GraphQL vs. REST: Which Is the Best for API Development?

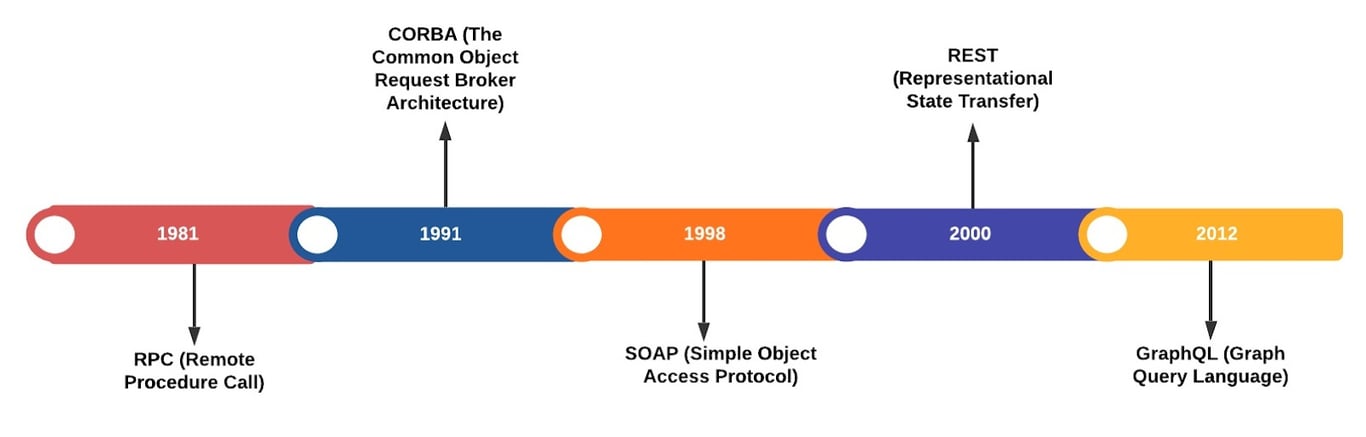
API, the acronym for Application Programming Interface, is a software intermediary that allows two applications to communicate with each other. That could be a server, a client, or an app talking to a server. The timeline below illustrates how it has evolved over the years, and it lays a great foundation for how an API can be built. REST remains a popular tool for building APIs. However, in 2012, Facebook wanted something different than REST, and that is when GraphQL (Graph Query Language) was introduced.
What Is REST?
REST stands for Representational State Transfer, meaning that each resource has its own endpoint. Initially, it was a dissertation published by Roy Fielding in 2000 and popularized by companies like Twitter in 2006. REST is an architectural concept for network-based software. It has no official set of tools, no specification, does not particularly care if you use HTTP, AMQP, etc., and is designed to decouple APIs from clients.
Main Challenges of REST API
REST API sometimes requires Multiple Round Trips. This applies when we need to display some data which must be consumed from different endpoints, and consuming data from only one endpoint is not enough. The table below illustrates three endpoints:
| GET /users | List all users |
| GET /users/:id | Get the single user with id :id |
| GET /users/:id/projects | Get all projects of one user |
What if in a client app we need to fetch projects related to that specific user and some tasks that may also be related to the project itself? Should the back-end team develop anything extra? There are the following possible ways to do that:
- To have a query included, and then have tasks returned to each project: GET /users/:id/projects?include=tasks
- To have a separate endpoint, resource projects, and asking a client app a query filtering based on user id: GET /projects?userid=:id&include=tasks
- To include all possible data associated with the user in one endpoint: GET /tasks?userid=:id
Over-fetching and under-fetching. When there is a need to return too much data, the client app does not need all of it. Customers won’t be happy if they are required to download extra information they do not actually need. On the other hand, by reducing the level of information on a server, the problem of under-fetching can be experienced, and another extra endpoint and resource on a server to get that data will be needed. The solution is: GET /users?fields=firstname,lastname.
