Benchmarks n8n: testando o uso real de recursos da ferramenta
Mar 10, 2026
/
Bruno S.
/
12 min Ler
Se você está hospedando o n8n por conta própria, provavelmente já se fez a mesma pergunta que eu: quantos recursos do servidor meus workflows do n8n realmente consomem?
Afinal, garantir recursos suficientes é essencial para manter um bom desempenho. Ao mesmo tempo, ninguém quer gastar mais do que o necessário em CPU ou memória que acabarão ficando ociosas.
Se você pesquisar online, encontrará recomendações diferentes – como usar um processador com um núcleo e 2 GB de RAM. Mas isso levanta algumas dúvidas práticas:
- Será que eu realmente preciso de tudo isso para um workflow simples?
- Se eu rodar dois workflows, preciso de um servidor duas vezes mais potente?
- O uso de recursos do n8n é previsível em cenários reais?
Para responder a essas perguntas, realizei uma série de benchmarks n8n em cenários reais, medindo o consumo de CPU, memória RAM e rede de diferentes workflows do n8n em condições variadas.
Adiantando as principais conclusões
Antes de entrarmos nos detalhes mais específicos, aqui estão os principais pontos que tirei do meu teste:
- O consumo de recursos depende do nó. Nós que interagem com fontes externas, como o nó de requisição HTTP, consomem mais recursos de E/S de rede do que nós que executam tarefas localmente. No entanto, a RAM é o recurso dominante em praticamente todos os nós, internos ou externos.
- A escala é, em certa medida, linear. Executar vários fluxos de trabalho idênticos geralmente resulta em uma escalabilidade aproximadamente linear. Ao introduzir variedade de nós, o uso de recursos torna-se muito menos previsível.
- Atrasos não reduzem o pico de uso. Adicionar um intervalo entre as execuções dos nós não afeta o pico de uso. No entanto, isso permite distribuir a alocação de recursos ao longo do tempo, dando espaço para outros fluxos de trabalho.
- Executar fluxos de trabalho em paralelo versus sequencialmente. Não há diferença significativa no pico de utilização de hardware entre a execução de fluxos de trabalho em paralelo e sequencialmente.
- O modo de fila n8n não é nenhum segredo. Habilitar o modo de fila n8n praticamente dobra o uso básico de RAM, mesmo em modo ocioso. Não reduz o consumo máximo em configurações pequenas e só faz sentido em grande escala.
Metodologia dos benchmarks n8n
Este teste de desempenho se concentrará na utilização máxima de CPU, RAM e E/S de rede do servidor host.
Vale ressaltar que existem outros benchmarks n8n. Por exemplo, a publicação do blog n8n Scalability Benchmark examina como a plataforma lida com um grande volume de solicitações, com foco em métricas como taxa de falhas e tempo de resposta.
No entanto, em vez de um benchmark sintético e controlado, concentrei-me na utilização máxima de recursos em cenários práticos de automação no mundo real.
Dica de especialista
Se você não tem certeza de qual plano VPS da Hostinger melhor se adapta às suas necessidades, comece com o KVM 2 – ele oferece uma base sólida e pode ser atualizado instantaneamente com um único clique à medida que suas necessidades aumentam.

Vamos explorar a metodologia com mais detalhes, começando por compreender o ambiente de teste.
Ambiente de teste e ferramentas utilizadas no benchmark n8n
Segue abaixo a configuração que utilizei para executar os testes de benchmark n8n:
- Servidor: plano Hostinger VPS KVM 2
- Sistema operacional: Ubuntu Linux 24.04 LTS
- Ferramenta btop para monitoramento, Docker para executar o n8n em um contêiner.
Escolhi o Hostinger KVM 2 porque oferece recursos suficientes sem ser excessivamente caro. Com dois núcleos de vCPU, 8 GB de RAM e 100 GB de armazenamento SSD NVMe, oferece ampla margem de segurança caso os testes exijam.
Quanto ao sistema operacional, escolhi o Ubuntu 24.04 LTS simplesmente por ser estável, fácil de usar e popular. Se você usar uma distribuição mais minimalista, poderá haver pequenas diferenças de desempenho, mas nada que comprometa significativamente a experiência do usuário.
Eu implementei o n8n no Docker. Essa é a abordagem de auto-hospedagem recomendada e, com o modelo VPS da Hostinger, instalar o n8n em um contêiner leva apenas alguns cliques. Eu também configurei o modo de fila n8n usando o modelo da Hostinger e suas configurações padrão predefinidas.
Pensando no overhead do Docker? 🐳
O Docker tem desempenho próximo ao nativo, já que compartilha o kernel do host. Na prática, a sobrecarga é insignificante em comparação com a execução do n8n diretamente no host.
Para monitoramento, utilizei o btop por ser simples e suficiente para coletar dados para este teste de desempenho. Também fornece um gráfico que simplifica o processo de monitoramento.
Cenários de teste e métricas analisadas
Para executar o teste de desempenho, realizei cada um dos seguintes testes em intervalos de 2 segundos durante vários minutos para garantir a consistência dos dados. Em alguns cenários, aumentei o intervalo para evitar os limites de taxa da API.
Para cada teste, registrei os valores de pico para:
- utilização da CPU
- consumo de RAM
- E/S de rede
Teste 1: benchmark por node
Este teste isolou nodes individuais para responder à questão:
- Quanta CPU, RAM e largura de banda de rede um nó consome?
- Os nós que interagem com serviços externos requerem mais recursos do que aqueles que são executados independentemente dentro do n8n?
- O consumo de recursos aumenta linearmente com o número de nós?
Importante! Para simplificar, chamarei de nós externos os nós que requerem interação com serviços externos e de nós internos aqueles que são executados independentemente dentro do n8n.
Teste 2: benchmark de workflow único
Este teste se concentra em fluxos de trabalho completos:
- Fluxo de trabalho simples com dois nós internos.
- Fluxo de trabalho complexo com sete nós internos
- Fluxo de trabalho complexo com um total de sete nós, uma combinação de nós internos e externos.
- Efeito da adição de atrasos na execução
Teste 3: múltiplos workflows na mesma instância
Este teste analisou:
- O consumo de CPU, RAM e tráfego aumenta linearmente com o número de fluxos de trabalho idênticos?
- O consumo de recursos é previsível com base no número e tipo de fluxos de trabalho em execução?
- A alternância entre a execução de múltiplos fluxos de trabalho é uma estratégia viável para minimizar picos de consumo de recursos?
Teste 4: benchmark do queue mode
Queria verificar o impacto do modo de fila n8n no consumo de recursos de um fluxo de trabalho:
- O modo de fila n8n ajuda a minimizar a utilização de CPU, RAM e rede? Se sim, em quanto?
- Quais são as desvantagens de usar o modo de fila n8n, se houver?
- O modo de fila n8n é uma opção viável para executar fluxos de trabalho em um sistema de baixo custo?
Entre os testes, esperei até que o uso de recursos retornasse a um nível próximo ao normal para evitar resultados distorcidos.
Importante! Durante meus testes, houve casos em que o uso de RAM em modo ocioso divergiu significativamente da linha de base inicial. Neste caso, normalizei o valor para garantir que o resultado fosse consistente. Subtraí o novo valor de referência do valor inicial e, em seguida, adicionei a diferença ao resultado do teste de desempenho da RAM. Por exemplo, se a linha de base inicial for de 800 MB e a nova for de 824 MB, a diferença será de -24. Isso significa que um uso de RAM de 900 MB será normalizado para 876 MB.
Limitações e ressalvas para o benchmark
Este teste comparativo visa refletir o uso real dos fluxos de trabalho n8n, mas diversos fatores influenciam os resultados:
- Variação do nó. Existem centenas de nós n8n com comportamentos diferentes, que podem consumir recursos de maneira distinta daqueles que testei.
- Ambiente de hospedagem. O ambiente de hospedagem e a configuração que utilizo para implantar o n8n são relativamente minimalistas. Você poderá experimentar uma sobrecarga de desempenho maior ou menor, dependendo do tipo de servidor, sistema operacional ou método de implantação que utilizar.
- Lógica de fluxo de trabalho. Os fluxos de trabalho neste benchmark são simples e não envolvem lógica complexa. Se seus fluxos de trabalho processam grandes quantidades de dados ou arquivos, espere uma maior utilização de recursos.
- Escala de implantação. Eu utilizo fluxos de trabalho com menos de 10 nós para executar o teste. Utilizar mais nós aumenta o consumo de recursos.
Com isso em mente, vamos alinhar nossas expectativas: este teste não é uma solução universal que determina o requisito mínimo exato de hardware para o seu fluxo de trabalho n8n.
A sua experiência pode variar dependendo do uso e da configuração do equipamento. Em vez de usar o resultado do teste como padrão, considere-o como um guia para entender o comportamento real do n8n, o que ajudará você a planejar melhor seu ambiente de hospedagem e sua estratégia de escalonamento.
Resultados dos benchmarks n8n
Aqui está o resultado do meu teste de benchmarks n8n com diferentes cenários de teste.
Benchmark n8n em nível de node
Antes de executar qualquer nó, verifiquei o consumo de recursos do servidor em estado ocioso para estabelecer uma linha de base.
