Moving Towards Full Stack Automation

In 2015 we launched Awex, the first IPv6-only project powered by Hostinger. It’s fully automated, from its application deployments to network gear. Since then, we have been automating almost everything that’s possible to avoid manual work, and increase efficiency.
To do so, we use Chef and Ansible for most of the tasks.
Due to a huge demand for hosting, we have recently been shipping an increased number of new servers.
Before having it automated, we had to manually set up servers, including creating hardware RAIDs, setting IP addresses, and installing OS. Fortunately, we have managed to create a streamlined process by employing PXE for this kind of job.
Why PXE?
- It fully converges our infrastructure with minimal costs;
- We use phpIPAM to store our inventory information like Chef run lists, environments, IP and MAC addresses. Therefore, we ended up with a simple solution: single PXE virtual machine per data center serving kickstart configuration files from phpIPAM.
The process itself is trivial:
- Put all the necessary information about the new server into phpIPAM, such as IP and MAC addresses, and a hostname.
- Generate kickstart config which is also stored in phpIPAM along with the server as additional metadata field.
- Install OS (custom microservice (written with Ruby/Sinatra) downloads kickstart configuration from phpIPAM dynamically for given MAC address.
- Once OS is installed, run full Ansible playbook to converge all roles;
- Do not run full converges later since they take much time to complete.
We use incremental converges where we just involved versioning control for roles to speed up the process ten times.
We also considered using FAI, Foreman but this tool looked over-engineered for our simple needs.
Why Network?
This year we are delivering more and more L3 networks across all of our data centers (DC).
We started a new data center in the Netherlands which will bring new opportunities for clients sourcing from Europe. This data center is fully L3-only, meaning there are no stretched VLANs between racks or rooms.
In addition, we switched Singapore’s data center over L3 as well. It’s just the right architecture in place. I can say that as I have worked in three ISPs over my career and already found that the most interesting networking stuff lies in data centers architectures.
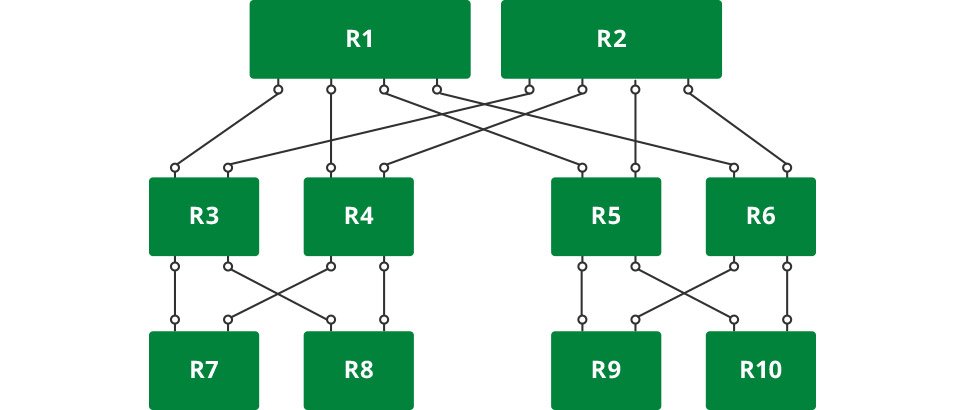
We use Cumulus Linux and switched to 40G between leaf and spines. Everything is automated with Ansible. We connect every commodity server to a 10G network using fiber, somewhere copper. The project without issues cannot be successful in the first phase:
- We dealt with some of the hardware issues bootstrapping new data center.
- 40G adapters were not recognized properly – one end expects copper, while other – fiber.
- 10G over QSFP+ using breakout cable.
- Quagga -> FRRouting.
- Migration from L2 to L3 without any downtime.
40G Is Something New
root@nl-srv-spine1:~# cat /cumulus/switchd/config/interface/swp1/interface_mode CR4 root@nl-srv-leaf1:~# cat /cumulus/switchd/config/interface/swp50/interface_mode XLAUI
It is really strange, but it works while both sides have different interfaces – XLAUI (fiber) and CR4 (copper). After a few minutes, the link is down. But why CR4 is used at all?
I tried to override cable settings with /etc/cumulus/portwd.conf by setting in both cable sides:
[ports]
[cables]
00:17:6a,QSFP-BD-40G=40G-CR4
Unfortunately, it wasn’t successful.
I didn’t find any documentation about portwd daemon at all, so I decided to take a look at the source code.
@classmethod
def decode_ethcodes_base(self, ethcodes, hacks_dict, quirks_dict, eth_map_dict, ext):
...
if ethcodes in quirks_dict.keys():
quirk = quirks_dict[ethcodes]
log_throttle('enabling ethcode quirk: 0x%02x -> %s' % (ethcodes, quirk), level='debug')
# ethcodes with 0 belongs to this test, hence returning 40g-cr4 as default
return (quirk,)
@classmethod
def decode_ethcodes(self, eeprom):
...