Difficulty in creating versions and deprecating fields which are not necessary for new releases. It is hard to maintain REST APIs when they grow over time, and different requirements are requested to support different versions of apps and multiple clients. So, usually, v1 is left as it is, and v2 is created with a newer data structure. With GraphQL, it could be done without version control. GraphQL only returns the explicitly requested data, so new capabilities can be added via new types and new fields on those types without creating a breaking change. This has led to a common practice of continuously avoiding breaking changes and serving a versionless API.
Non-predictable data. With REST, it is unknown what data will be returned from a server – what fields, how many of them, etc. With GraphQL, the client asks for specific fields to be returned. It does not matter if it is a query or mutation – you are in control of what will be returned back.
What Is GraphQL?
GraphQL is a newer concept, released by Facebook publicly in 2015. As a new way of asking for data from a server, it is a query language, specification, and collection of tools designed to operate over a single endpoint via HTTP, optimized for performance and flexibility.
This table compares GraphQL and REST as two approaches to building an API. Talking in general terms, it cannot be considered an apple-to-apple comparison, but more like an orange-to-apple parallel since REST is a conventional standard for planning APIs, and GraphQL is a query language that helps solve problems with APIs. However, they are both still fruit 🙂
The main difference here is that GraphQL is a client-driven language. It has the architecture where the front-end app decides what data to fetch and how much of it has to be returned from the server. Meanwhile, using REST, everything is designed on the server, so the server drives the architecture.
| GraphQL | REST |
| A query language offering efficiency and flexibility for solving common problems when integrating APIs | An architectural style largely viewed as a conventional standard for designing APIs |
| Deployed over HTTP using a single endpoint that provided the full capabilities of the exposed service | Deployed over a set of URLs where each of them exposes a single resource |
| Uses a client-driven architecture | User a server-driven architecture |
| Lacks automatic caching mechanism | Uses caching automatically |
| NO API versioning | Supports multiple API versions |
| JSON representation only | Supports multiple data formats |
| Only a single tool is used predominantly for documentation: GraphiQL | Wide range of options for automated documentation, such as OpenAPI and API Blueprint |
| Complicates handling of HTTP status codes to identify errors | Uses HTTP status codes to identify errors easily |
Reasons to Use GraphQL
There are three main reasons why we might want to consider using GraphQL instead of REST:
- Network Performance. If we want to increase network performance by sending less data or sending only the information we need for clients.
- The “Include vs Endpoint” Design Choice. A tricky choice exists between including the request or creating an additional endpoint. With GraphQL, that problem is solved because of the schema and resolver functions. So the client has control of what data has to be returned.
- Managing different types of clients. Imagine you have one API, and all the clients (iOS app, Android app, web app, etc.) are completely different from each other – they need an entirely different structure or amount of data returned from the server. With the REST approach, you might have to create a separate API. In contrast, with GraphQL, you won’t need to because you can have everything returned from a single endpoint.
How to Get Started
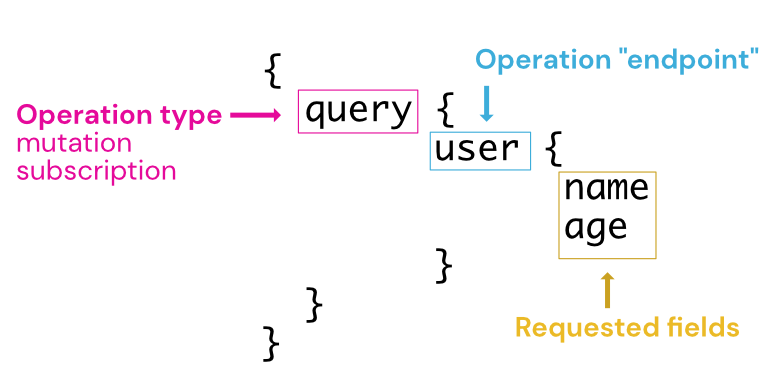
This is a breakdown of how a query is constructed. Three main parts are considered: 1) operation type, 2) operation endpoint, 3) requested fields.