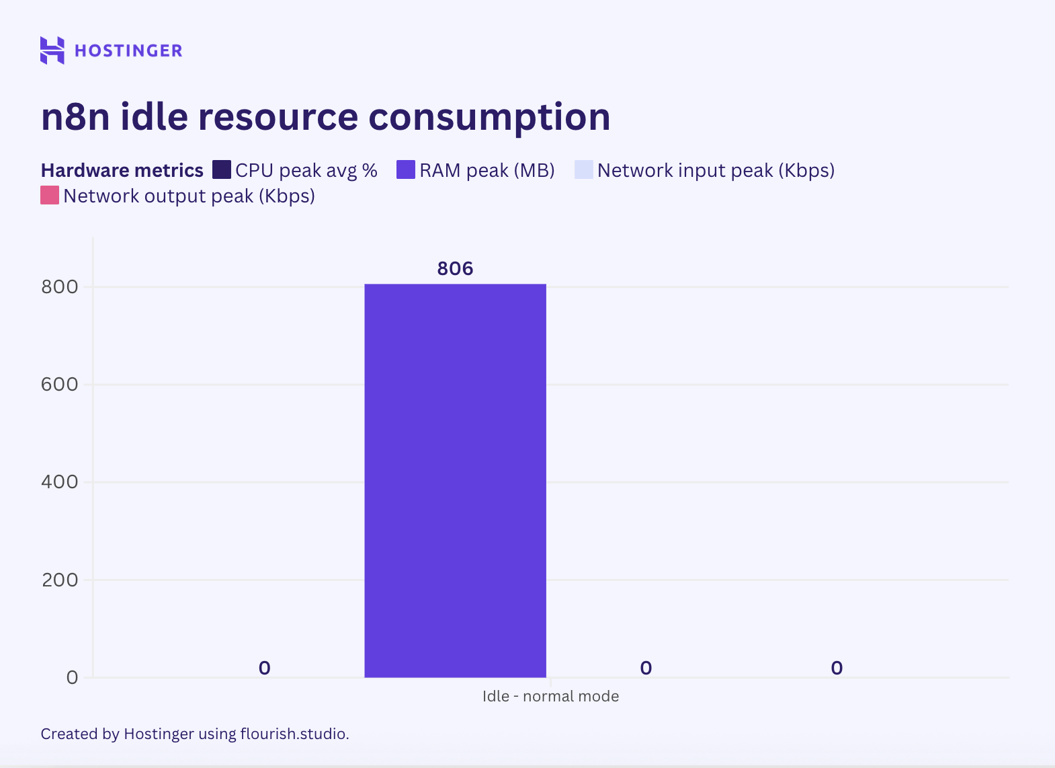
Sem nenhum nó ou fluxo de trabalho ativo, o n8n consumiu 0% da CPU e 860 MB de RAM. A E/S de rede atingiu apenas alguns bytes ou um dígito de kilobytes, então a normalizei para zero por ser insignificante.
Em seguida, executei o teste com estes fluxos de trabalho:
- Um fluxo de trabalho com um único nó interno do Code que gerou 1.000 números decimais aleatórios usando JavaScript.
- Um fluxo de trabalho com dois nós internos de código idênticos, ambos gerando 100 números decimais aleatórios.
- Um fluxo de trabalho com um único nó “Obter Linha” do Google Sheets que buscava dados de uma coluna de uma planilha.
- Um fluxo de trabalho com dois nós do Google Sheets, um para extrair dados e outro para gravar dados.
O consumo de recursos para todos os testes, em comparação com o estado ocioso, é o seguinte:
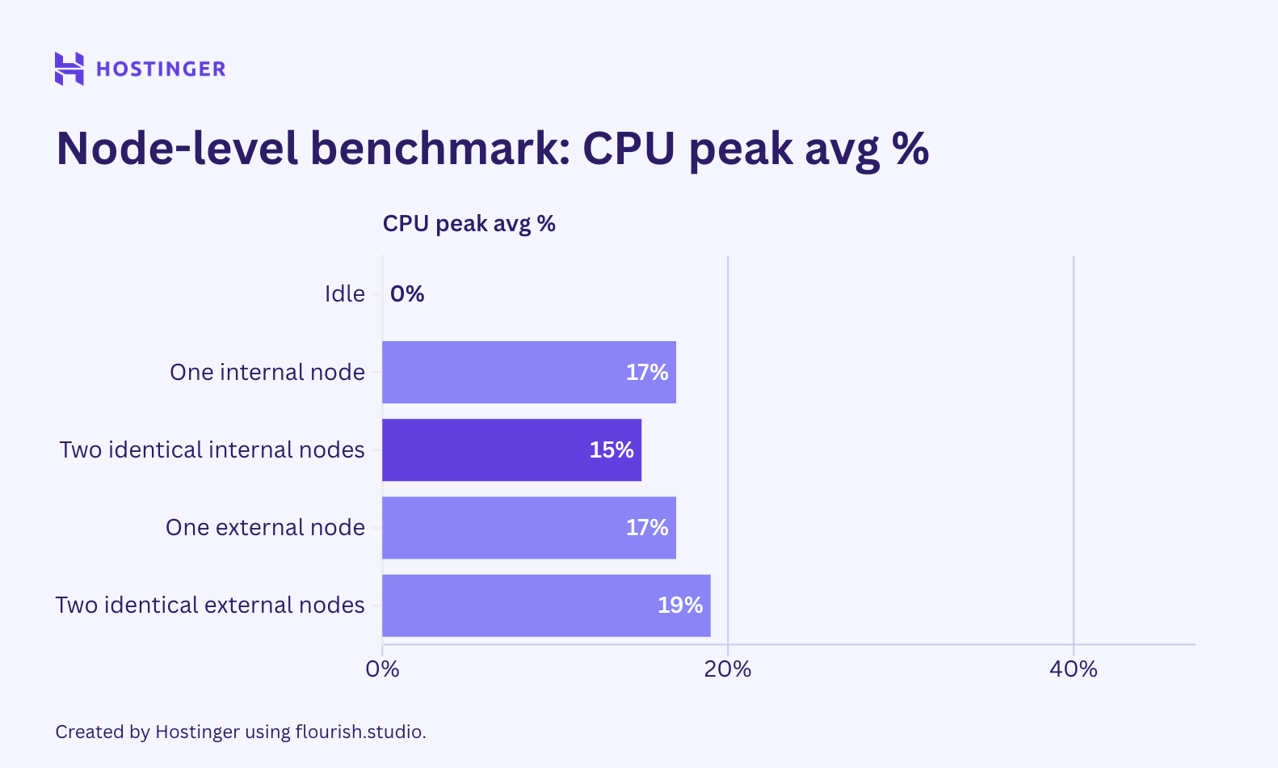
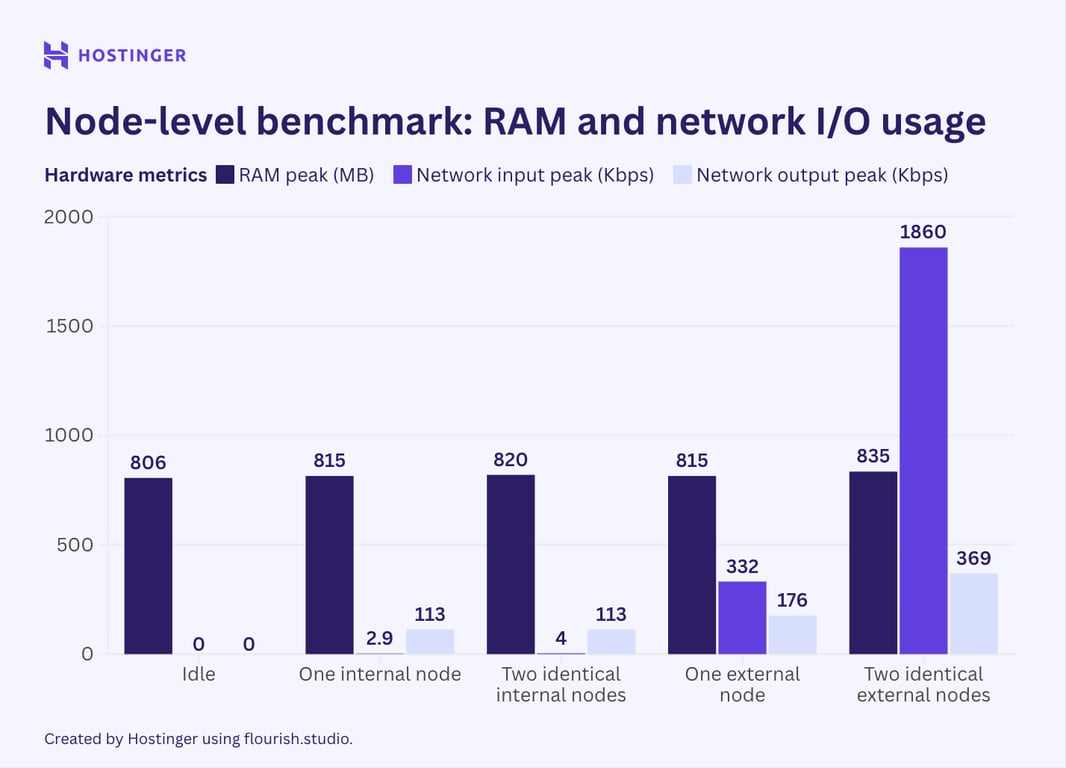
Os resultados foram os esperados: o consumo de recursos aumentou quando adicionei mais nós. Dito isso, o comportamento de escala não foi linear nem previsível.
