How Hostinger Deals With DDoS Attacks
How to Recognize a Distributed Denial-of-Service (DDoS) Attack
To avoid an attack, you need to know what’s coming your way. When you spot an attempt to disrupt the regular operation of a targeted server, service, or network by overburdening it with unwanted traffic, you’re dealing with a distributed denial-of-service (DDoS) attack.
A DDoS attack attempts to deny access to a targeted server by generating a large amount of malicious internet traffic which overwhelms the target’s available resources. We implement traffic filtering solutions to prevent such attacks and guarantee maximum uptime.
We’re constantly improving our services and renewing our systems to stay ahead of the game. Today, we’ll detail how we combat DDoS attacks and explain our Wanguard traffic filter setup and overall infrastructure.
What Does an Attack Look Like?
Here’s a real-life example of a DDoS attack. Picture 400 Mbps of UDP traffic heading to a VPS with an available bandwidth of 100 Mbps.
Simple Jekyll website load time results:
Before the attack: 0.08 seconds
During an attack: 23.35 seconds (1st attempt), 30.86 seconds (2nd attempt)
DDoS attacks are often hard to mitigate because they usually involve whole or multiple botnets targeting you. A botnet consists of many infected systems, so fighting it on your own will, most of the time, prove useless.
How We Deal With DDoS Attacks
We have two DDoS mitigation solutions for dealing with incoming attacks in our infrastructure – remotely triggered black hole (RTBH) and traffic filtering.
RTBH filtering offers a way to eliminate unwanted traffic quickly before it enters our infrastructure. While this method effectively protects our infrastructure as a service provider, it prevents all traffic from hitting us – not something our clients prefer. Eventually, their websites and VPSs become completely unreachable. As a result, the attackers achieve their goals.
Traffic filtering is the next-level DDoS protection for our services. It only stops the malicious traffic instead of dropping all of it. Malicious traffic is identified by examining the packets flowing through our infrastructure. The following traffic elements are inspected for specific patterns:
- packet payload
- source port
- source IP
- destination port
- country
- and more
This filtering process is done on our infrastructure before the traffic reaches our services, so our clients have nothing to worry about.
Traffic Filtering
Setup
We have implemented out-of-line filtering for our setup. Since we rarely experience powerful DDoS attacks, in-line filtering would be inefficient in actual practicality and cost – we have the RTBH method to combat them, instead.
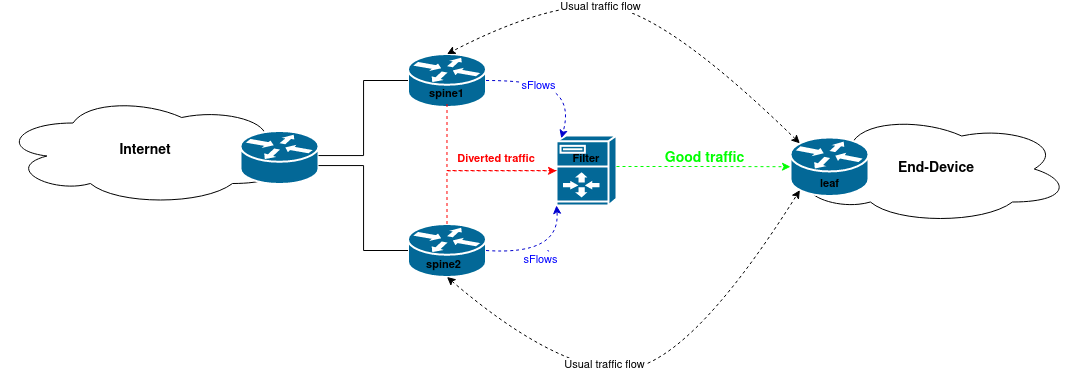
Our setup involves filter instances connected to spine switches through which diverted traffic flows. We use sFlows, which are sent from spine instances to the filter instance, to investigate and divert traffic if needed. Clean traffic is forwarded to leaf switches, while malicious traffic is dropped at the filter instance. It’s important to note that the traffic diversion and filtering processes are fully automated.
If any destination host experiences a traffic spike above our set thresholds, we advertise that IP address to the spines using ExaBGP. When the traffic arrives at a filter instance, we examine the incoming packets to identify the attack pattern. Once complete, new rules are added to the firewall, preventing malicious traffic from reaching its destination.
