Como criar um assistente pessoal totalmente autônomo no n8n usando MCP
Mar 25, 2026
/
Bruno S.
/
14 min Ler
Meu assistente pessoal acabou de agendar três reuniões, resumir meus e-mails não lidos e preparar uma resposta – tudo isso enquanto eu fazia café.
E não, isso não foi feito com um script simples. Eu criei um agente de IA de verdade ao montar um fluxo de automação personalizado no n8n e executá-lo em uma VPS da Hostinger.
O coração desse sistema é o Model Context Protocol (MCP), que permite que o “cérebro” de IA se conecte com segurança a outros aplicativos e os controle, como o Google Calendar e o Gmail.
Na prática, essa é uma forma poderosa de entender como criar um assistente pessoal no n8n usando MCP, com uma solução self-hosted capaz de interpretar pedidos e automatizar tarefas em várias plataformas.
Continue lendo para acompanhar todo o processo, desde o planejamento inicial até a versão final. Também vou compartilhar um template de workflow para download, para que você possa colocar o seu assistente no ar sem perder tempo.
O que é um assistente pessoal com MCP?
Um assistente pessoal com MCP é um fluxo de automação que usa um modelo de linguagem de IA para interpretar comandos e o Model Context Protocol (MCP) para executar tarefas complexas em várias etapas, conectando diferentes aplicativos.
Esta abordagem de integração de IA permite que você construa um assistente verdadeiramente multiplataforma.
Para entender isso, vamos analisar os três componentes principais:
- n8n. A plataforma de automação onde reside todo o fluxo de trabalho. Pense no n8n como a oficina onde você constrói e executa seu assistente. É a base para este projeto de automação de código aberto com o MCP.
- O “cérebro” da IA. Um grande modelo de linguagem (LLM), como o Gemini ou o GPT-4, que interpreta seus comandos. Quando você solicita que ele faça algo, ele determina as etapas necessárias e seleciona as ferramentas adequadas para acionar as tarefas.
- O “sistema nervoso” (MCP). Atuando como o sistema nervoso do assistente, o MCP é a camada de comunicação que permite que o cérebro da IA controle com segurança outras ferramentas, como o Google Agenda ou o Gmail. Para este tipo de trabalho agêntico, uma integração n8n-MCP é muito mais confiável do que o uso de webhooks simples, pois estabelece um canal persistente e seguro para a execução de comandos complexos.
Por que decidi construir este assistente
Eu decidi construir este assistente pessoal para resolver um problema específico: reduzir o tempo que eu gastava alternando entre aplicativos para tarefas rotineiras.
Minha rotina matinal era um exemplo clássico. Eu verificava meu Google Agenda para ver a programação do dia, depois mudava para o Gmail para procurar e-mails urgentes e, em seguida, abria outro aplicativo para criar uma lista de tarefas com base no que encontrava.
Era um processo repetitivo e manual que desperdiçava um tempo precioso.
Embora eu pudesse criar automações simples e separadas para algumas dessas etapas, elas não conseguiam “conversar” entre si. Um fluxo de trabalho básico pode buscar eventos de calendário e outro pode verificar e-mails, mas nenhum deles consegue entender o contexto ou tomar decisões com base nas descobertas do outro.
Eu precisava de mais do que apenas um script – eu precisava de um “agente” baseado em IA que pudesse entender um comando em linguagem natural como: “Resuma minha manhã e elabore uma lista de prioridades”.
Para realmente automatizar tarefas com o n8n de forma dinâmica, tive que ir além dos fluxos de trabalho lineares. Isso justificou a complexidade de uma integração completa de IA, levando-me a projetar um sistema que não apenas seguia instruções, mas também compreendia a intenção por trás delas.
Como eu projetei o fluxo de trabalho do meu assistente
Eu projetei o fluxo de trabalho do meu assistente autônomo conceituando a lógica e, em seguida, criando um diagrama visual da arquitetura antes de modificar qualquer nó no n8n.
Primeiro, eu mapeei a lógica. Antes de criar um fluxo de trabalho de automação, você precisa entender cada etapa do processo que está tentando substituir.
Comecei anotando a sequência exata de eventos de uma tarefa comum, como agendar uma reunião. Isso envolveu definir as entradas (a solicitação do usuário), os pontos de decisão (informações necessárias como a data ou o número de participantes) e a saída final (um evento no calendário e uma mensagem de confirmação).
