Wie integrieren Sie n8n mit Ollama für lokale LLM-Workflows?
May 14, 2026
/
Faradilla A.
/
11 Min. Lesezeit
Die Integration von n8n mit Ollama ermöglicht es Ihnen, verschiedene KI-Modelle in Ihren Automatisierungs-Workflow einzubinden, sodass dieser komplexe Vorgänge ausführen kann, die andernfalls nicht möglich wären.
Allerdings kann der Prozess knifflig sein, da Sie in beiden Tools verschiedene Einstellungen konfigurieren müssen, damit sie reibungslos zusammenarbeiten.
Sobald n8n und Ollama bereits auf Ihrem Server installiert sind, können Sie beide in vier einfachen Schritten integrieren:
- Fügen Sie den Ollama Chat Model-Knoten hinzu
- Wählen Sie das KI-Modell aus und passen Sie die Laufzeiteinstellungen des KI-Modells an.
- Konfigurieren Sie die Prompt-Einstellungen des KI-Agent-Knotens
- Senden Sie einen Test-Prompt, um die Funktion zu überprüfen.
Nach Abschluss dieser Schritte verfügen Sie über einen funktionierenden, von Ollama betriebenen Workflow zur KI-Verarbeitung, den Sie in ein umfassenderes Automatisierungssystem integrieren können. So können Sie zum Beispiel Messaging-Apps wie WhatsApp verbinden, um einen funktionsfähigen KI-Chatbot zu erstellen.
Darüber hinaus haben Sie mehr Kontrolle über Ihre Daten, wenn Sie die Anwendung lokal auf einem privaten Server wie einem Hostinger VPS ausführen. Damit eignet sich die Integration für die Automatisierung von Aufgaben mit sensiblen Informationen, etwa für die Zusammenfassung interner Dokumente oder die Erstellung eines unternehmensinternen Chatbots.
Sehen wir uns im Detail an, wie Sie Ollama mit n8n verbinden und auf Basis dieser Integration einen Chatbot erstellen. Zum Schluss erläutern wir auch die gängigen Anwendungsfälle für diese Integration und erweitern ihre Möglichkeiten mithilfe der LangChain-Knoten.
Voraussetzungen
Um n8n mit Ollama zu integrieren, müssen Sie die folgenden Voraussetzungen erfüllen:
- Ollama muss lokal installiert sein. Stellen Sie sicher, dass Sie Ollama lokal auf einem Virtual Private Server (VPS) installiert haben. Der Host muss über ausreichend Hardware verfügen, um die gewünschten KI-Modelle auszuführen; dafür können mehr als 8 GB RAM erforderlich sein.
- n8n muss eingerichtet und zugänglich sein. Sie installieren n8n auf einem VPS und erstellen ein Konto. Aus Kompatibilitätsgründen muss es auf demselben Server wie Ollama konfiguriert werden.
- Stellen Sie sicher, dass die erforderlichen Ports geöffnet sind. Vergewissern Sie sich, dass die Ports 11434 und 5678 auf Ihrem Server geöffnet sind, damit Ollama und n8n erreichbar sind. Wenn Sie sie auf einem Hostinger VPS hosten, prüfen Sie die Ports und konfigurieren Sie sie, indem Sie einfach unseren KI-Assistenten Kodee fragen.
- Grundlegende JSON-Kenntnisse. Lernen Sie, JSON zu lesen, da n8n-Knoten Daten in erster Linie in diesem Format austauschen. Dieses Verständnis hilft Ihnen, Daten gezielter auszuwählen und Fehler effizienter zu beheben.
Wichtig! Wir empfehlen dringend, sowohl n8n als auch Ollama für eine bessere Isolation im selben Docker-Container zu installieren. Das ist die Methode, mit der wir dieses Tutorial getestet haben; sie funktioniert also nachweislich.
Wenn Sie einen Hostinger-VPS verwenden, können Sie zunächst n8n oder Ollama in einem Docker-Container installieren, indem Sie einfach die entsprechende Betriebssystemvorlage auswählen – die Anwendung wird standardmäßig in einem Container installiert. Anschließend müssen Sie die andere App im selben Container installieren.