Hardware
The main elements that the filter server depends on are the CPU and NIC. After some testing and research, we decided to go with the following:
CPU: Intel(R) Xeon(R) Silver 4215R @ 3.2 GHz
NIC: Intel XL710 (40G)
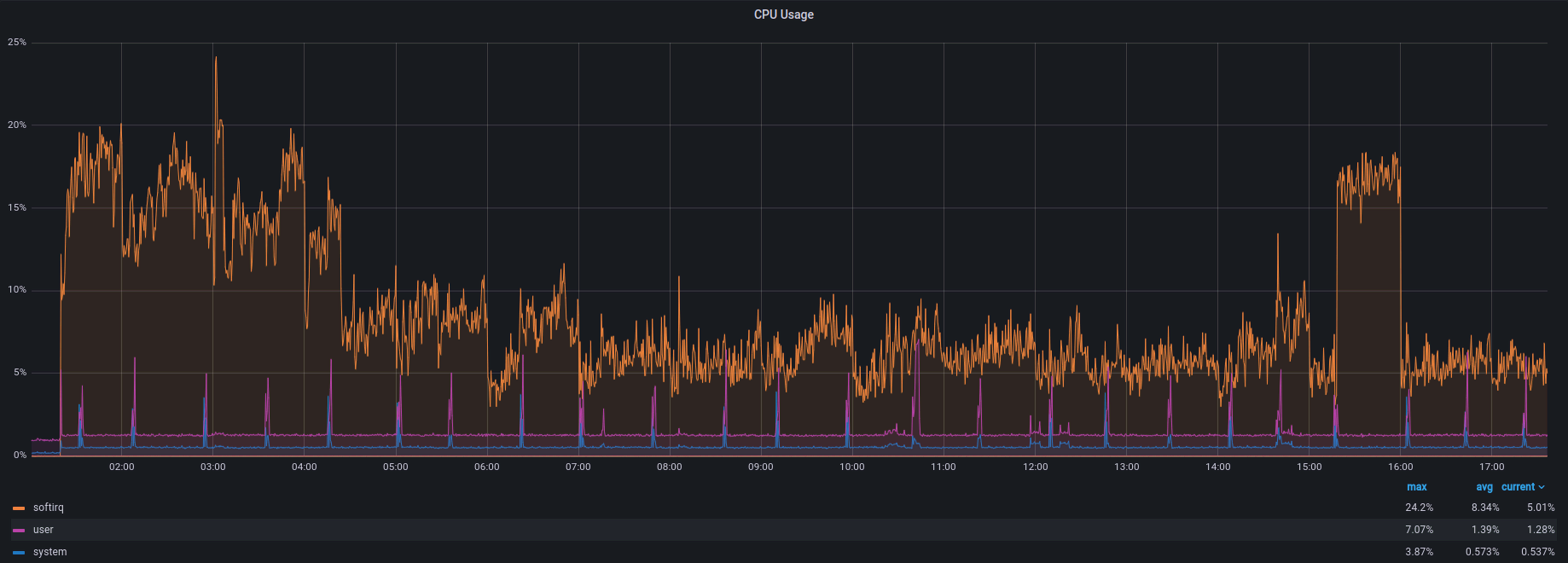
During a DDoS attack with ~1.5 Mpps and 8 Gbps of traffic, the CPU usage looks like this:
Automation
It would be tough to manage multiple filter instances across all data centers manually. As a result, the whole solution is fully automated, from attack detection to threshold settings. Currently, we use Chef and Ansible for our infrastructure as code (IaC). Changing thresholds or other settings for all instances at once is as easy as changing a few lines of the code.
Configuration
Here’s a sneak peek at our configuration:
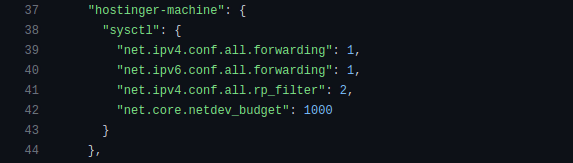
Our instance must be able to route packets between interfaces, so forwarding is enabled for both IPv4 and IPv6. Since we don’t have any routes via interfaces used for traffic diversion, we must disable reverse path filtering or set it to “loose mode” – as we have done – so the packets coming via those interfaces don’t get dropped.