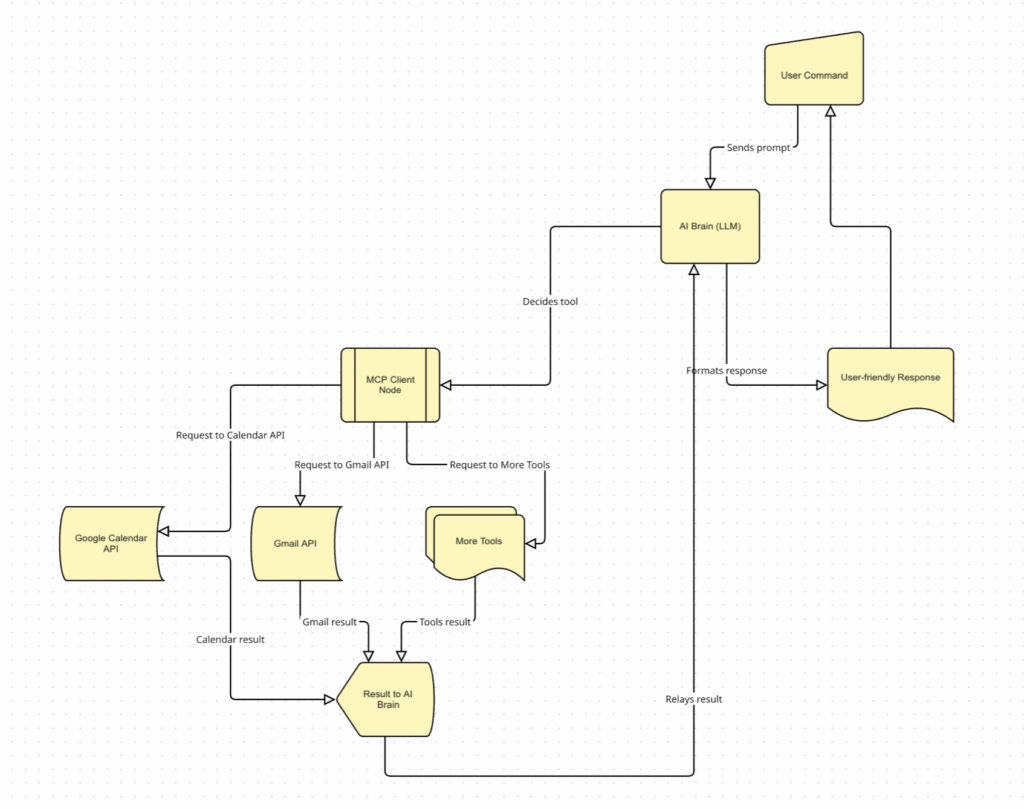
Em segundo lugar, visualizei toda a arquitetura. Uma lista simples não é suficiente para um sistema dinâmico, por isso criei um diagrama para mostrar como todos os componentes se conectam e como os dados fluem entre eles. Este mapa visual mostra a jornada completa:
- A entrada do comando. O processo começa quando o assistente recebe um comando de um usuário.
- O núcleo de decisão da IA. O comando é enviado ao modelo de IA, que atua como o hub central de tomada de decisão (o “cérebro”). Ele interpreta a solicitação e decide qual ferramenta é necessária para atendê-la.
- Seleção de ferramentas via MCP. Este é o passo crítico. A IA não controla diretamente a ferramenta. Em vez disso, ele envia uma requisição formatada para o nó cliente MCP no n8n.
- Execução e resultado. O nó cliente MCP aciona de forma segura a ferramenta correta (como o Google Agenda) para executar uma ação. Assim que a tarefa for concluída, ela retorna um resultado (como “evento criado com sucesso”) através do fluxo de trabalho.
Veja como essa arquitetura aparece no quadro do Miro:
O que eu preparei antes de construir meu assistente
Para construir meu assistente pessoal n8n auto-hospedado, preparei um servidor confiável, uma instância do n8n e as credenciais de API para os serviços que eu queria conectar.
Aqui estão os pré-requisitos específicos:
- Um servidor virtual privado (VPS). Para manter meus dados privados e manter o controle total, eu construí este assistente em um VPS n8n auto-hospedado. Escolhi a Hostinger porque ela me permite pular todo o processo de configuração, já que o n8n vem pré-instalado como um modelo. Ele fornece acesso root completo e recursos dedicados de que preciso para garantir que o assistente permaneça estável e tenha um bom desempenho 24 horas por dia, 7 dias por semana.
- Uma instância do n8n em funcionamento. Geralmente, após configurar um servidor, o próximo passo é instalar o n8n. No entanto, como usei a Hostinger, minha instância do n8n já estava pré-instalada e pronta para usar. Se você estiver configurando uma instância em um servidor diferente ou preferir a configuração manual usando comandos, este guia sobre como instalar o n8n traz os detalhes.
- Chaves de API e credenciais. A etapa final foi coletar as credenciais de API que permitiriam ao meu fluxo de trabalho do n8n acessar meus dados em outros aplicativos com segurança. Eu precisava de credenciais para três serviços específicos:
- OpenAI. Para fornecer o “cérebro” de IA para o assistente.
- Google Workspace. Para conceder acesso para ler minha agenda e gerenciar e-mails no Gmail.
- Slack. Para criar um sistema de notificação. Configurei de forma que, se um fluxo de trabalho falhasse, ele enviasse imediatamente um alerta para um canal privado do Slack, permitindo-me corrigir o problema.
📈 Em números
Desde o seu lançamento em janeiro de 2025, o template n8n da Hostinger ultrapassou 50.000 instalações totais até setembro de 2025. Com uma média de cerca de 800 novas instalações por mês, ele se tornou rapidamente o template nº 1 mais popular da Hostinger e seu segundo produto de VPS mais popular no geral, atrás apenas do serviço de VPS regular.
Como eu construí meu assistente pessoal no n8n com MCP
Meu processo para este projeto n8n-MCP divide-se em cinco etapas diretas: configurar o ponto de entrada da conversa, construir o núcleo de IA com memória, estabelecer o canal de comunicação de ferramentas com o MCP, conectar as ferramentas do assistente e implementar o tratamento de erros.
Se você quiser começar agora mesmo ou acompanhar com uma versão concluída, pode baixar os modelos completos de fluxo de trabalho que usei aqui:
Passo 1: configurando o ponto de entrada da conversa
O primeiro passo foi criar o ponto de entrada para o meu assistente. Eu consegui isso adicionando o nó “When chat message received” ao meu fluxo de trabalho.
Este nó específico é um Gatilho de Chat, servindo como a porta de entrada para toda a automação. Sua função é monitorar mensagens recebidas e iniciar o fluxo de trabalho sempre que uma nova chegar.
Para esta build, usei a interface de teste integrada que este nó fornece. Então, quando eu executo manualmente o workflow no editor do n8n, uma caixa de chat aparece no canto.