Ollama-Integration in n8n einrichten
Um Ollama mit n8n zu verbinden, müssen Sie den erforderlichen Knoten hinzufügen und mehrere Einstellungen konfigurieren. In diesem Abschnitt erläutern wir die einzelnen Schritte im Detail, einschließlich der Vorgehensweise zum Testen der Funktionalität der Integration.
1. Fügen Sie den Ollama Chat Model-Knoten hinzu
Durch das Hinzufügen des Ollama Chat Model-Knotens kann n8n über einen Konversationsagenten eine Verbindung zu Large Language Models (LLMs) auf der KI-Plattform herstellen.
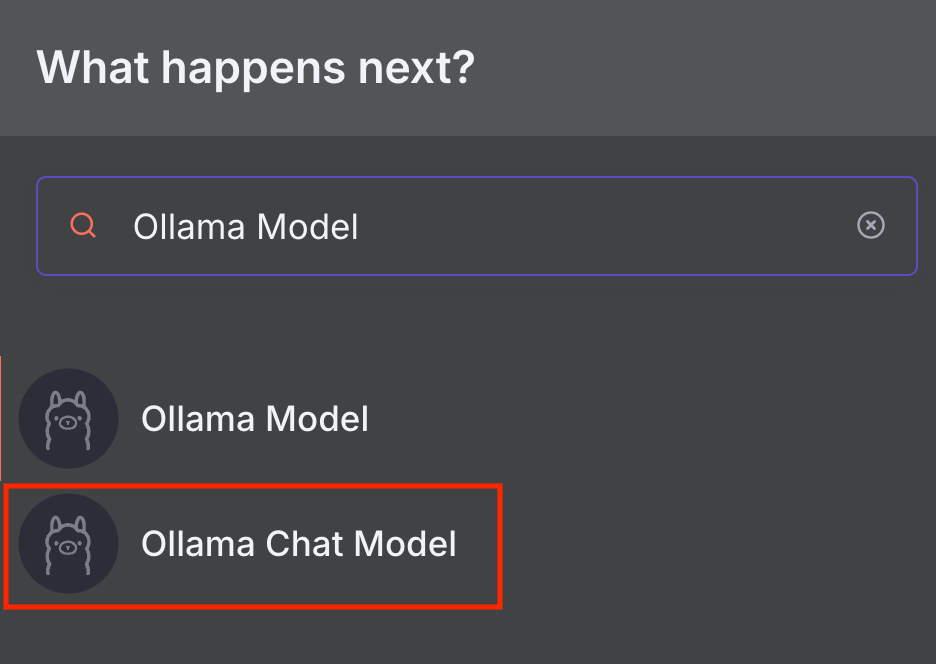
n8n bietet zwei Ollama-Knoten: Ollama Model und Ollama Chat Model. Das Ollama Chat Model ist speziell für Konversationen ausgelegt und verfügt über einen integrierten Basic LLM Chain-Knoten, der Ihre Nachricht an das ausgewählte Modell weiterleitet. Der Ollama Model-Knoten eignet sich hingegen für allgemeinere Aufgaben mit anderen Chain -Knoten – darauf gehen wir im LangChain-Abschnitt noch näher ein.
In diesem Tutorial verwenden wir den Ollama Chat Model-Knoten, da er sich einfacher nutzen und in einen umfassenderen Workflow integrieren lässt. So fügen Sie es in n8n hinzu:
- Greifen Sie auf Ihre n8n-Instanz zu. Je nach Ihrer Konfiguration sollten Sie die Seite im Webbrowser über den Hostnamen oder die IP-Adresse Ihres VPS öffnen können.
- Melden Sie sich bei Ihrem n8n-Konto an.
- Erstellen Sie einen neuen Workflow, indem Sie auf die Schaltfläche oben rechts auf Ihrer n8n-Startseite klicken.