We have increased the maximum number of packets in one NAPI poll cycle (net.core.netdev_budget) to 1000. As we prefer throughput over latency in this case, we’ve set our ring buffers to the maximum.
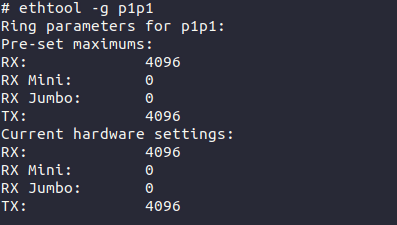
We’ve been running this solution for six months and can see that these small changes are enough to handle any attacks of the anticipated scales. We didn’t go deeper into tuning the system as the default values are reasonable and don’t cause any problems.
Next, we have actions. An action is triggered when an attack is detected or finished. We use it to divert traffic (route announcement via ExaBGP), inform our monitoring team about the attack (a Slack message from the instance), and more.
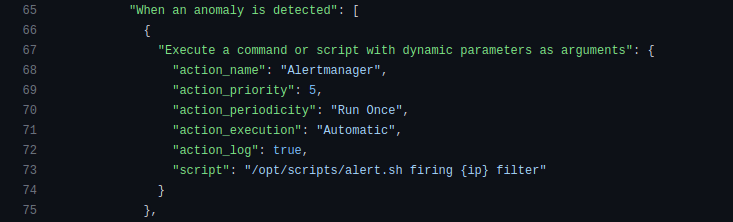
Thresholds are also managed as code, providing numerous options for detecting an attack. For example, if we detect 100K UDP packets per second aimed at a single target, we start the filtering process. It can also be TCP traffic, HTTP/HTTPS requests, and so on.
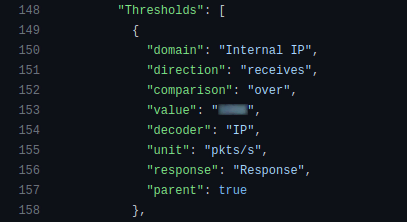
The prefixes that should be under protection are also added automatically from Chef data bags.

Results
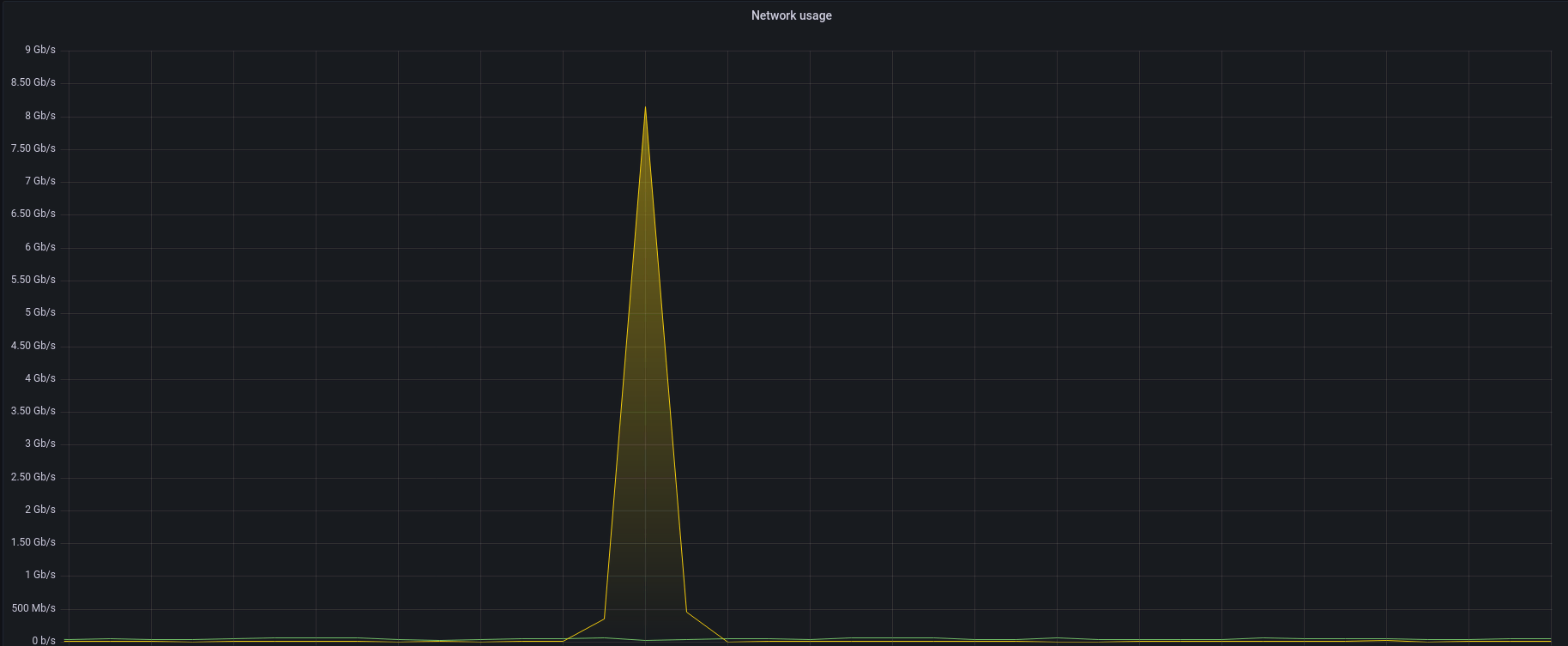