Terms to Learn
No matter what implementation you choose as there are plenty of languages, GraphQL is not only available in JavaScript or Node – you can use PHP, Python, JAVA, Go, and others. Each language has its own implementation of GraphQL, so you do not need to build everything from scratch. There are tools and packages you can employ, and those terms are almost the same on all of them, so it might be worth learning them if you wish to build an API using GraphQL:

Types. The data model in GraphQL is represented in types, which are strongly typed. There should be a 1-to-1 mapping between your models and GraphQL codes. You can think of this as a database table where the user table has the fields like id, first name, last name, email, projects. So, things to remember include that exclamation point saying that an identifier (id) cannot be nullable or, in other words, it has to be something there as it’s a required field.
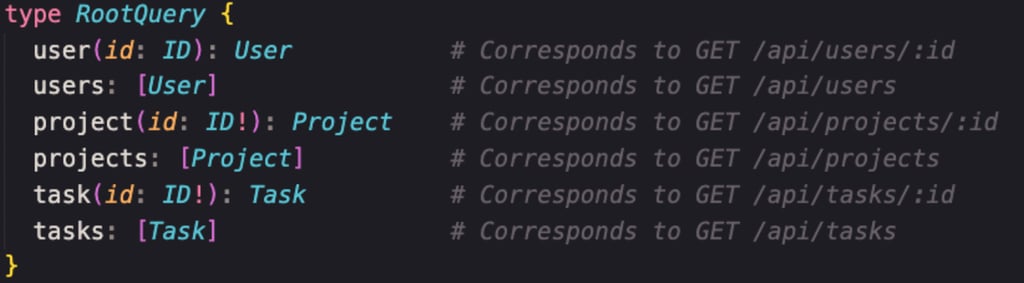
Queries. Queries define what queries you can run on your GraphQL API. By convention, there should be a RootQuery, which contains all the existing queries. In the example, the comment here shows how it looks on a REST API. In parentheses around brackets, we see an argument that has to be a unique identifier, and after a colon is the type user. It shows what has to be returned when we perform this query, so it returns the user. The project query will return the project, the task query will turn the list of tasks, and so on.

Mutations. If queries are GET requests, mutations can be seen as POST | PATCH | PUT | DELETE requests that modify the data. The example includes mutations of “createUser”, “updateUser”, “removeUser”.
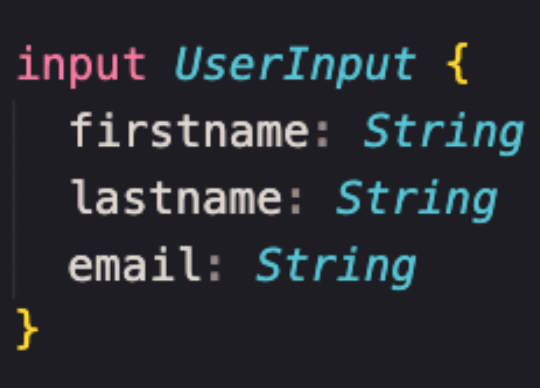
Input. UserInput type is a User type without the id and projects fields. Notice the keyword input instead of type. You can think of this as a form on a page where you need to enter some data and the kind of information that needs to be entered to create that user profile.