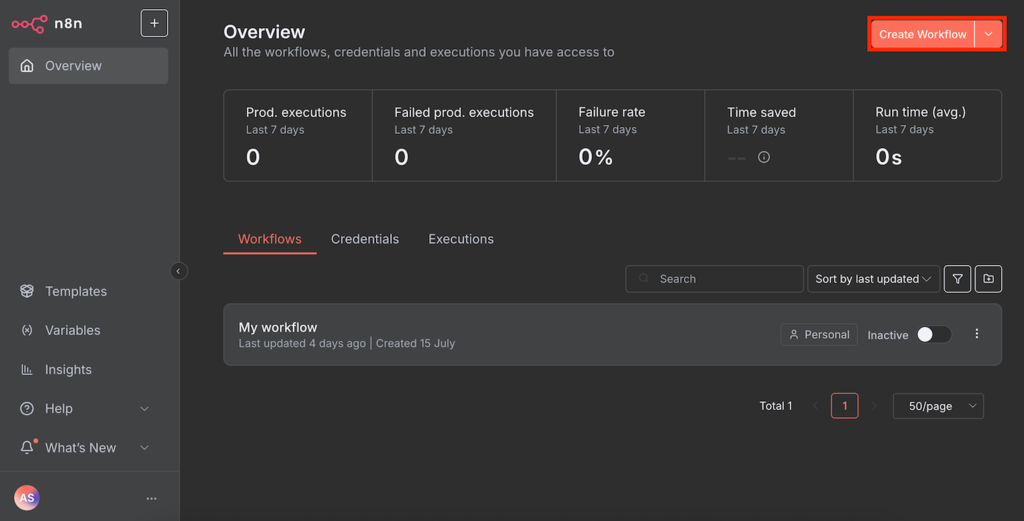
- Klicken Sie auf das Plus -Symbol und suchen Sie nach Ollama Chat Model.
- Klicken Sie auf den Knoten, um ihn hinzuzufügen.
Das Fenster zur Konfiguration des Knotens wird angezeigt. Fahren wir mit dem nächsten Schritt fort, um es einzurichten.
2. Wählen Sie Ihr Modell und Ihre Laufzeiteinstellungen
Bevor Sie ein KI-Modell auswählen und dessen Laufzeiteinstellungen konfigurieren, verbinden Sie n8n mit Ihrer selbst gehosteten Ollama-Instanz. So geht’s:
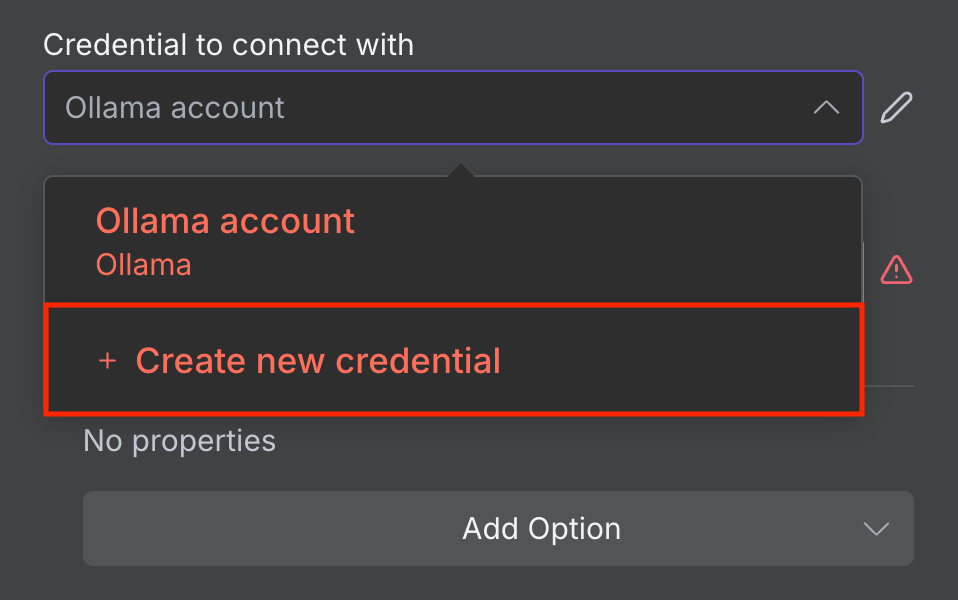
- Erweitern Sie im Fenster für die Knotenkonfiguration das Dropdown-Menü Credential to connect with.