What does the handling of a DDoS attack look like on Grafana? Let’s look at a recent attack with 8 Gbps and 1 Mpps of traffic below.
Here’s the traffic incoming to the filter instance:
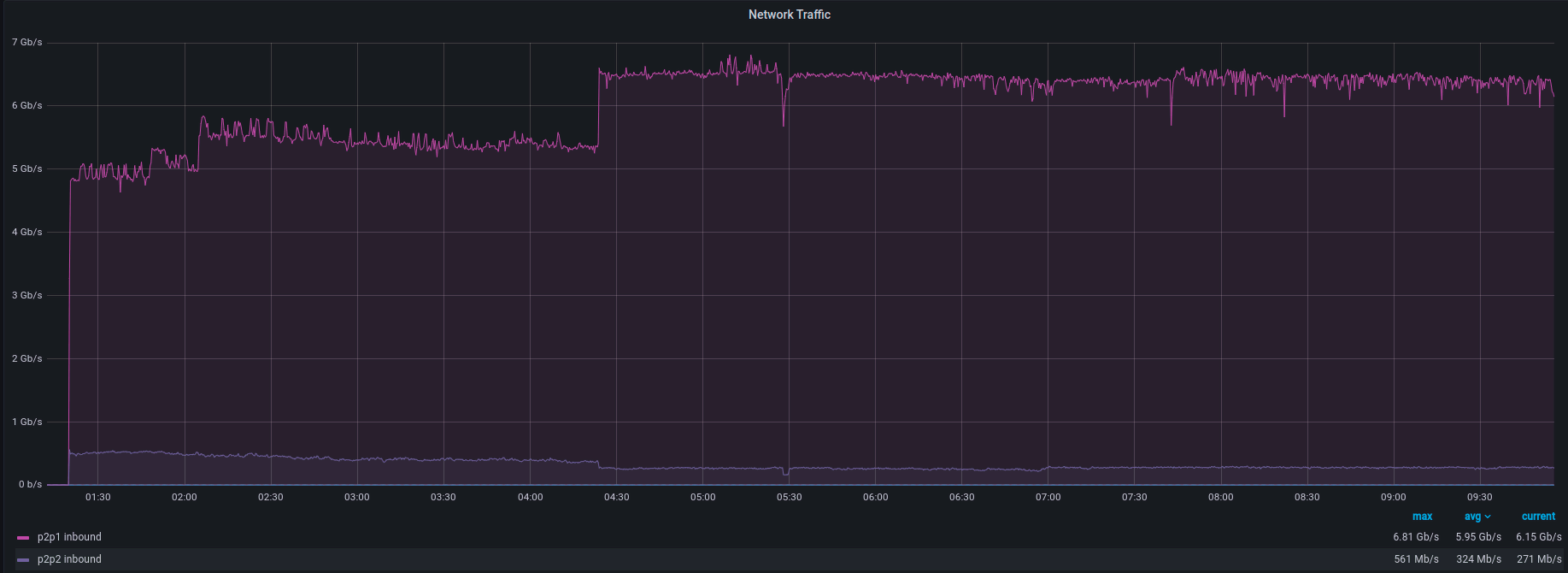
And here’s the traffic outgoing to the end device:
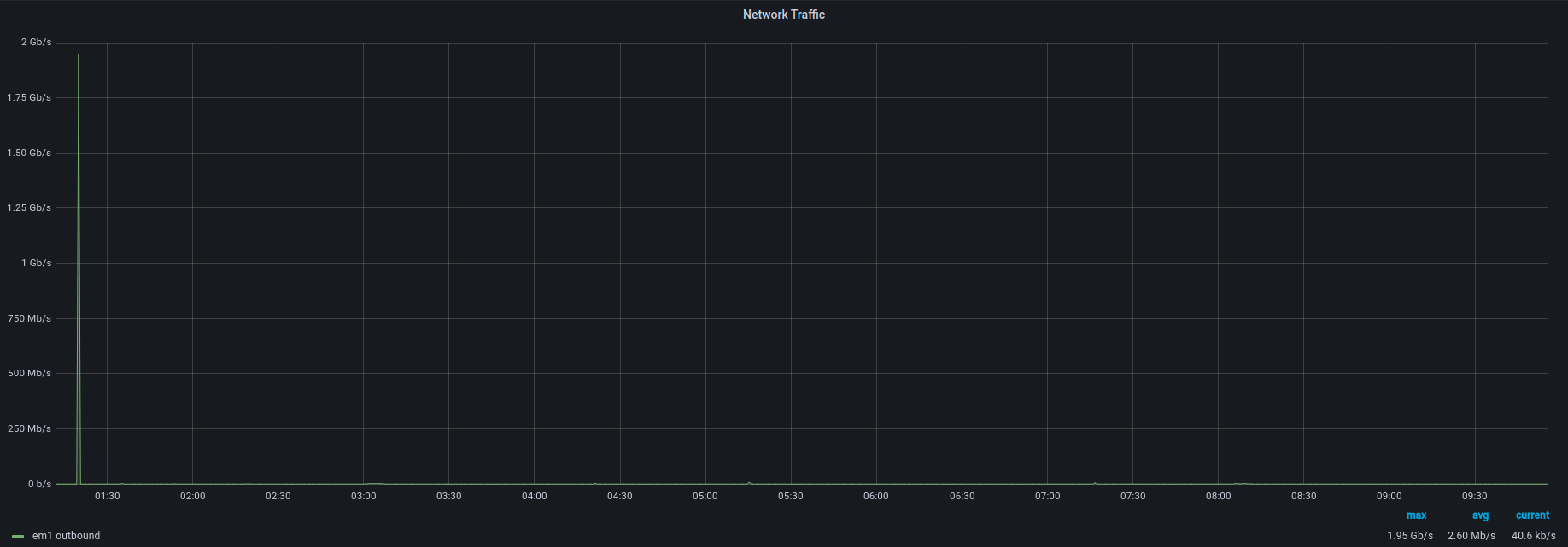
Incoming packets per second:
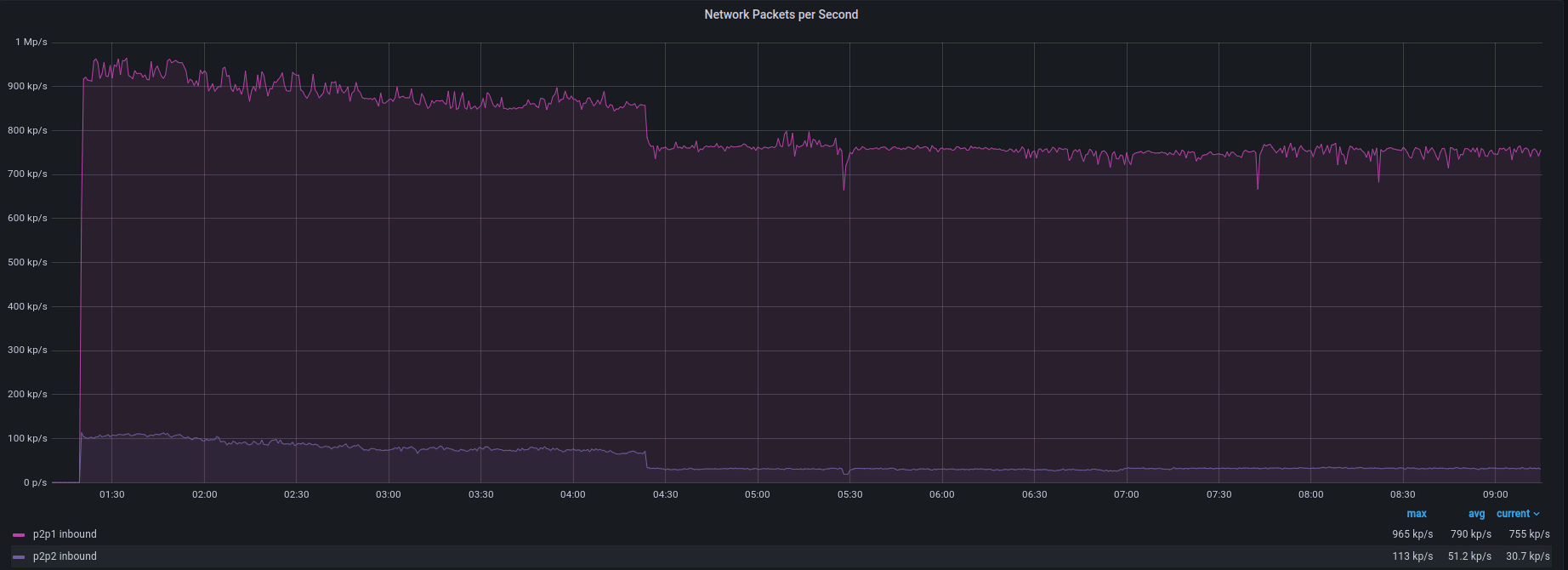
Outgoing packets per second:
As you can see, there is a short burst of traffic going from the filtering instance to the end device. It is the gap caused by the attack pattern identification process. It’s a short amount of time, usually between 1 and 10 seconds, but it’s something to be aware of. As seen on the graph, once the attack pattern is identified, you’re safe!