Isso me permite enviar prompts diretamente ao assistente para testar suas respostas sem precisar configurar nenhum aplicativo externo.
Passo 2: construindo o núcleo de IA com um agente, LLM e memória
Com o ponto de entrada configurado, o próximo passo foi construir o cérebro do assistente. Adicionei um nó de Agente de IA e o conectei a um modelo de linguagem para raciocínio e a um nó de memória para contexto.
O componente central aqui é o nó de Assistente Pessoal, que recebe o prompt do gatilho e orquestra toda a resposta.
Em seguida, conectei duas entradas essenciais a este agente:
- Modelo de Chat da OpenAI. Este é o LLM que faz o pensamento propriamente dito. Eu o configurei para usar o modelo gpt-4.1-2025-04-14. É responsável por entender a solicitação do usuário.
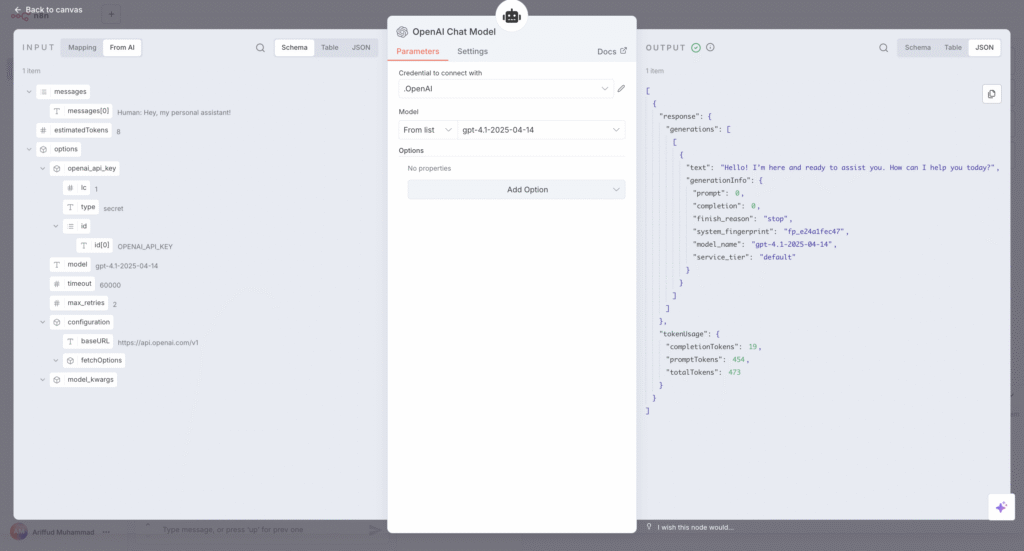
- Memória Simples. Este nó fornece ao assistente memória conversacional, permitindo que ele se lembre de mensagens anteriores dentro da mesma sessão. Isso é crucial para lidar com perguntas de acompanhamento sem que eu precise repetir o contexto.
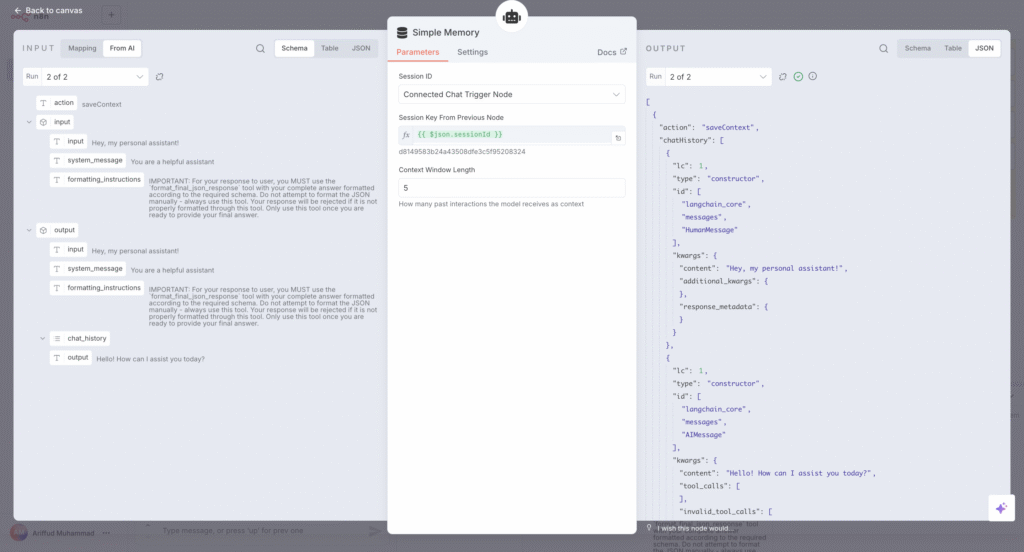
Para orientar o comportamento do LLM, configurei um prompt de sistema dentro do nó do agente de Assistente Pessoal. Esta é uma etapa crítica na qual forneço à IA suas instruções principais, dizendo-lhe como agir e qual é o seu propósito. Por exemplo, eu incluí instruções como:
Você é um assistente pessoal prestativo. Com base na solicitação do usuário, você deve escolher uma das ferramentas disponíveis para auxiliá-lo.
Isso garante que o assistente mantenha o foco na tarefa e use as ferramentas que eu forneço.
Passo 3: estabelecendo o canal de comunicação da ferramenta de IA com o MCP
O núcleo de IA requer uma forma de se comunicar com suas ferramentas. Para isso, configurei um sistema de duas partes utilizando o MCP Server Trigger e os nós do MCP Client.