- Wählen Sie Create new credential aus.
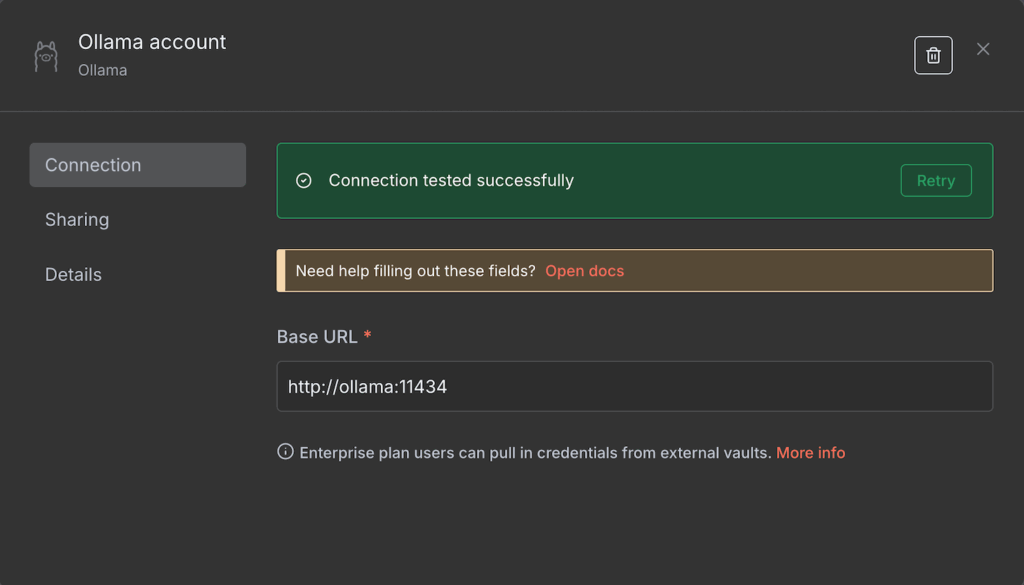
- Geben Sie die Basis-URL Ihrer Ollama-Instanz ein. Je nach Ihrer Hosting-Umgebung kann dies localhost oder der Name Ihres Ollama-Docker-Containers sein.
- Klicken Sie auf Save.
Wenn die Verbindung erfolgreich ist, wird eine Bestätigungsmeldung angezeigt. Stellen Sie andernfalls sicher, dass die Adresse korrekt ist und Ihre Ollama-Instanz läuft.
Sobald die Verbindung hergestellt ist, können Sie im Ollama-Modell-Knoten das zu verwendende LLM auswählen. Öffnen Sie dazu einfach das Dropdown-Menü Model und wählen Sie ein Modell aus der Liste aus. Wenn die Option ausgegraut ist, lässt sich das Problem durch Aktualisieren von n8n beheben.
Beachten Sie, dass n8n derzeit nur ältere Modelle wie Llama 3 und DeepSeek R1 unterstützt. Wenn das Menü Model einen Fehler und eine leere Liste anzeigt, liegt das höchstwahrscheinlich daran, dass in Ihrer Ollama-Instanz nur inkompatible Modelle vorhanden sind.
Um das zu beheben, laden Sie einfach andere Ollama-Modelle herunter. In der Ollama-CLI führen Sie dazu in Ihrer Ollama-Umgebung den folgenden Befehl aus:
ollama run model-name
Sie können auch ein Modell mit benutzerdefinierten Laufzeiteinstellungen verwenden, etwa mit einer höheren Temperatur. So erstellen Sie eines in Ollama CLI:
- Greifen Sie auf Ihre Ollama-Installation zu. Wenn Sie Docker verwenden, nutzen Sie den folgenden Befehl, wobei ollama dem tatsächlichen Namen Ihres Containers entspricht:
docker exec -it ollama bash
- Erstellen Sie eine neue Modelfile, in der die Laufzeiteinstellung Ihres Modells definiert ist. Zum Beispiel setzen wir die Temperatur unseres Llama-3-Modells auf 0.7:
echo "FROM llama3" > Modelfile
echo "PARAMETER temperature 0.7" >> Modelfile
- Führen Sie den folgenden Befehl aus, um die Modelfile-Konfiguration auf das Basis-Llama-3-Modell anzuwenden und ein benutzerdefiniertes LLM mit dem Namen llama3-temp07 zu erstellen:
ollama create llama3-temp07 -f Modelfile
Sobald Sie diese Schritte abgeschlossen haben, sollte n8n Ihr neues Llama-3-Modell mit der benutzerdefinierten Temperatur 0.7 verwenden.