What about the speed of attack detection? This part depends on sFlows, and, as we know, it’s not as fast as port mirroring. That said, it’s easy to set up, flexible, and costs less. Once an attack starts, the time to divert the traffic to the filter instance takes between 20 and 50 seconds.
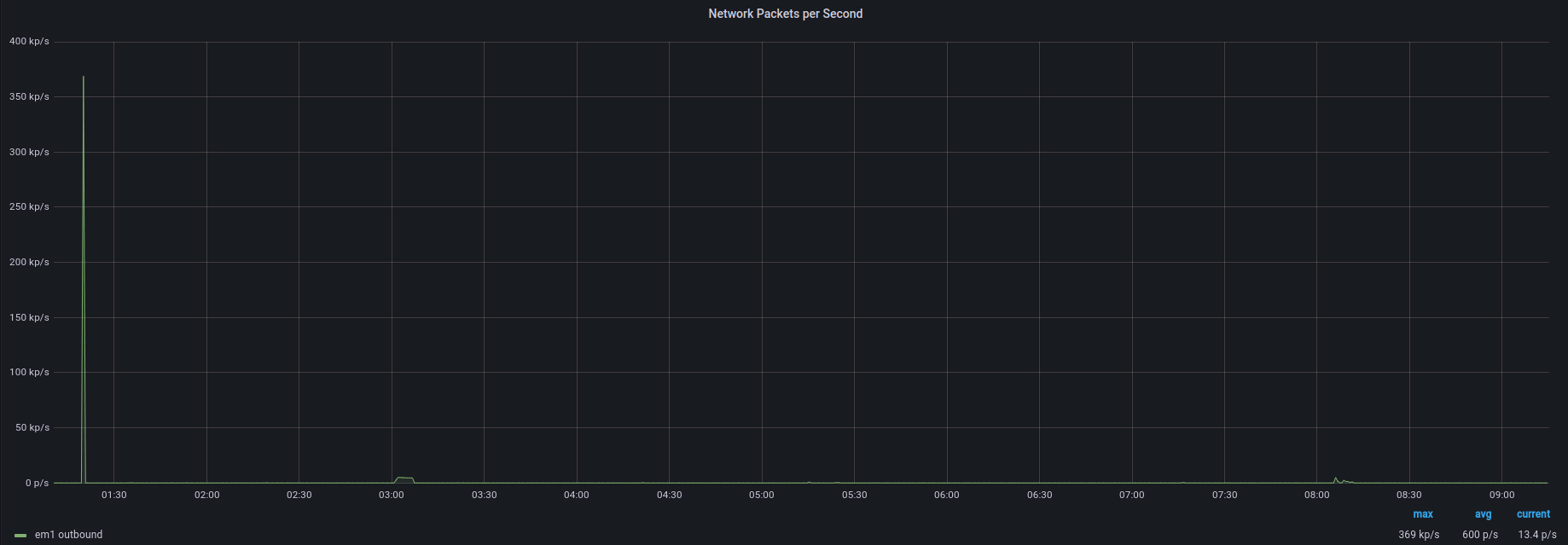
This is how the whole process looks from the target instance:
Traffic
Packets per second
There’s a short spike and we’re back to business as usual. Depending on the service you’re running, you may not even notice it.
