Deep dive into our October 7 email outage: Causes, fixes, and what’s next

On October 7, 2025, we faced a disruption in our email service: some users were unable to receive mail and access mailboxes due to an unexpected technical problem in our storage system. Throughout the incident, your data was never at risk – our engineers prioritized data protection while carefully restoring full functionality.
We know how important a reliable email service is and sincerely apologize for the disruption. The rest of this post explains what happened, how we resolved it, and what steps we’re taking to make our systems stronger.
What happened
We use CEPH, a distributed storage system trusted by leading organizations such as CERN, and designed for high availability and data safety.
The root cause was related to BlueFS allocator fragmentation, triggered by an unusually high volume of small-object operations and metadata writes under heavy load.
In other words, the internal metadata space within CEPH became fragmented, which caused some object storage daemons (OSDs) to stop functioning correctly even though the system had plenty of free space available.
Incident timeline
All times are on October 7, 2025 (UTC):
- 09:17 – Monitoring systems alerted us about abnormal behavior in one OSD node, and the engineering team immediately began investigating.
- 09:25 – More OSDs began showing instability (“flapping”). The cluster was temporarily configured not to automatically remove unstable nodes, preventing unnecessary data rebalancing that could worsen performance.
- 09:30 – OSDs repeatedly failed to start, entering crash loops. Initial diagnostics ruled out hardware and capacity issues – disk usage was below recommended thresholds.
- 10:42 – Debug logs revealed a failure in the BlueStore allocator layer, confirming an issue within the RocksDB/BlueFS subsystem.
- 10:45 – Engineers began conducting multiple recovery tests, including filesystem checks and tuning resource limits. The checks confirmed there were no filesystem errors, but OSDs continued crashing during startup. Up to this point, there were no problems for email service users.
- 11:00 – A Statuspage was created.
- 13:12 – The team hypothesized that the internal metadata space had become too fragmented and decided to extend the RocksDB metadata volume to provide additional room for compaction.
- 13:55 – Additional NVMe drives were first installed in one OSD server to test whether adding more space would remediate the fragmentation issue.
- 15:02 – After validating the solution, additional NVMe drives were installed on the remaining affected servers to expand metadata capacity.
- 15:10 – Engineers started performing on-site migrations of RocksDB metadata to the newly installed NVMe drives.
- 16:30 – The first OSD successfully started after migration – confirming the fix – and we performed the same migration and verification process across the remaining OSDs.