Por exemplo, um nó interno aumentou o uso de RAM em 9 MB em relação ao estado ocioso. Ao inserir o mesmo nó, no entanto, a utilização de memória aumentou em 5 MB. Esse comportamento também foi observado nos nós externos.
No que diz respeito aos nós externos, eles de fato impunham uma carga de E/S de rede maior, chegando a ser até 10 vezes maior que a dos nós internos. O uso da rede também aumentou significativamente quando adicionei o segundo nó externo, ao contrário da CPU e da RAM.
Benchmark n8n para um único fluxo de trabalho
Após entender o comportamento do nó isoladamente, quis verificar como um fluxo de trabalho real se comporta. Segue uma lista dos fluxos de trabalho que utilizei:
- Fluxo de trabalho simples com dois nós internos exclusivos para gerar 100 números inteiros aleatórios e calcular a média.
- Fluxo de trabalho complexo com sete nós internos exclusivos para gerar dados aleatórios e executar diversas operações, como normalização.
- Fluxo de trabalho simples com dois nós externos distintos que buscam dados de uma planilha do Google e os gravam em outro documento.
- Fluxo de trabalho complexo com sete nós internos e externos exclusivos, cuja tarefa é obter dados de VPS via API, filtrá-los com base em regras e registrá-los em uma planilha do Google quando os critérios forem atendidos.
Aqui estão os resultados para todos os cenários de teste acima:
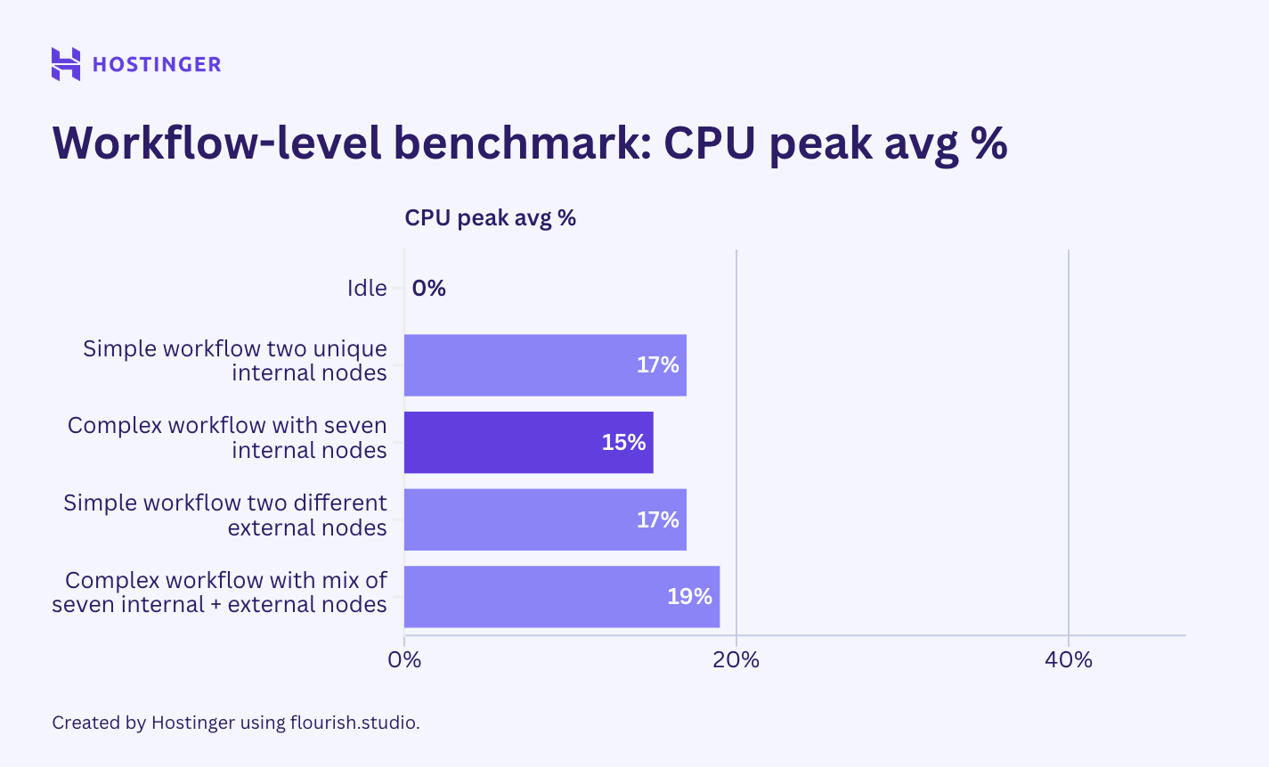
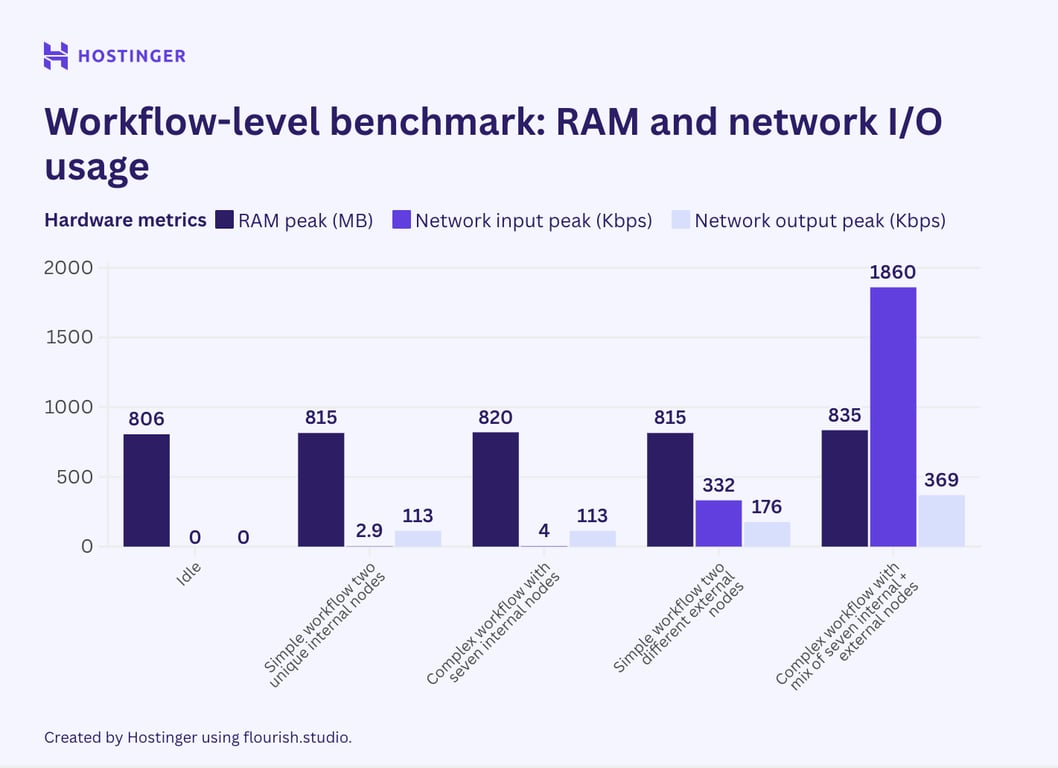
Os resultados mostram que adicionar um novo nó exclusivo aumentará o consumo de recursos mais do que inserir um nó idêntico. Isso é comum tanto em fluxos de trabalho simples quanto complexos, sugerindo que a utilização de recursos de um fluxo de trabalho depende da variedade de seus nós.
O comportamento de consumo de recursos neste segundo teste também parece consistente com o nosso teste em nível de nó: nós externos afetam significativamente a utilização de E/S da rede, enquanto os internos não.
Em seguida, adicionei um atraso de 2 segundos usando o nó Wait nos fluxos de trabalho complexos para verificar se a interrupção da execução reduz o consumo de recursos.
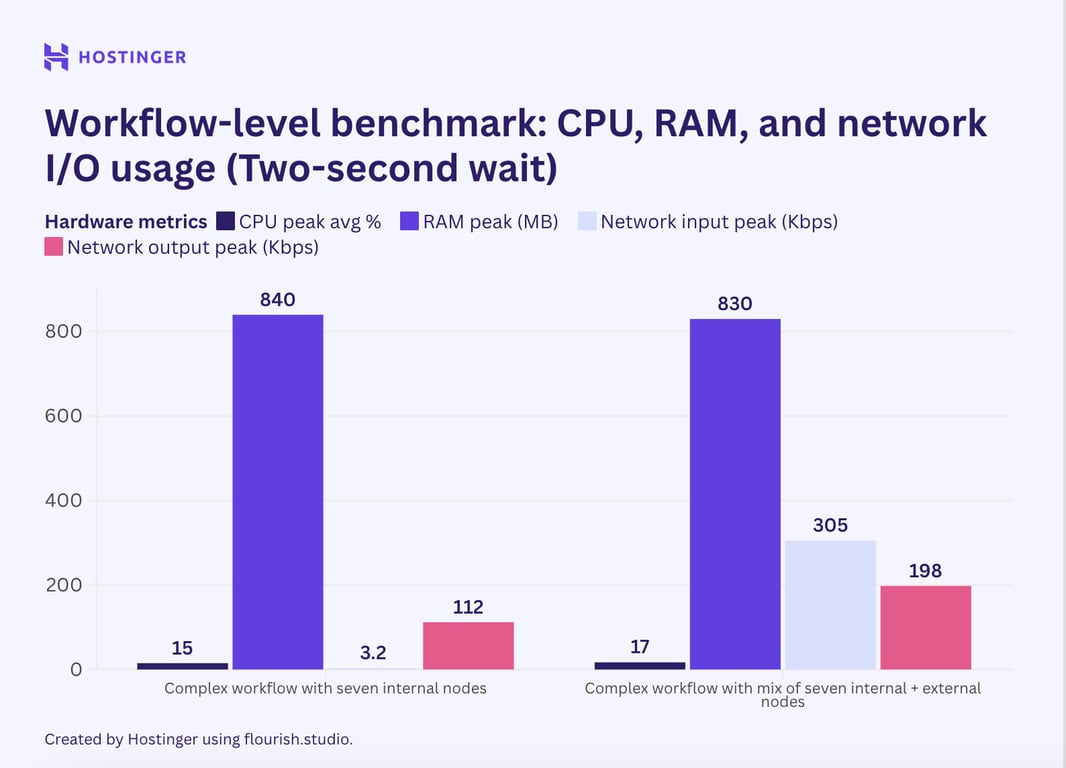
O pico de consumo diminuiu ligeiramente, mas podemos afirmar com segurança que a diferença é insignificante. Dito isso, o intervalo ajuda a liberar recursos em um momento específico, como mostra este gráfico.