At Hostinger, we like to know what is happening in our infrastructure, so let’s investigate this case a little bit further:
Attack source. We noticed an increase in IPv4 traffic from a few countries, with India and Taiwan contributing the most. There is a high possibility that those IPs were spoofed, so this information may be inaccurate. We have the list of source addresses and ASNs but won’t publish it here for the same reason (spoofing).
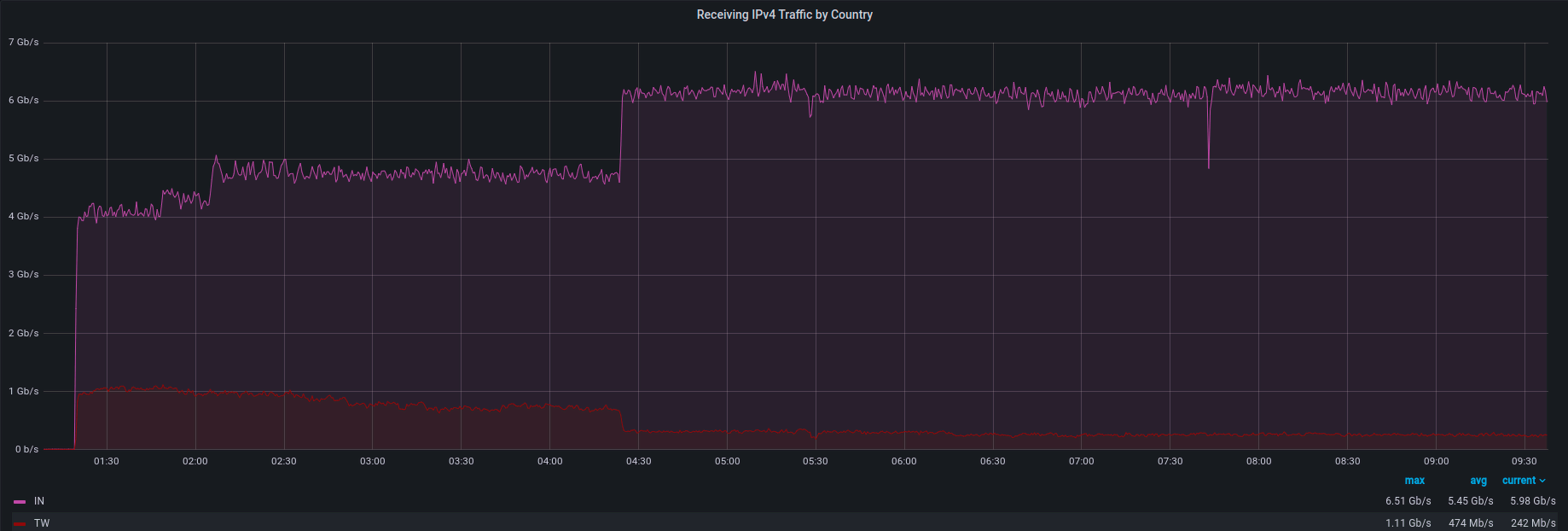
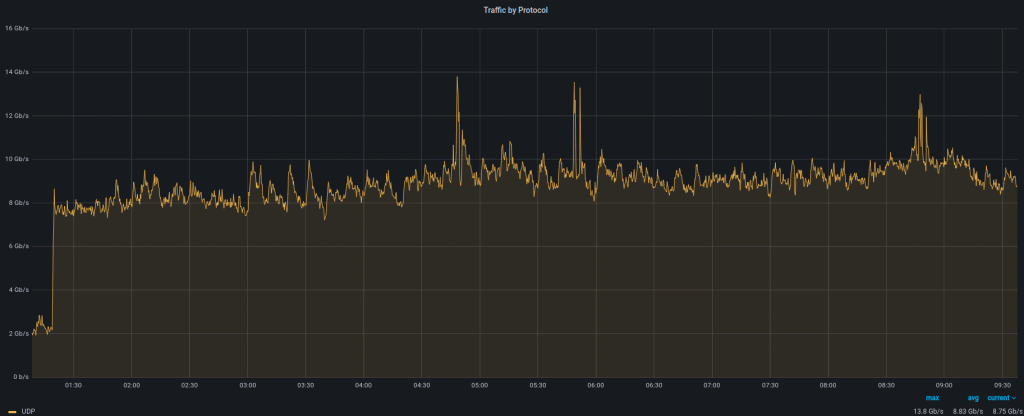
Attack protocol. This attack was mainly based on UDP as we didn’t see any unusual increases on the TCP graph.
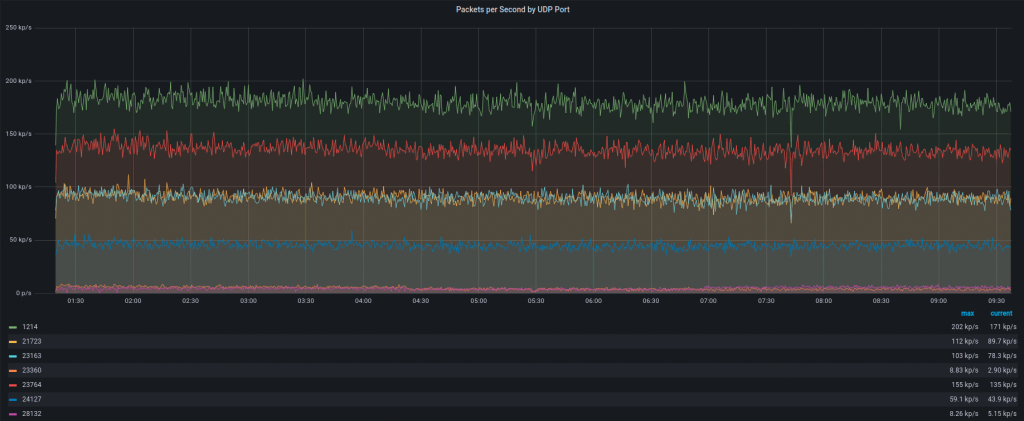
Attack type. It generated a large amount of traffic to random UDP ports. A few of them are seen on the graph below:
Summary
RTBH, as DDoS protection, is effective but eventually causes downtime. After implementing the traffic filtering solution in our infrastructure, we only drop malicious traffic instead of all of it. We’ve noticed that RTBH usage has decreased by 90–95%, resulting in a better uptime for our services and clients.

Tomas is a Site Reliability Engineer at Hostinger. He is interested in network and system engineering. When he is not working, he spends his free time with his family and plays football and video games.


Comments
March 12 2024
I just purchased the KVM 8 plan for two years to use as a shared environment for video game development amongst our startup studio. I'm very happy with the performance and security that Hostinger provides over many other popular hosting providers. I would like to see options for dedicated servers with the single threaded performance that the KVM processors provide. Our team was a little concerned that once our project scales, we may have to switch to a dedicated server and I didn't see the option available on the website.
March 26 2024
Hi, appreciate your input! It's great to hear our KVM 8 plan is working well for your video game development startup. We'll take note of your interest in dedicated servers with single-threaded performance for future consideration, as we're constantly refining our services to better suit our users' needs ?
March 27 2023
Once happend and my site worked fine.. thanks alot for the developers and the team I'm happy hostinger client