Este processo estabelece um canal de comunicação seguro para o agente de IA interagir com ferramentas. Veja como eu o configurei:
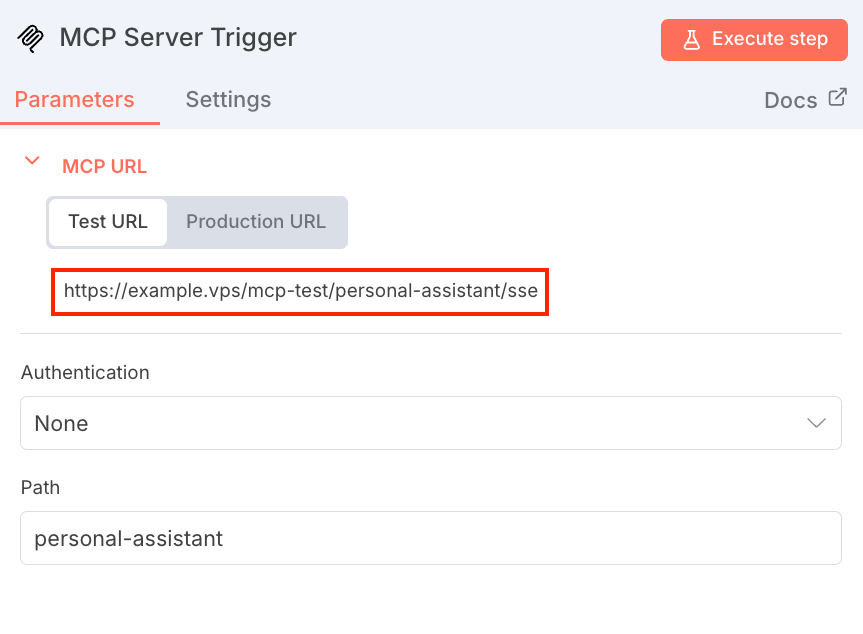
- Eu adicionei um nó de Gatilho de Servidor MCP ao meu canvas. Este nó atua como um hub central que escuta instruções do agente de IA. Depois disso, copiei sua URL de webhook exclusiva, que é necessária para o cliente se conectar a ela.
- Eu também incluí um nó cliente MCP. Eu configurei o campo SSE Endpoint colando a URL que copiei do MCP Server Trigger. Em seguida, conectei o nó do Cliente MCP à entrada de Ferramenta do meu agente de Assistente Pessoal.
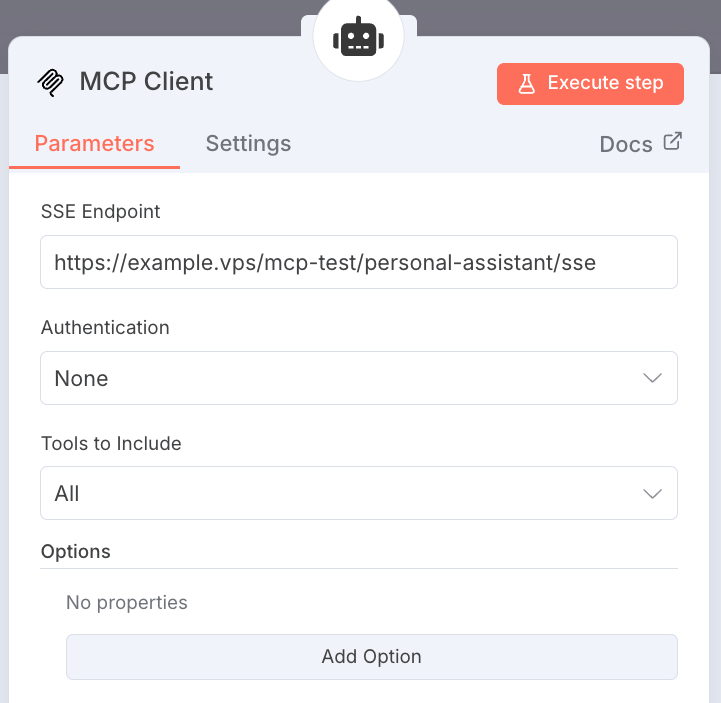
Esta configuração de dois nós é o núcleo do MCP neste fluxo de trabalho. O agente não chama ferramentas como o Google Agenda diretamente.
Em vez disso, ele envia uma instrução ao Cliente MCP, e o cliente transmite essa mensagem de forma segura ao Servidor MCP, que então ativa a ferramenta correta. Isso torna o sistema mais organizado e seguro.