Benchmark n8n para múltiplos workflows
Neste teste, executei várias instâncias dos mesmos quatro fluxos de trabalho usados na seção anterior. Eis o cenário:
- Executar duas instâncias do mesmo fluxo de trabalho em paralelo. Adicionei mais uma instância, caso os recursos e o limite de requisições da API permitissem.
- Alternar a execução de fluxos de trabalho idênticos por meio da execução dos subnós. Em outras palavras, após a conclusão do primeiro fluxo de trabalho, a segunda instância é executada.
- Executar diferentes fluxos de trabalho em paralelo. Executei um fluxo de trabalho interno simples em paralelo com um fluxo de trabalho complexo.
Vamos começar por verificar os resultados dos testes do primeiro cenário, focando-nos nos fluxos de trabalho simples com dois nós:
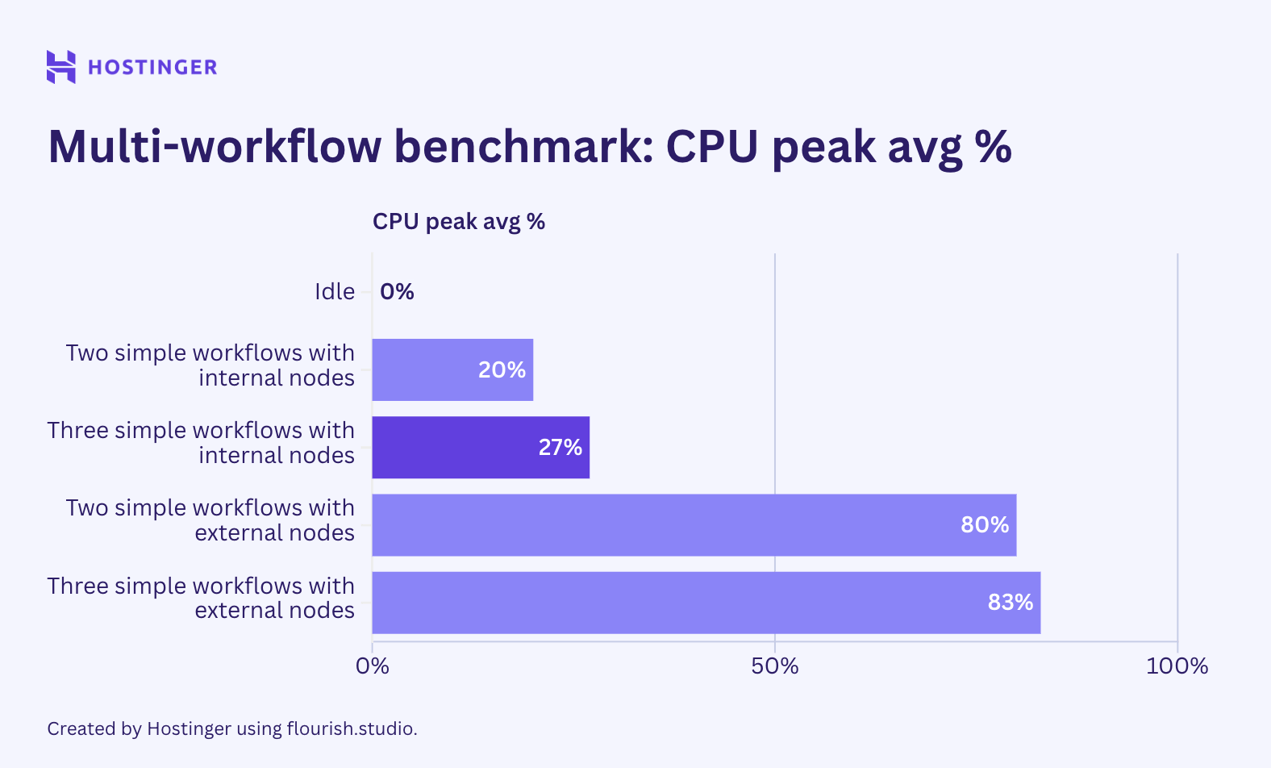
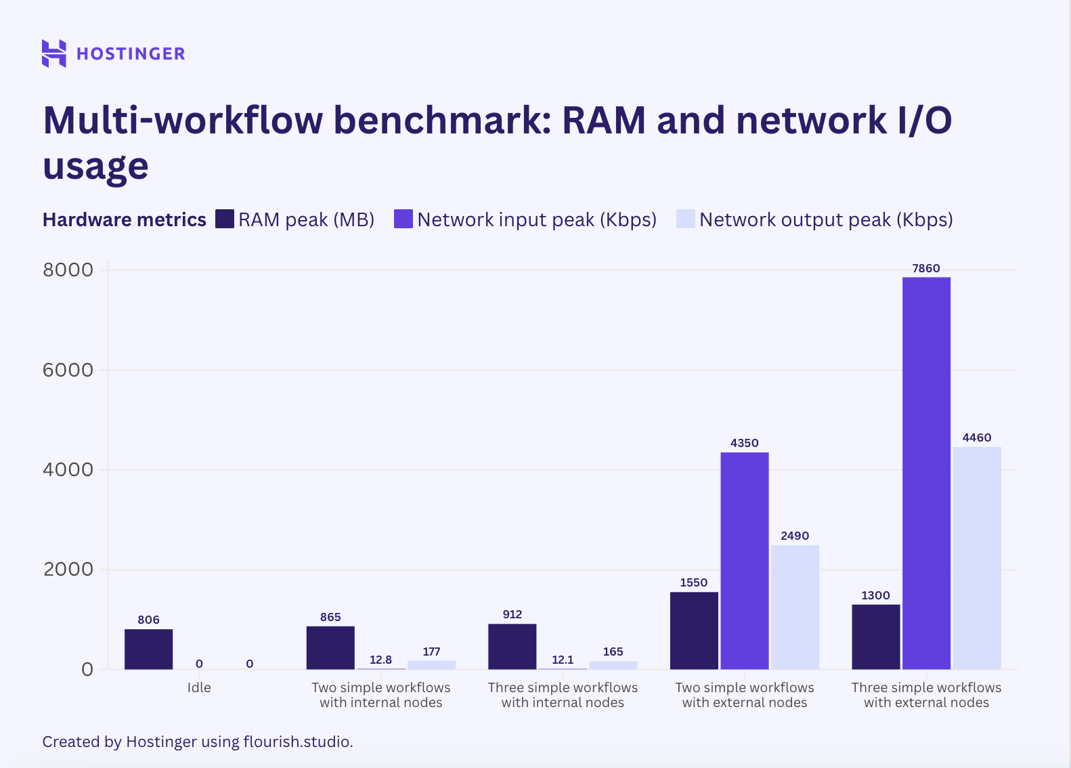
Aconteceu um caso interessante. Para fluxos de trabalho simples com nós internos, o uso de recursos foi de certa forma previsível:
- Uma das execuções atingiu um pico de 17% de carga da CPU e 815 MB de RAM.
- Duas execuções atingem um pico de 20% de carga da CPU e 865 MB de RAM.
- Três execuções atingem um pico de 27% de carga da CPU e 912 MB de RAM.
Com base na análise, uma execução adicional do fluxo de trabalho adicionou aproximadamente 40 a 50 MB de uso de RAM, e o uso da CPU aumentou de forma um tanto linear.
Entretanto, os fluxos de trabalho simples com nós externos apresentaram comportamento de uso e escalabilidade imprevisível. A diferença na utilização de recursos ao executar uma, duas e três instâncias é aleatória, apesar de apresentar uma tendência de alta.
