, with or without specifying After=, this unit will be stopped if one of the other units is explicitly stopped.
With systemd we can create a nice dependency tree that ensures all of them are met. Stopping, killing, or even rebooting the MySQL will make systemd stop the ExaBGP process and withdraw the VIP announcement. The final result is a new master selected.
We have battle-tested those master failovers during our Gaming days and haven’t noticed anything critical yet.
If you think good architecture is expensive, try bad architecture 😉