Passo 4: conectando as ferramentas do assistente
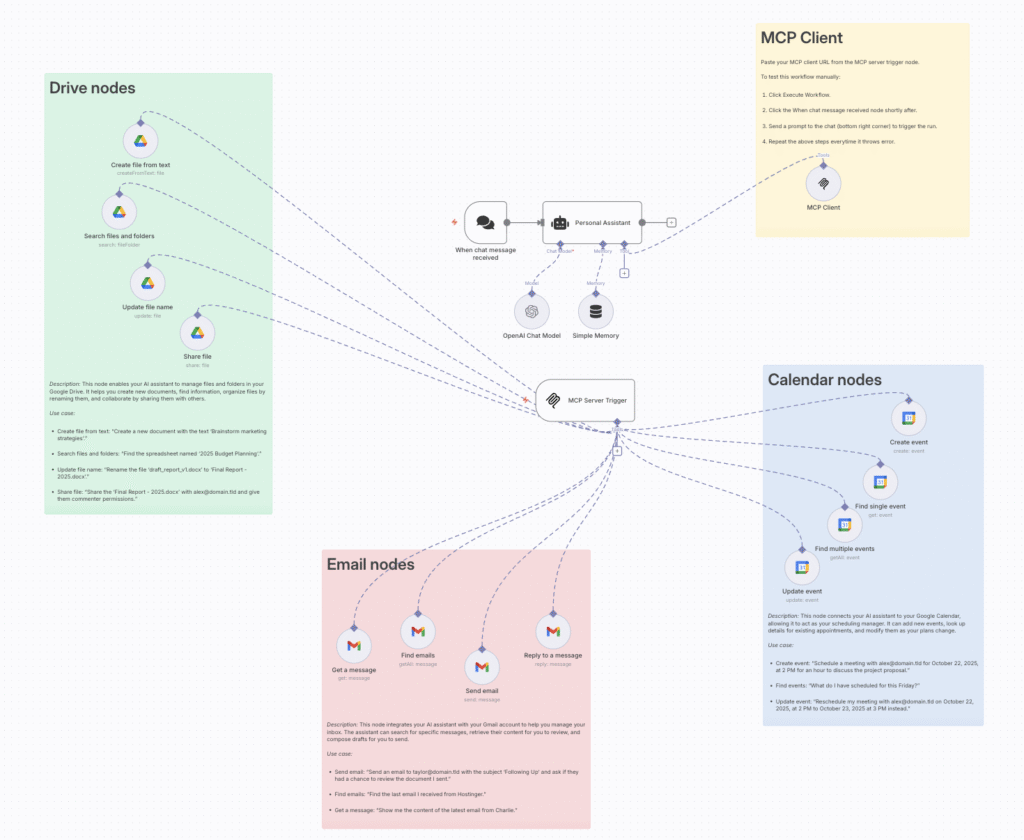
Com o canal de comunicação pronto, equipei meu assistente com as habilidades necessárias ao adicionar nós de ferramentas para cada funcionalidade desejada e conectá-los todos ao Gatilho do Servidor MCP.
O Gatilho do Servidor MCP atua como uma central para todas as habilidades do assistente. Qualquer nó ao qual eu me conecto torna-se uma ferramenta que o agente de IA pode escolher usar.
Para este projeto, dei ao meu assistente habilidades em três serviços principais:
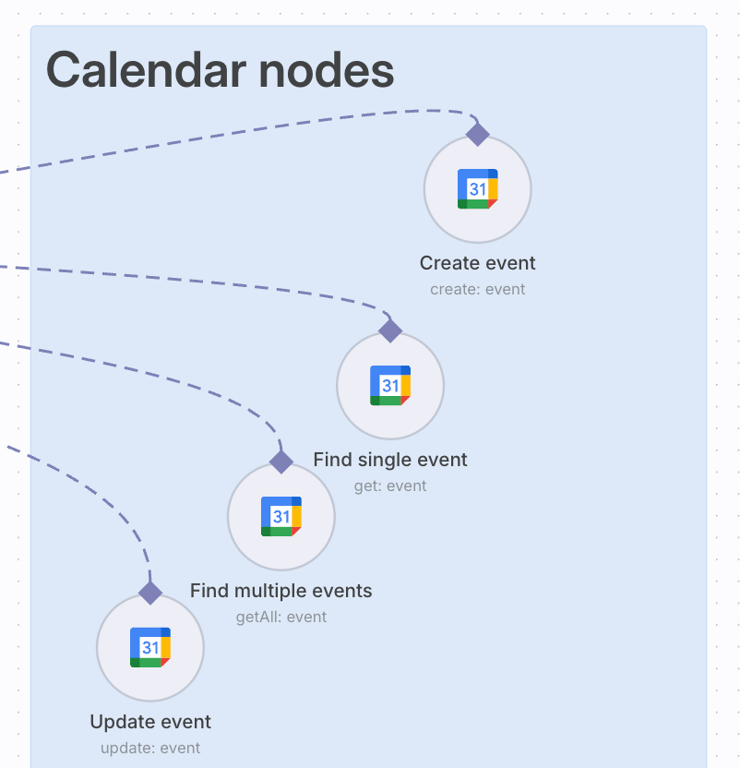
- Google Agenda. Adicionei vários nós de ferramenta do Google Agenda para ações como criar, atualizar e localizar eventos. Por exemplo, o nó Criar evento permite que o assistente agende novas reuniões.
- Gmail. Adicionei nós de ferramentas do Gmail para permitir que o assistente encontre, leia e envie e-mails. O nó Enviar e-mail, por exemplo, permite que ele envie mensagens em meu nome.
- Google Drive. Eu usei os nós da ferramenta Google Drive para gerenciar arquivos. Isso incluía nós para criar documentos a partir de texto, pesquisar arquivos e compartilhá-los.
Com todas as ferramentas no lugar, a tela principal do fluxo de trabalho agora está completa. É assim que se parece:
Passo 5: implementando um tratamento de erros robusto
O passo final na construção de um assistente confiável é planejar para falhas.
Em vez de adicionar uma lógica de erro complexa ao meu fluxo de trabalho principal, criei um fluxo de trabalho dedicado ao tratamento de erros focado em notificações e o vinculei ao meu fluxo de trabalho principal do assistente usando as configurações do n8n.