Agora, vejamos como se comportaram os fluxos de trabalho complexos com sete nós:
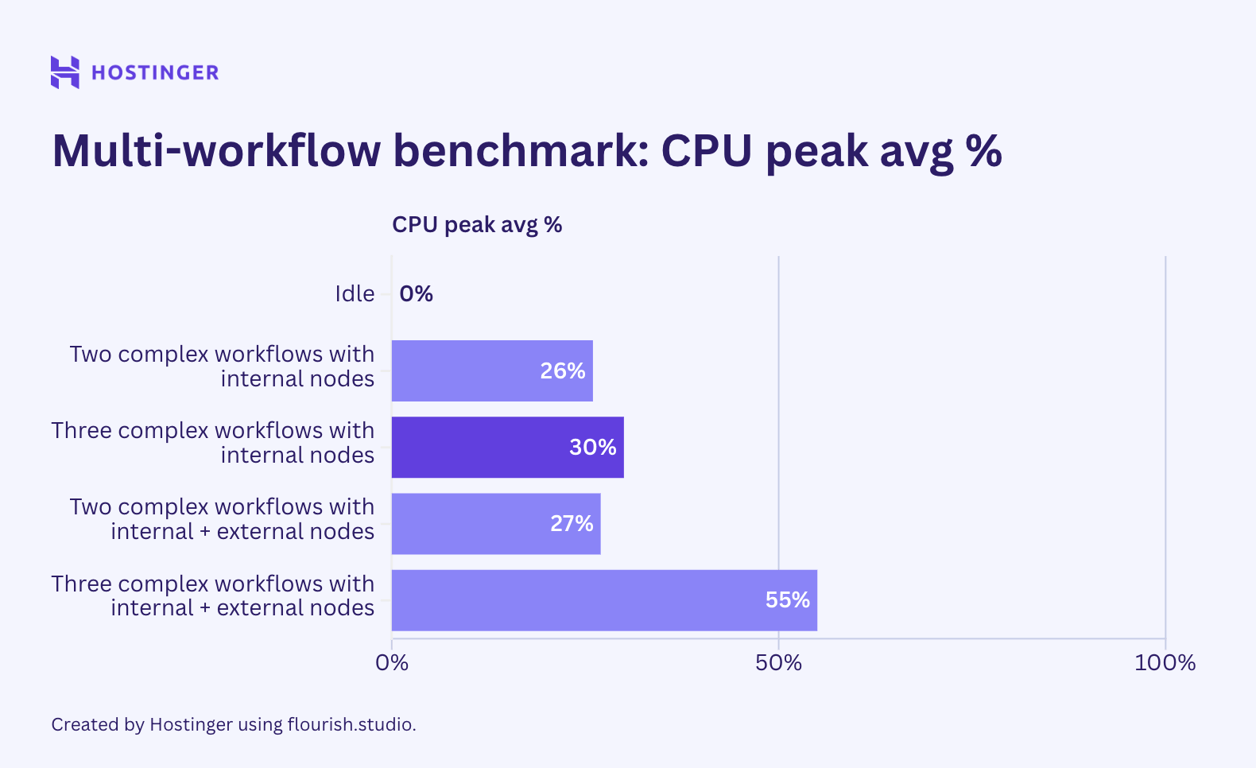
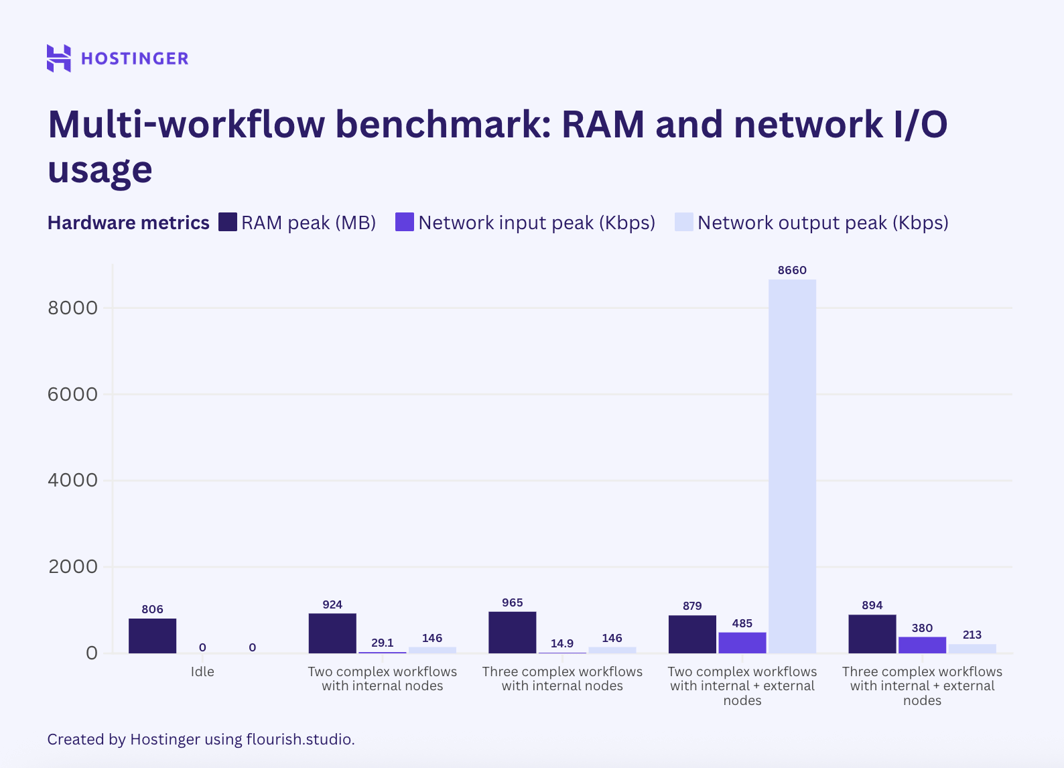
O comportamento do fluxo de trabalho simples foi consistente. A utilização de fluxos de trabalho com nós internos foi relativamente linear e previsível. Entretanto, os fluxos de trabalho com uma combinação de nós internos e externos apresentaram utilização flutuante, inclusive na E/S de rede.
No segundo cenário, encadeei dois fluxos de trabalho idênticos usando o nó de execução de subfluxo de trabalho. Isso me permitiu executá-las em uma ordem alternativa. O resultado é o seguinte:
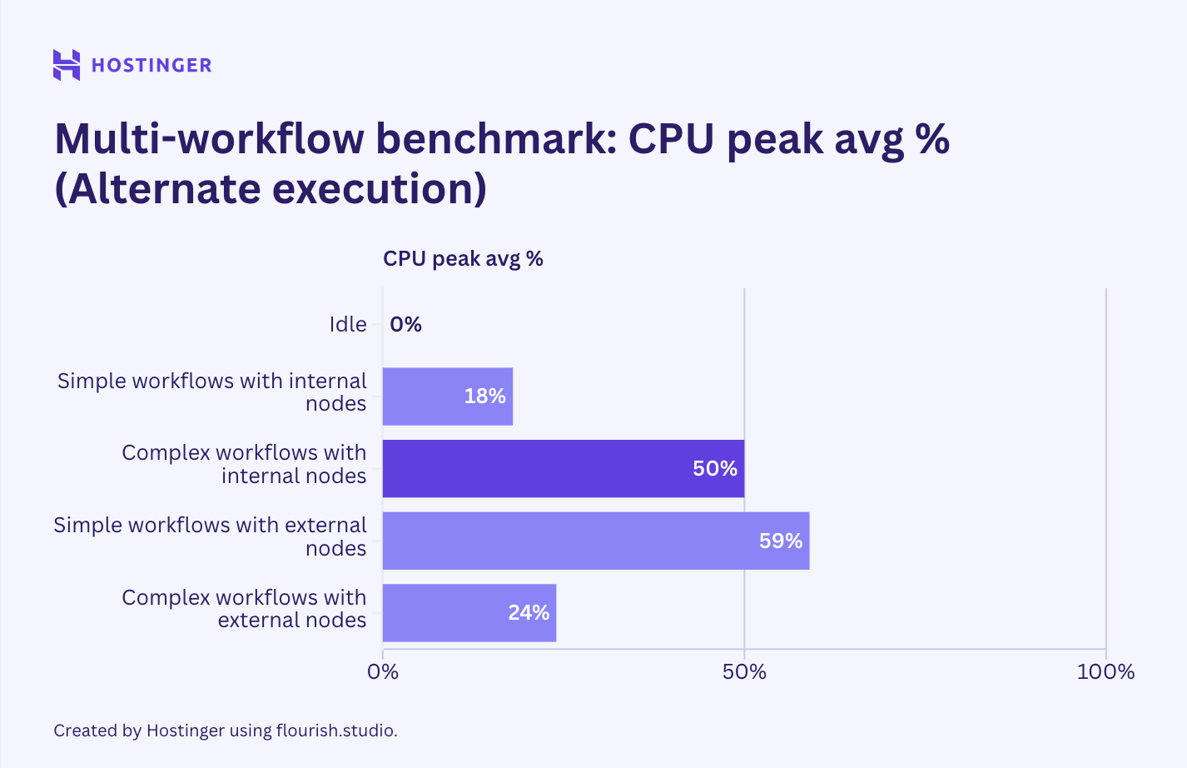
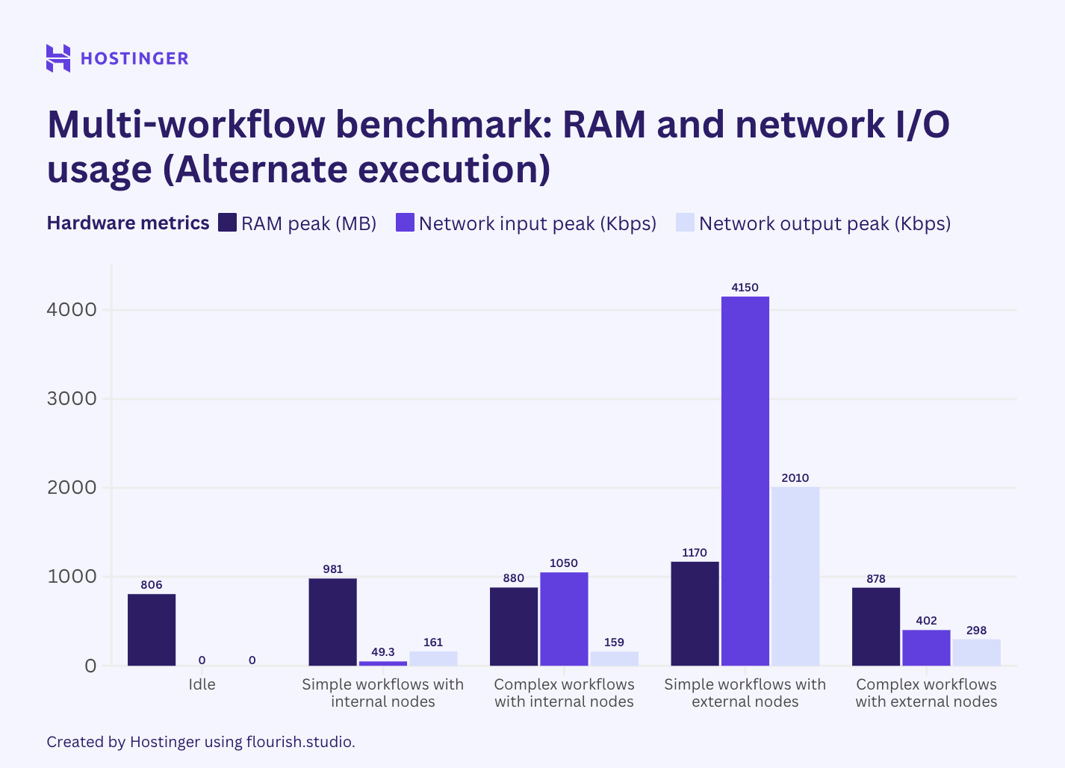
Como podemos ver, a utilização permaneceu relativamente inalterada. No entanto, a utilização da CPU para fluxos de trabalho internos complexos quase dobrou quando executados em ordem linear em comparação com a execução em paralelo.