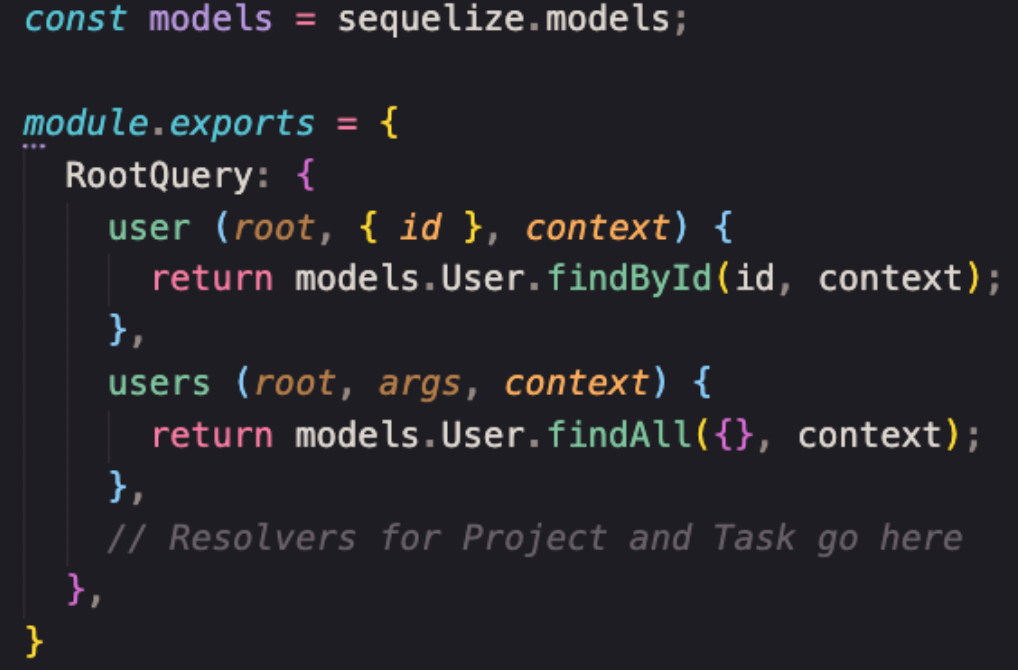
Resolvers. The resolver function gives a specific set of instructions for converting the operations of GraphQL into data. It is basically a controller function, the logic for what has to be returned (resolvers for queries) when that query happens and a user asks for data, and resolvers for mutation are used when a user seeks to update or delete data.
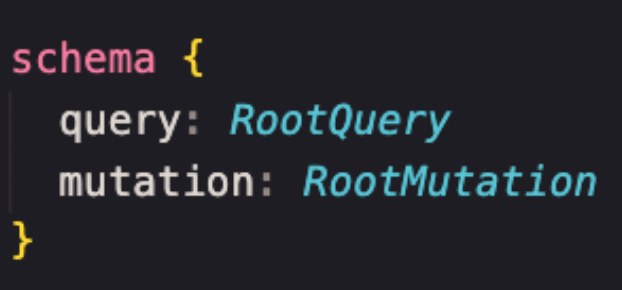
Schema. With types, queries and mutations, we define a GraphQL schema, which is what the GraphQL endpoint exposes to the world.
Resources to check
Here are two main resources to delve deeper into GraphQL:
- GraphQL.org. Dedicated to learning all the basics and the actual specification of GraphQL.
- How to GraphQL? Dedicated to learning about implementations. For instance, if you seek to know about the Apollo server, this will give you an understanding of what front-end frameworks can be used to consume the data from that API. It is not required to use any of the tools or libraries for the front-end to consume the API – you can perform a regular XmlHttp request, but you must make a POST request to that endpoint and provide the query in the body, which is the GraphQL.
The GraphQL server API can be used as a gateway to other microservices, talking directly to the database or other REST APIs. Thus, you could have multiple REST APIs, get that data and convert it to one single source of information.
This article is inspired by front-end developer Gediminas Survila’s presentation on “GraphQL vs. REST: Which is the best for API Development?”

Ievas' powerful leadership skills enhance the strong brand name and image here at Hostinger. As Brand Communication Manager, she leads the team and continually monitors the delivery of brand direction as well as recommends areas of improvement so ensure we always stay on our A-game.