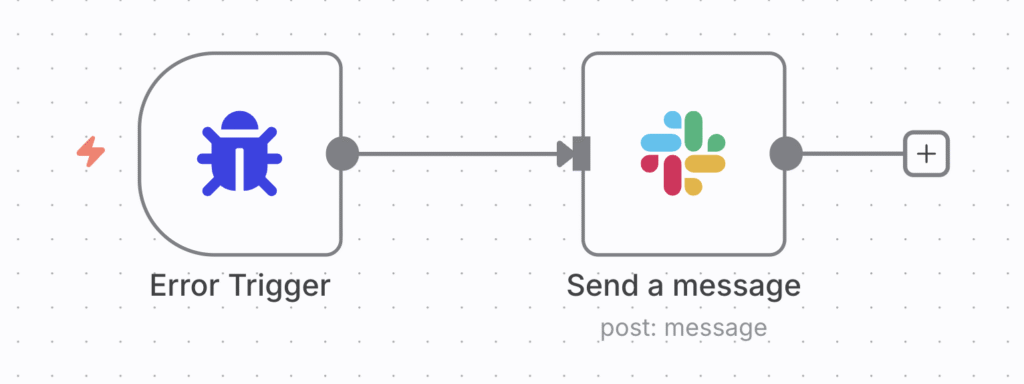
Meu fluxo de trabalho de erro é simples. Começa com um nó de Gatilho de Erro, um gatilho especial que é executado apenas quando outro fluxo de trabalho atribuído a ele falha.
Este gatilho se conecta a um nó do Slack configurado para enviar uma mensagem. Eu personalizei a notificação para incluir dados dinâmicos, como o nome do workflow, o nó que falhou e um link direto para o log de execução. Dessa forma, reúno todos os detalhes necessários para depurar o problema rapidamente.
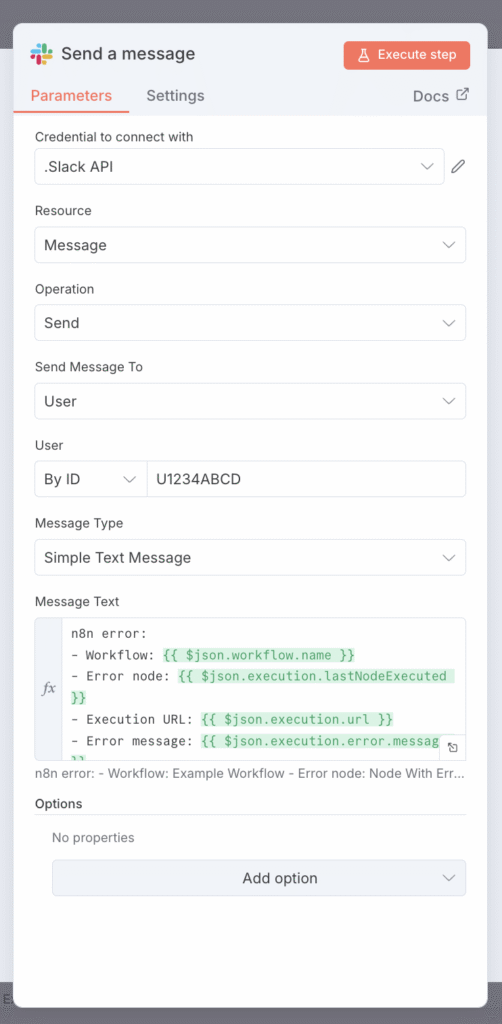
Usar o Slack para notificações é uma questão de preferência. Você pode substituir facilmente este nó por outro serviço. Por exemplo, você pode configurar uma integração do n8n com o Telegram para receber alertas ou seguir nosso guia sobre a integração do n8n com o WhatsApp para notificações.
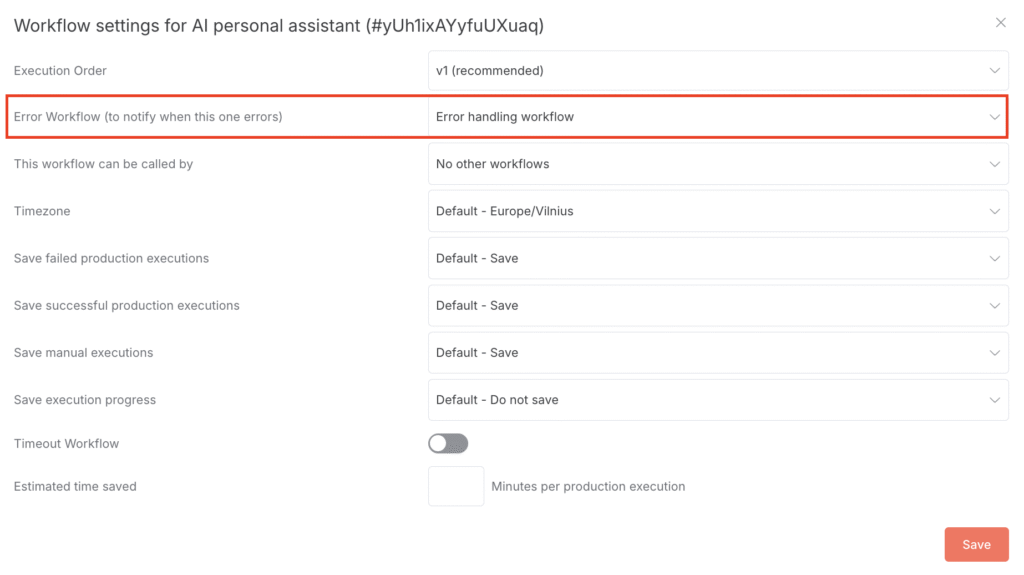
Após salvar o fluxo de trabalho de erro, a etapa final foi conectá-lo. Voltei para o meu fluxo de trabalho principal de Assistente Pessoal, abri o menu de Configurações, naveguei até o campo Fluxo de Trabalho de Erro e selecionei o novo fluxo de trabalho que eu tinha acabado de criar.
O que meu assistente pessoal pode fazer (demonstrações práticas)
Meu assistente pessoal de IA que utiliza o n8n agora pode executar fluxos de trabalho que lidam com tarefas de várias etapas que tradicionalmente exigem intervenção manual. Aqui estão alguns exemplos práticos do que ele pode fazer.