Da mesma forma, a saída de rede dos fluxos de trabalho externos, quando executados em ordem linear, apresentou uma queda significativa em comparação com a execução em paralelo.
O que esses resultados nos dizem? 💬
Além dos dois casos mencionados, a utilização de hardware de fluxos de trabalho executados em paralelo e em ordem linear não é tão diferente. A menor produção de rede da execução alternativa pode ser devido ao fluxo de trabalho atingir o limite de taxa da API, o que significa que não há dados para trocar. A menor entrada de rede, embora não tão significativa, também indica um problema de limite de taxa. Não consigo encontrar uma explicação plausível para o fato de a execução alternativa resultar em um aumento de quase 100% no uso da CPU. Dado que todos os outros testes mostram que a utilização da CPU permanece a mesma ou ligeiramente inferior quando os fluxos de trabalho são executados em ordem linear, isto pode ser uma anomalia.
Em seguida, testei o terceiro cenário executando um fluxo de trabalho interno simples em paralelo com um fluxo de trabalho interno complexo.
Conforme discutido anteriormente, um fluxo de trabalho interno simples consumiu aproximadamente 50 MB de RAM e 7% da utilização da CPU. Em comparação, um fluxo de trabalho interno complexo aumentou o uso da CPU em cerca de 4% e exigiu 40 MB adicionais de RAM.
Se o uso do n8n fosse linear, executar esses fluxos de trabalho em paralelo aumentaria o uso da CPU em aproximadamente 11% e utilizaria 90 MB adicionais de RAM. No entanto, isso não ocorreu, como mostram os resultados dos meus testes:
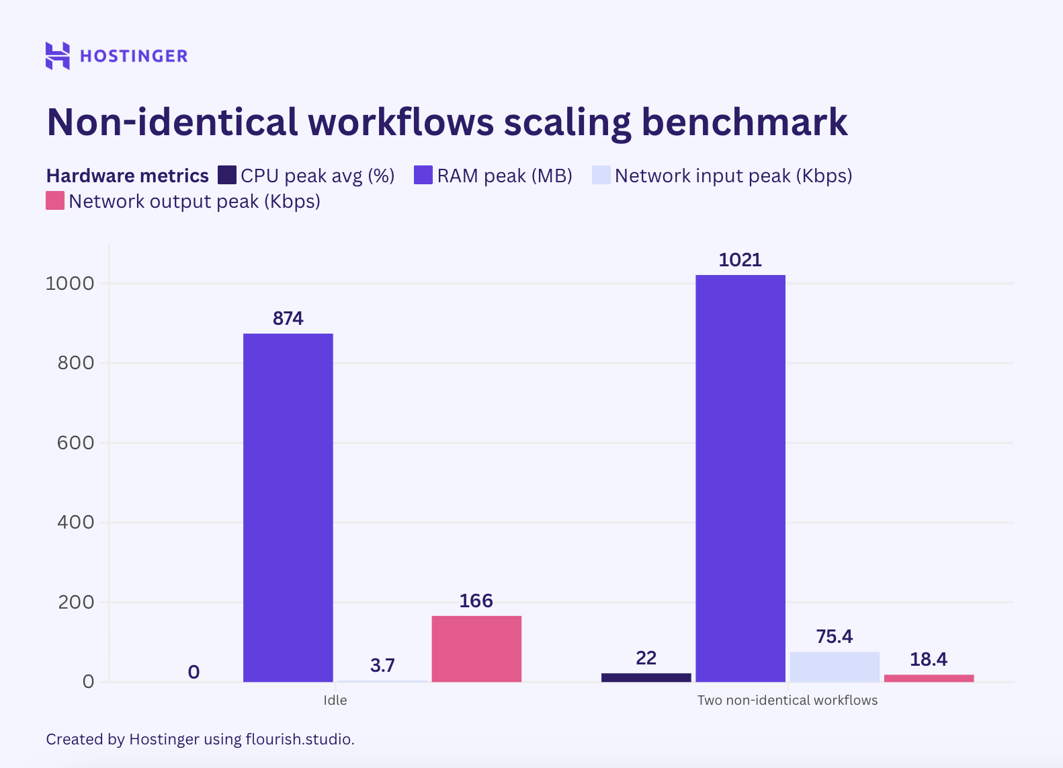
Com base nesses dados, duvido que possamos prever o pico de utilização de recursos em vários fluxos de trabalho diferentes. Para fluxos de trabalho idênticos, ainda é possível prever a utilização do hardware, desde que o nó não varie significativamente.
Teste de desempenho n8n com queue mode
O modo de fila n8n distribui suas tarefas de automação entre vários trabalhadores. Isso permite que cada processo seja executado independentemente da instância principal do n8n, ajudando a descarregar tarefas e a melhorar a escalabilidade.
Teoricamente, o modo de fila deve melhorar a estabilidade da sua automação ao executar um grande número de fluxos de trabalho. Com isso em mente, quis executar novamente os fluxos de trabalho anteriores no modo de fila para verificar se a utilização de recursos difere. Os cenários de teste são:
- Executando um fluxo de trabalho simples com dois nós internos distintos. Em seguida, executei uma nova instância do mesmo fluxo de trabalho em paralelo, até três execuções simultâneas.
- Executar um fluxo de trabalho simples com dois nós externos distintos, adicionando uma nova instância do mesmo fluxo de trabalho em paralelo, até três execuções simultâneas.
- Implementação de um fluxo de trabalho complexo com sete nós internos. Adicionei uma nova instância do mesmo fluxo de trabalho, executando em paralelo, com até três execuções simultâneas.
- Executando um fluxo de trabalho simples com sete nós internos e externos. Assim como nos cenários anteriores, adicionei uma nova instância do mesmo fluxo de trabalho em paralelo, com até três execuções simultâneas.
Surpreendentemente, meu teste mostrou que a utilização básica de RAM foi o dobro do nível normal n8n, enquanto a E/S da CPU e da rede permaneceram as mesmas. Isso pode ser devido ao n8n ter criado os trabalhadores.
