Scaling FTP at 000webhost.com

What is FTP? Is it still alive?
Unfortunately, yes. In general FTP protocol isn’t as cool and scalable as HTTP(S) and I think it will die soon. Linux Kernel already killed it. We still provide FTP access for our free clients and one huge and heavy example is files.000webhost.com.
At the start, we used separate standalone servers for different clients.
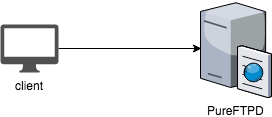
In the middle of 2017, we prepared a separate box with FTP reverse proxy (ProFTPD) to proxy all FTP requests to those standalone servers (PureFTPD). Why PureFTPD? Because it supports scanning files on upload and a custom authentication handler which can be implemented easily in any programming language. The separate authentication process is running as an ambassador to offload authentication from PureFTPD. Hence, Skirmantas wrote a custom authentication handler which caches responses in Redis to speed up authentication process and increase high availability.
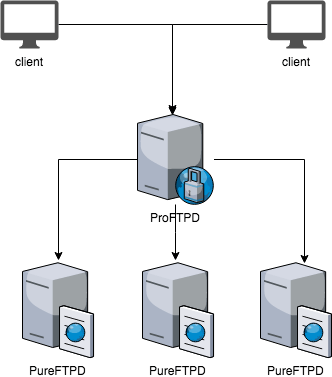
In our case, the reverse proxy is a single box which has few IPv4 and IPv6 addresses. The DNS layer load balances those IP addresses for the client to avoid hitting null routed IP address. Load balance isn’t done using round-robin – we rely on SRANDMEMBER Redis function. We already use it for our IP address randomization, thus it was very easy to adopt this approach for this case.
Like anything designed on a few table napkins, just before Black Friday, we started hitting the reverse proxy limits: segfaults, max connections, resource limits, timeouts. Raising them did help a bit, but not for long. We reduced timeouts to OpenLDAP and Redis instances to avoid staling requests and to avoid saturation of the whole service, tried using different branches for ProFTPD, experimented with other limits and timeout options. So, I concluded that it’s enough to spend time on fixing the problems around and to look and scale our FTP infrastructure a bit smarter. What if we just add more than one proxy in front to absorb client traffic? With HTTP(S) or other stateless protocols, it’s trivial, as you can load balance requests using DNS round-robin or the more sophisticated method using anycast.
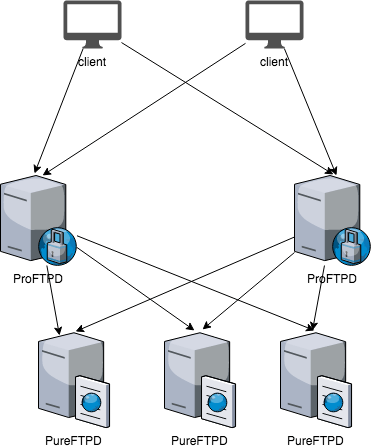
Since we started Awex, we rely on PowerDNS. Hence, I modified our custom pipe backend for PowerDNS to fit scaling needs.
The first idea was just to use consistent hashing with the client’s IP. But there will be problems with clients under carrier-grade NATs where outgoing IP addresses are changing over time.
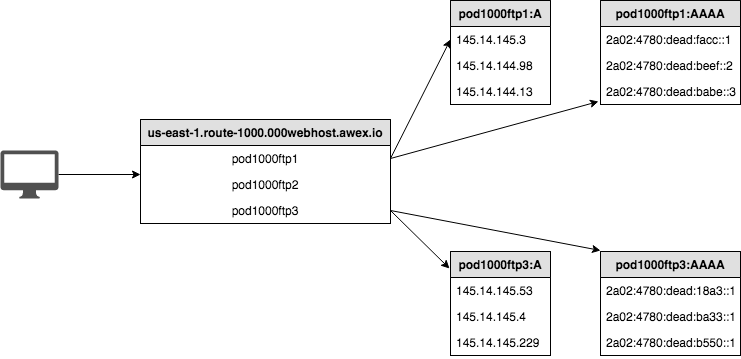
The second idea was to use consistent hashing with the client’s subnet. For IPv4 – use the first 24-bits and for IPv6 – the first 48-bits. This allows us to keep consistent DNS answers to the same client. For more information about implementation, see here.
So, we launched a few more boxes with few additional IPv4/IPv6 addresses as with the first box and got another problem. How should DNS servers answer to the client while using different IP addresses for the same node? How to distinguish them? The answer to the problem were groups. We created separate groups with separate IP address pools and we do group consistent hashing to return random IP address from the appropriate group, which is selected by aforementioned client’s subnet. We do consistent hashing by the client’s subnet to select the group and return IP addresses from the selected group.
Some more advantages to our infrastructure:
- Simplified upgrades – we just remove the group from DNS or re-route those IP pools over another available FTP node;
- Solved single outgoing IP address from the reverse proxy problem. Backends have limits like
MaxClientsPerIP; - Horizontal scaling, which means we no longer need to buy monster nodes (vertical scaling). We can spin up more nodes on demand.
Conclusion
It’s almost impossible to replace FTP protocol with something else in shared hosting environments, because people used, use and will use what they know and like most. Thus it’s crucial to adapt to the community and provide the best service around the globe.