Importante! Como este fluxo de trabalho está sendo executado em modo de teste, você deve clicar no botão Executar Fluxo de Trabalho no editor do n8n antes de enviar cada comando na interface de chat. Se você não fizer isso, o gatilho não ficará ativo e você verá uma mensagem de erro 404 Not Found.
Caso de uso 1: agendamento de reuniões
Agendar reuniões muitas vezes envolve verificar minha agenda, encontrar um horário livre e, em seguida, criar um convite.
Este caso de uso demonstra como o assistente pode lidar com todo esse processo a partir de um único prompt de texto, poupando-me vários minutos de alternância de contexto.
- O comando:
Agende uma reunião com alex@domain.tld para o dia 22 de outubro de 2025, às 14h, com duração de uma hora, para discutir a proposta do projeto.
- O processo: Nos bastidores, o agente de IA entende a solicitação e aciona o nó de evento Criar no meu fluxo de trabalho, passando todos os detalhes necessários.
- O resultado: Um momento depois, recebo uma confirmação no chat. O evento é adicionado instantaneamente ao meu Google Agenda, e um convite é enviado para alex@domain.tld, que também aparecerá em sua agenda.

Caso de uso 2: pesquisa e criação de documentos
Este caso de uso mostra como o assistente pode atuar como um parceiro de pesquisa e redação. Em vez de eu ter que buscar informações e depois criar manualmente um documento para armazená-las, o assistente pode fazer isso em uma única etapa.
- O comando:
Pesquise o tema ‘O que é Geração Aumentada de Recuperação (RAG)?’ e crie um documento com base em suas descobertas.
- O processo: Ao receber este comando, o agente utiliza o conhecimento interno do LLM para gerar uma explicação sobre RAG. Em seguida, ele passa esse texto gerado diretamente para a ferramenta Criar arquivo a partir de texto, que o salva como um novo Documento Google.
- O resultado: o assistente responde no chat, confirmando que o documento foi criado e fornecendo um link direto para o novo arquivo. Isso me permite acessar o documento imediatamente sem ter que procurá-lo no Google Drive.

Caso de uso 3: redigir e enviar e-mails
Redigir e-mails de acompanhamento de rotina é outra tarefa que tira o meu foco. Esta demonstração mostra como posso delegar todo o processo ao assistente, desde a composição da mensagem até o seu envio.
- O comando:
Envie um e-mail para taylor@domain.tld com o assunto ‘Acompanhamento’ e pergunte se teve a chance de revisar o documento que enviei.
- O processo: O agente analisa este comando para identificar o destinatário, a linha de assunto e o corpo da mensagem. Em seguida, ele insere essas informações na ferramenta de envio de e-mail, que se conecta à minha conta do Gmail.
- O resultado: O assistente confirma que o e-mail foi enviado. Se eu verificar minha pasta de Enviados no Gmail, verei a nova mensagem, perfeitamente redigida e endereçada, sem que eu precise digitar uma única palavra na interface do Gmail.

Quais são as limitações do meu assistente pessoal de IA?
Embora este assistente n8n seja poderoso, é importante entender seus limites operacionais. Sua eficácia depende das ferramentas às quais está conectado e da qualidade do seu modelo de IA subjacente.
Dependências de API e ferramentas
A maior limitação do assistente é que sua funcionalidade depende inteiramente dos serviços de terceiros aos quais ele se conecta.
Meu fluxo de trabalho do n8n envia instruções para serviços externos como o Google Agenda e o Gmail; se esses serviços não estiverem funcionando, meu assistente não conseguirá realizar suas tarefas.
Isso cria dois riscos principais que estão fora do meu controle:
- Indisponibilidade do serviço. Por exemplo, se a API do Google Agenda estiver temporariamente indisponível devido a um problema por parte do Google, meu assistente não conseguirá agendar reuniões. Não há nada que eu possa fazer em meu fluxo de trabalho para resolver este problema; o recurso está indisponível no momento até que o serviço externo seja restabelecido.
- Alterações na API. Empresas ocasionalmente atualizam suas APIs para adicionar novos recursos ou melhorar a segurança. Às vezes, essas mudanças são “de ruptura”, o que significa que o nó de ferramenta do n8n que depende da versão antiga deixará de funcionar até que o nó seja atualizado.
Restrições do modelo de IA
O assistente é apenas tão inteligente e confiável quanto o LLM que o alimenta. Isso apresenta duas restrições principais:
- Escopo limitado. O agente de IA só pode realizar tarefas para as quais eu explicitamente lhe dei ferramentas. Por exemplo, não posso pedir que ele “reserve um voo” porque não lhe forneci uma ferramenta de reserva de voos. Ele só sabe usar as ferramentas específicas do Google Agenda, Gmail e Drive que eu conectei anteriormente.
- Confiabilidade do modelo. LLMs têm “limites de tokens”, que são a quantidade máxima de texto (entrada e saída) que eles podem processar de uma só vez. Para conversas muito longas, solicitações complexas em um único comando ou ao processar documentos extensos, o modelo pode perder o contexto e não funcionar corretamente. LLMs também podem, às vezes, “alucinar”, o que significa que afirmam informações incorretas com total confiança. O modelo pode inventar um detalhe para um evento ou interpretar mal um e-mail complexo.
Quais são as melhores práticas para o assistente de IA?
Para garantir que meu assistente pessoal funcione de forma segura, confiável e eficiente, sigo estas melhores práticas para criação de prompts, gerenciamento de credenciais e monitoramento de desempenho.