# this returns 0
ethcodes = struct.unpack('B', data)[0]
if ethcodes == 0:
ouipn = '%s,%s' % (self.decode_vendor_oui(eeprom),
self.decode_vendor_pn(eeprom))
# skipping this test because certain ouipn is not listed
if ouipn in self.ETH_CODE_ZERO_OVERRIDES.keys():
override = self.ETH_CODE_ZERO_OVERRIDES[ouipn]
log_throttle('enabling zero ethcode override: %s -> %s'
% (ouipn, override),
once=True, level='info')
return (override,)
base = self.decode_ethcodes_base(ethcodes, self.ETH_CODE_SANCTIONED_HACKS,
self.ETH_CODE_QUIRKS, self.ETH_CODE_MAP, 0)
...
@property
def ethcodes(self):
if self._ethcode_override_map is not None:
if self._ethcode_override_map.has_key('port'):
override = self._ethcode_override_map['port']
log_throttle('enabling port ethcode override: %s'
% (override[0]), once=True, level='info')
return override
# we tried to override by vendorpn which is nothing else but '00:17:6a,QSFP-BD-40G'
elif self._ethcode_override_map.has_key(self.vendorpn):
override = self._ethcode_override_map[self.vendorpn]
log_throttle('enabling vendorpn ethcode override: %s -> %s'
% (self.vendorpn, override[0]), once=True,
level='info')
return overrideThe default interface is 40G-CR4 (cannot decode interface information from ASIC), hence we have it. We ordered another kind of transceivers recommended by Cumulus – and it works! CR4 has become SR4.
Another interesting problem we faced with QSFP+ was using an adapter to connect both ends with 10G. This was necessary as our DC provider didn’t have 40G ports to connect to. We use EdgeCore 6712-32X-O-AC-F in our spines layer which doesn’t have 10G ports, hence we moved to 10G over QSFP+ adapter (breakout cable).
2 –> 3
The most interesting part was migrating the existing L2 network with almost full three racks in Singapore to L3. I used a private AS per rack numbering from 65031, 65032, etc. This architecture allows keeping eBGP rules regardless of whether it’s an upstream neighbor or just a ToR switch.
Existing infrastructure was built using separate sessions for IPv4 and IPv6 thus this option allowed us to migrate smoothly without any downtime by testing one protocol before switching to another. Before that, we had a single exit upstream where we announced our prefixes. After setting up another one for migration-only, we needed to make sure traffic flows as expected to avoid issues like asymmetric traffic using next-hop manipulation and AS prepends.
This is an example of Ansible’s YAML hash to configure peers:
upstreams:
nme:
port: swp48
ip: 10.13.128.46/30
ipv6: <ipv6>/126
peers:
nme4:
as: 38001
local_as: 47583
as_prepend: 47583 47583
ip: 10.13.128.45
announce:
- 156.67.208.0/20
- 31.220.110.0/24
nme6:
as: 38001
local_as: 47583
as_prepend: 47583 47583
ip: <upstream-ipv6>
announce:
- 2a02:4780:3::/48
hostinger:
port: swp1
ip: 10.0.31.1/30
ipv6: <ipv6>/64
peers:
hostinger6:
default_route: true
as: 65032
ip: <ipv6>
hostinger-r1:
port: swp2
ip: 10.0.32.1/30
ipv6: <ipv6>/64
peers:
hostinger6-r1:
as: 65033
ip: <ipv6>
hostinger-r2:
port: swp3
speed: 1000
ip: 10.0.33.1/30
ipv6: <ipv6>/64
peers:
hostinger6-r2:
as: 65034
ip: <ipv6>
...This snippet is taken from one of Singapore’s spine switches. Note that we use IPv6-only BGP sessions between internal peers for both protocols and different AS numbers for different racks.
For new deployments, we started using the newest version of Cumulus which replaced Quagga with FRRouting daemon for routing protocols. In general, FRRouting is just a community fork of Quagga. Hence the configuration wasn’t so much different. Basically, only paths had to be changed for configuration files. Before provisioning a new version in production we tested it in the kitchen with the same playbooks and Cumulus-VX.
If you push stuff that’s untested you are just blocking your fire escape.
Final Thoughts
- Just like a power company shouldn’t change its voltage every year, our clients should be able to trust our service to be stable.
- Cumulus Linux still remains the best OS for networking.
- Do NOT design network topology according to application needs. Today applications are smart enough to adapt to any infrastructure.
To sum up, we are trying to do less manual work while spending our time on improving the quality of the service.