- 19:17 – The storage cluster stabilized, and we started gradually bringing the infrastructure back online.
- 20:07 – All email systems became fully operational, and cluster performance has normalized (see the image below). Crucially, all incoming emails were successfully moving from the queue to users’ inboxes, allowing users to access and read their emails.
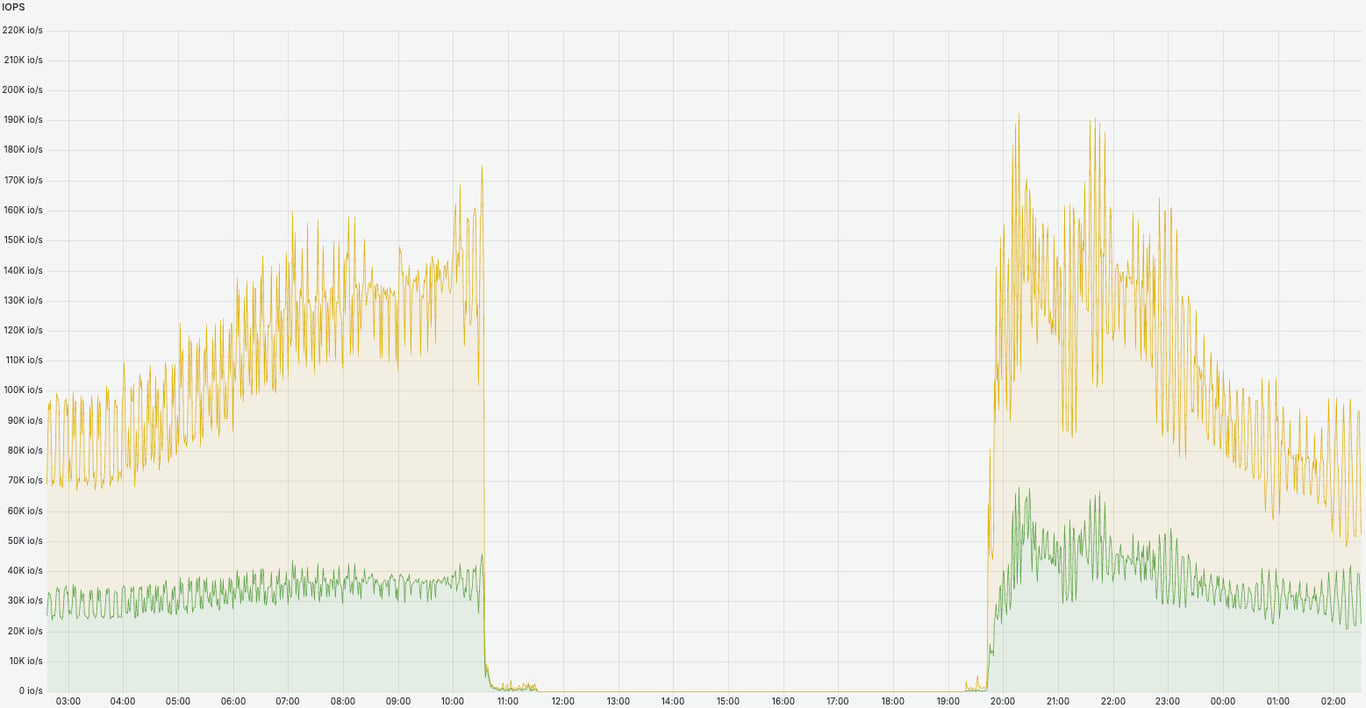
- 00:29 (October 8) – All queued incoming emails were delivered to the corresponding users’ mailboxes, and users were able to access their mailboxes.
Full technical background
The issue was caused by BlueFS allocator exhaustion, influenced by the default parameter bluefs_shared_alloc_size = 64K and triggered by an unusually high volume of small-object operations and metadata writes under heavy load.
Under these metadata-heavy workloads, the internal metadata space within CEPH became fragmented – the allocator ran out of contiguous blocks to assign, even though the drive itself still had plenty of free space. This caused some object storage daemons (OSDs) to stop functioning correctly.
Because CEPH is designed to protect data through replication and journaling, no data loss occurred – your data remained completely safe throughout the incident. The recovery process focused on migrating and compacting metadata rather than rebuilding user data.
Our response and next steps
Once we identified the cause of the issue, our engineers focused on restoring service safely and quickly. Our team prioritized protecting your data first, even if that meant the recovery took longer. Every recovery step was handled with care and thoroughly validated before execution.
Thanks to our resilient architecture, all incoming emails were successfully delivered once the storage system was restored, and no emails were lost.
Our work doesn’t stop with restoring service – we’re committed to making our infrastructure stronger for the future.
To improve performance and resilience, we installed dedicated NVMe drives on every OSD server to host RocksDB metadata. This significantly boosted I/O speed and reduced metadata-related load.
We also strengthened our monitoring and alerting systems to track fragmentation levels and allocator health more effectively, enabling us to detect similar conditions earlier.
We also captured detailed logs and metrics, and we’re collaborating closely with the CEPH developers to share our findings and contribute improvements that can help the broader community avoid similar issues and make the system even more resilient.
We appreciate your patience and understanding as we worked through this incident. Thank you for trusting us – we’ll keep learning, improving, and ensuring that your services stay fast, reliable, and secure. And if you need any help, our Customer Success team is here for you 24/7.