Engenharia de prompt eficaz
A chave para obter resultados confiáveis é a engenharia de prompt eficaz. Em vez de tratar a IA como um mecanismo de busca, eu a trato como um estagiário talentoso e dou a ela instruções claras e detalhadas no prompt do sistema.
Uma ótima maneira de estruturar estas instruções é com a estrutura CLEAR:
- Contexto. Eu forneço o contexto para a tarefa, incluindo o papel da IA e seu objetivo principal. Por exemplo:
Você é um assistente pessoal prestativo.
- Limitações. Eu estabeleço regras claras e defino o que o assistente não deve fazer. Por exemplo:
Você não deve realizar nenhuma ação além das fornecidas.
- Exemplos. Fornecer exemplos de solicitações de usuários ajuda o modelo a entender a intenção. Por exemplo, mostrar “o que tenho para sexta-feira?” significa que ele deve usar a ferramenta de busca no calendário.
- Ações. Eu listo explicitamente as ferramentas que a IA tem permissão para usar. Por exemplo:
Suas ferramentas disponíveis são o Google Agenda, o Gmail e o Google Drive.
- Refinamentos. Prompting é um processo iterativo. Eu testo o assistente e refino o prompt do sistema com base em seu desempenho para melhorar sua precisão ao longo do tempo.
Isso é abordado em mais detalhes no vídeo da Hostinger Academy abaixo.
[yt-inscrever-se] [/yt-inscrever-se]
Gerenciamento seguro de credenciais
Uma prática recomendada fundamental que sigo é nunca expor chaves de API diretamente no meu fluxo de trabalho. Em vez disso, eu sempre uso o gerenciador de credenciais integrado do n8n para armazená-las com segurança.
Isso evita que suas chaves sejam compartilhadas acidentalmente por meio de capturas de tela ou arquivos de exportação de fluxo de trabalho.
O n8n incentiva isso ao solicitar que você crie ou selecione uma credencial segura sempre que adicionar um nó que exija autenticação, mantendo o segredo real oculto.
Manutenção e monitoramento proativos
Uma automação só é útil se for confiável, portanto a manutenção proativa é essencial. Minhas duas principais práticas são:
- Eu verifico regularmente os logs de execução. Isso fornece um histórico de cada execução do fluxo de trabalho e é inestimável para identificar comportamentos inesperados ou erros que podem não acionar uma notificação de falha completa.
- Eu mantenho minha instância do n8n e seus nós atualizados. Isso garante que eu receba patches de segurança, correções de bugs e proteção contra falhas causadas por mudanças em APIs de terceiros. Se você hospeda o n8n por conta própria no VPS da Hostinger como eu, pode seguir este guia sobre como atualizar o n8n.
Como você pode aprimorar seu assistente de IA?
Esta versão inicial oferece uma base sólida, mas você pode expandir ainda mais suas capacidades. Aqui estão algumas ideias para levar seu assistente ao próximo nível:
- Adicionar memória de longo prazo. A memória atual dura apenas uma única sessão. Para dar ao assistente uma memória permanente, você pode conectar um nó de banco de dados (como Redis ou Postgres) para armazenar o histórico de conversas. Você também pode explorar a Geração Aumentada por Recuperação (RAG) para fornecer à IA contexto adicional de seus próprios documentos, como listas de contatos ou notas de projeto.
- Integrar mais ferramentas. O verdadeiro poder deste assistente vem de sua capacidade de personalização. Você pode adicionar nós de ferramenta para qualquer serviço com uma API. Considere conectá-lo a aplicativos de gerenciamento de projetos como o Notion para gerenciar tarefas, ou até mesmo a ferramentas financeiras para acompanhar despesas.
- Configure um GPT personalizado. Para uma interface de usuário mais refinada, você pode configurar um GPT personalizado no ChatGPT. Ao configurar sua Action para apontar para a URL do Chat Trigger do seu n8n, você pode interagir com seu assistente diretamente da interface do ChatGPT, em vez do dashboard do n8n.
- Use modelos de IA locais. Para maior privacidade e para aproveitar plenamente a automação de código aberto, você pode substituir o nó da OpenAI por um modelo auto-hospedado. Uma ferramenta como o Ollama permite que você execute modelos de linguagem poderosos diretamente em seu próprio servidor, mantendo seus dados completamente privados.
- Implementar comandos de voz. Para tornar o assistente hands-free, você pode adicionar um serviço de transcrição no início do seu fluxo de trabalho. Por exemplo, um nó que utiliza a API Whisper da OpenAI poderia transcrever um arquivo de áudio ou uma nota de voz em texto, que é então passado ao agente como um comando.
Principais pontos
Construir este projeto me mostrou que combinar a automação flexível do n8n com o protocolo de comunicação robusto do MCP é o que torna os verdadeiros agentes de IA possíveis. É a diferença entre um script simples e um sistema que pode raciocinar e agir em meu nome.
Espero que este guia sobre como construir um assistente pessoal no n8n usando MCP forneça a você o fluxo de trabalho e o conhecimento fundamental para começar a construir o seu próprio.
Agora, qual é a primeira tarefa repetitiva que você vai automatizar com seu novo assistente?
Todo o conteúdo dos tutoriais deste site segue os rigorosos padrões editoriais e valores da Hostinger.

Bruno is a Content Writer at Hostinger, focused on creating and optimizing helpful, engaging articles about web development and marketing. With a background in journalism, he combines storytelling with practical insights to make complex topics easier to understand. He has also contributed to publications like MacMagazine and Jornal A Tarde. Outside of work, Bruno enjoys exploring art, cooking, and technology.

Comentários
0 responses