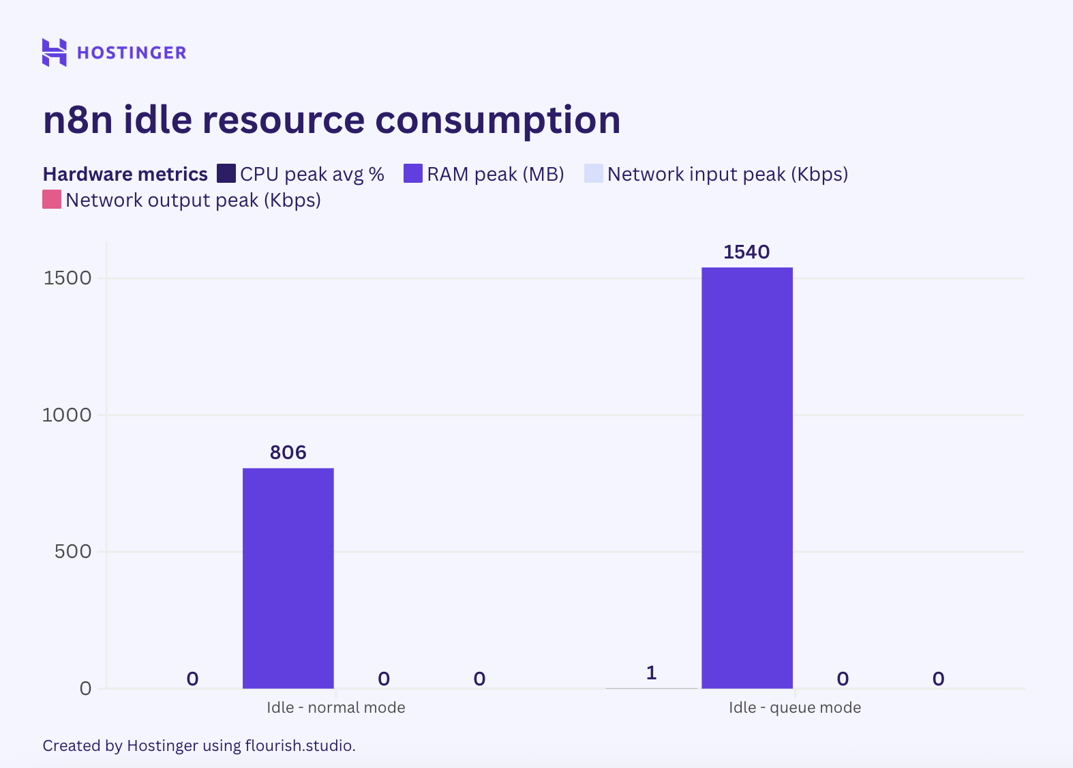
Agora, vamos examinar a utilização de recursos dos fluxos de trabalho simples com dois nós em execução no modo de fila n8n.
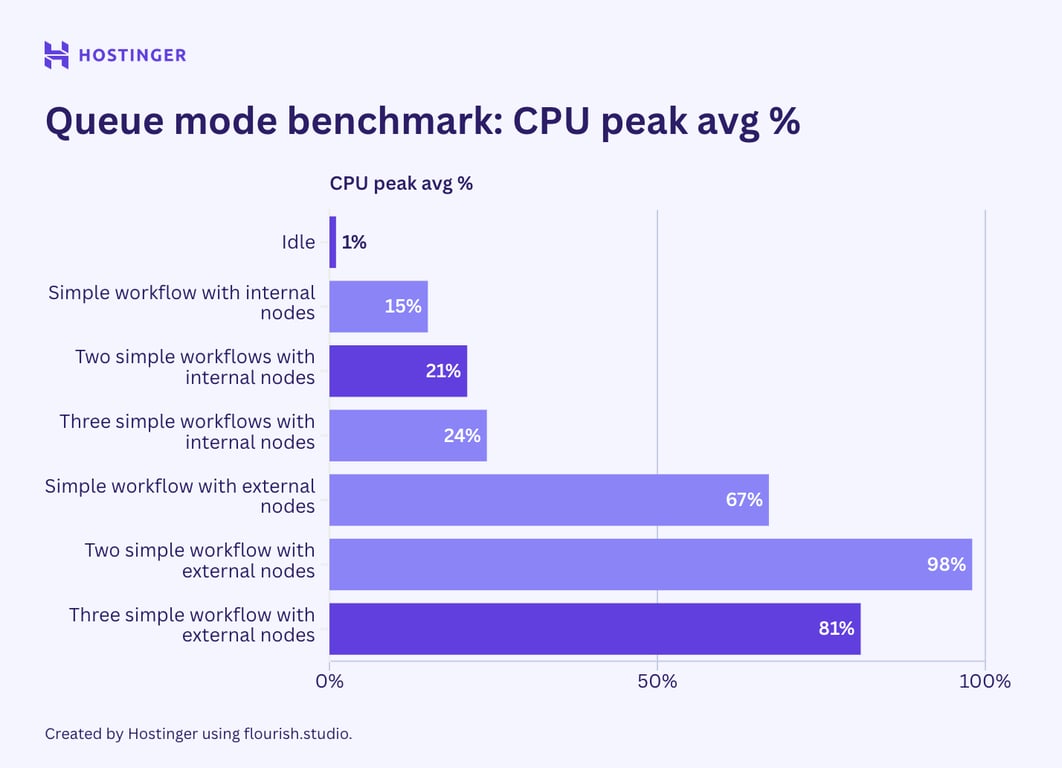
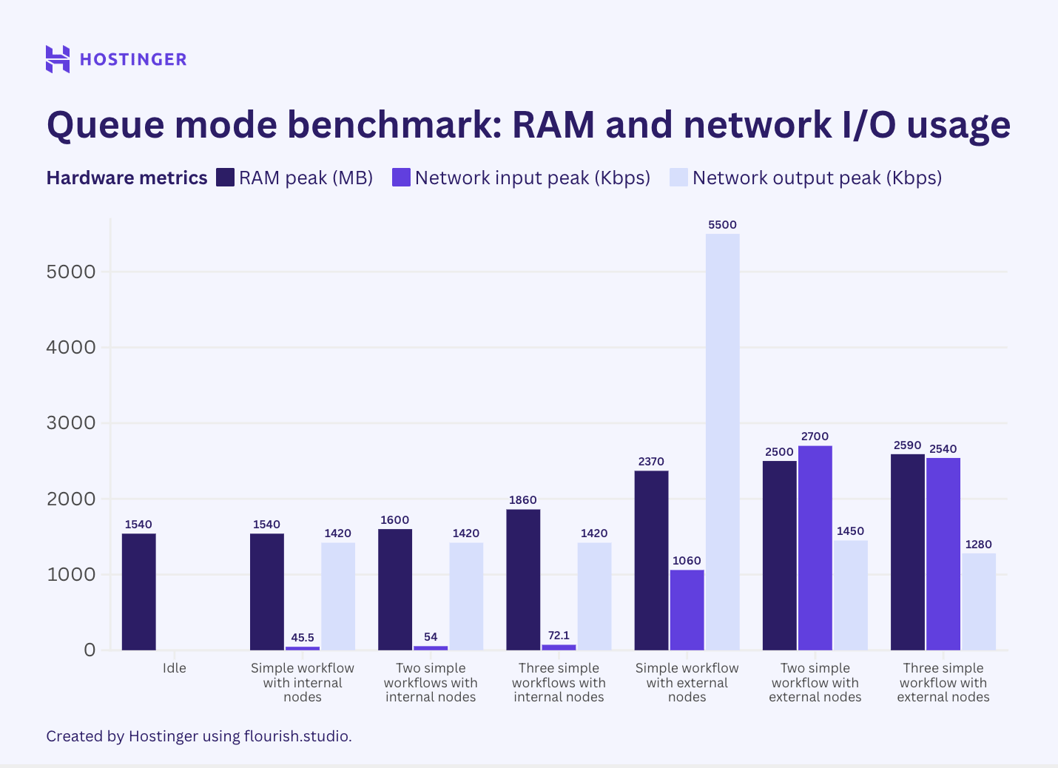
Entretanto, este foi o uso de hardware de fluxos de trabalho complexos com sete nós no modo de fila:
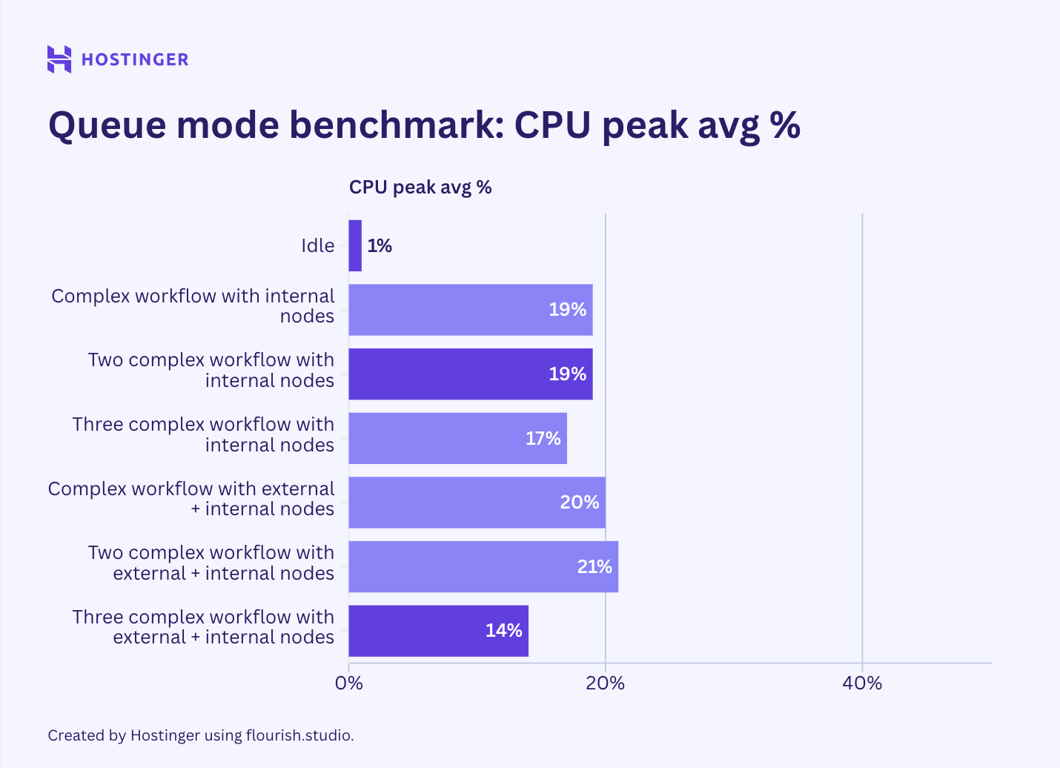
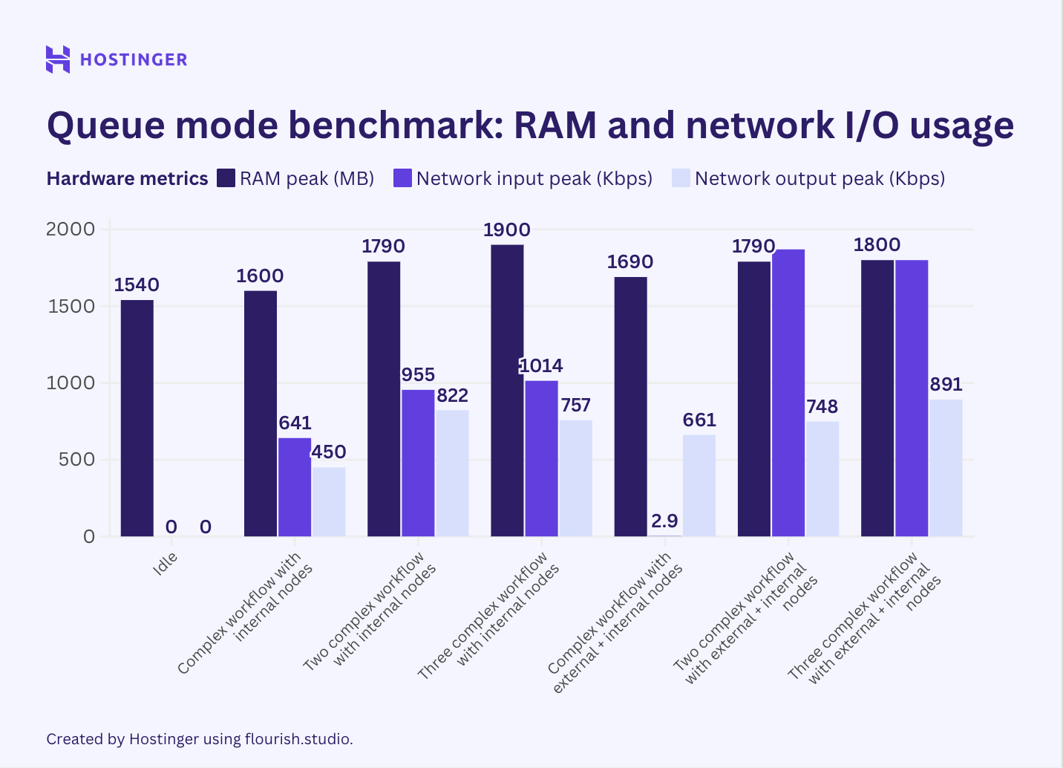
Contrariamente à minha crença inicial, os resultados dos testes indicam que o modo de fila n8n não ajuda a reduzir o pico de utilização de recursos. Embora minha observação sugira que o uso de hardware no modo de fila seja mais estável do que no n8n padrão, o consumo médio é maior.
Importante! Como configurei o modo de fila n8n usando o modelo VPS da Hostinger, o número de workers foi definido como três por padrão. Observe que o número de trabalhadores afetará o consumo de recursos e a execução do seu fluxo de trabalho.
Importante! omo configurei o queue mode n8n usando o modelo VPS da Hostinger, o número de workers foi definido como três por padrão. Observe que o número de trabalhadores afetará o consumo de recursos e a execução do seu fluxo de trabalho.
Ao adicionar mais execuções de fluxo de trabalho, esperava que o efeito do modo de fila fosse mais aparente, mas não foi. Por exemplo, vamos comparar como várias execuções de um fluxo de trabalho complexo com sete nós internos se comportam no modo de fila e no modo padrão:
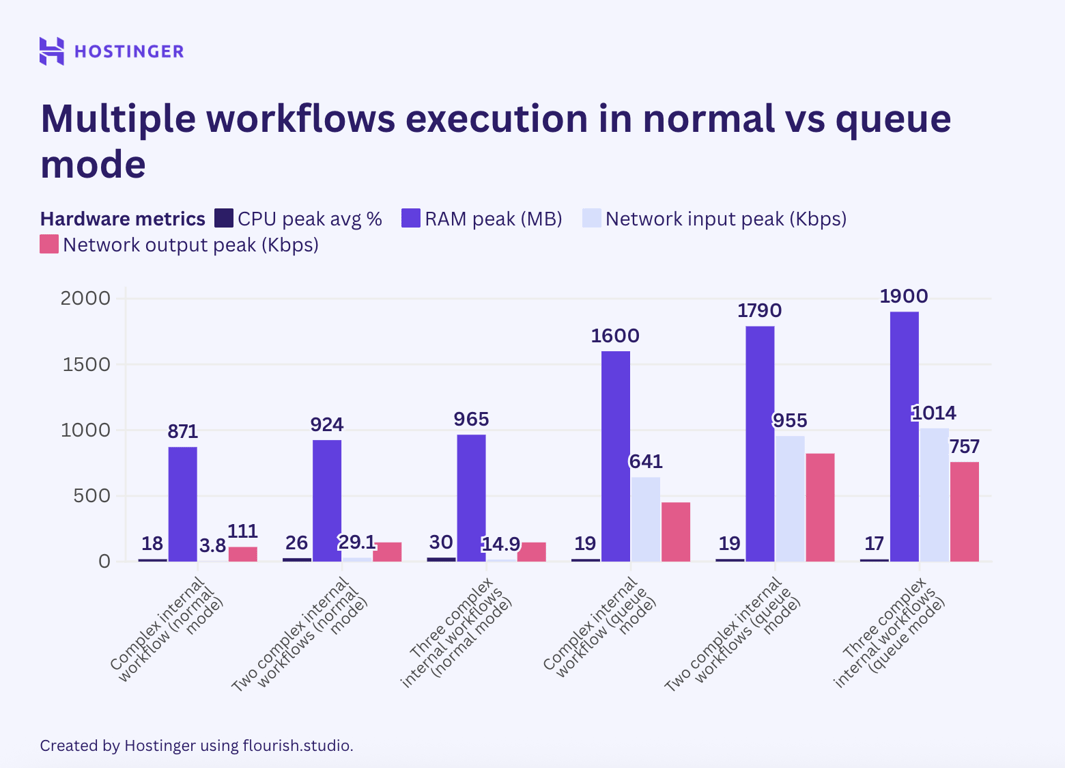
Na versão padrão do n8n, uma execução adicional desse fluxo de trabalho utilizava aproximadamente 40 a 50 MB de RAM, enquanto no modo de fila, adicionava pelo menos 60 MB. Ao executar três instâncias desse fluxo de trabalho, o consumo de RAM aumentou em mais de 100 MB.
Com base nos testes de desempenho, entendemos que o modo de fila n8n não é uma solução que magicamente permitirá executar uma carga de trabalho intensiva em uma máquina de baixo desempenho. Na verdade, esse modo consome, em média, mais hardware do que o n8n normal.
No entanto, se você implantar centenas de fluxos de trabalho, o efeito do modo de fila poderá ser mais evidente. Geralmente é recomendado quando sua configuração de automação apresenta problemas como webhooks lentos e latência significativa, situações em que cargas de trabalho distribuídas podem ajudar a manter a simultaneidade.
O que os benchmarks n8n mostram?
Este teste foi concebido para fornecer uma estimativa aproximada de como os fluxos de trabalho n8n utilizam recursos. Como a amostra de dados de teste é pequena, o comportamento de utilização de recursos pode mudar em grande escala ou quando outras variáveis estiverem envolvidas.
Além disso, concentrei-me apenas na utilização máxima de RAM, CPU e E/S de rede. Se, em vez disso, você considerar médias e outras métricas, como o tempo de execução do fluxo de trabalho, o n8n poderá apresentar um comportamento diferente.
Recomendação prática
Se você estiver começando com 10 a 20 fluxos de trabalho, recomendo hospedá-los em um servidor com pelo menos 4 GB de RAM. Mesmo que você preveja que sua automação usará menos de 4 GB, isso oferece margem de segurança e garante a compatibilidade futura caso precise adicionar mais fluxos de trabalho.
Além disso, monitore de perto a utilização de recursos e use um provedor de hospedagem n8n que ofereça planos facilmente escaláveis, como a Hostinger. Dessa forma, você pode adicionar mais recursos caso sua configuração de automação precise de mais poder computacional do que o esperado.
Todo o conteúdo dos tutoriais deste site segue os rigorosos padrões editoriais e valores da Hostinger.

Bruno is a Content Writer at Hostinger, focused on creating and optimizing helpful, engaging articles about web development and marketing. With a background in journalism, he combines storytelling with practical insights to make complex topics easier to understand. He has also contributed to publications like MacMagazine and Jornal A Tarde. Outside of work, Bruno enjoys exploring art, cooking, and technology.

Comentários
0 responses