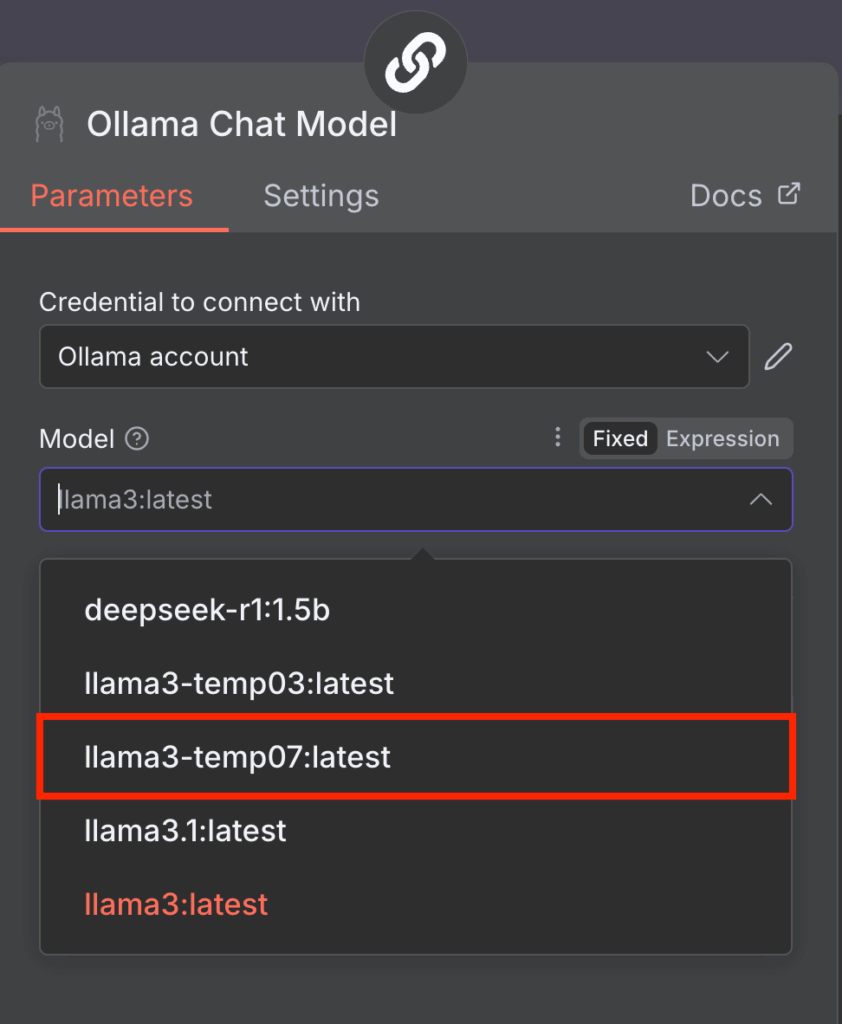
Ollama GUI verwalten
Wenn Sie Ollama GUI verwenden, sehen Sie sich unser Tutorial an, um mehr über die Benutzeroberfläche und die Verwaltung Ihrer Modelle zu erfahren.
3. Prompt-Einstellungen konfigurieren
Mit den Prompt-Einstellungen legen Sie fest, wie der Basic LLM Chain-Knoten Ihre Eingabe anpasst, bevor der Knoten die Eingabe zur Verarbeitung an Ollama weitergibt. Sie können zwar die Standardeinstellungen verwenden, sollten diese jedoch je nach Aufgabe anpassen.
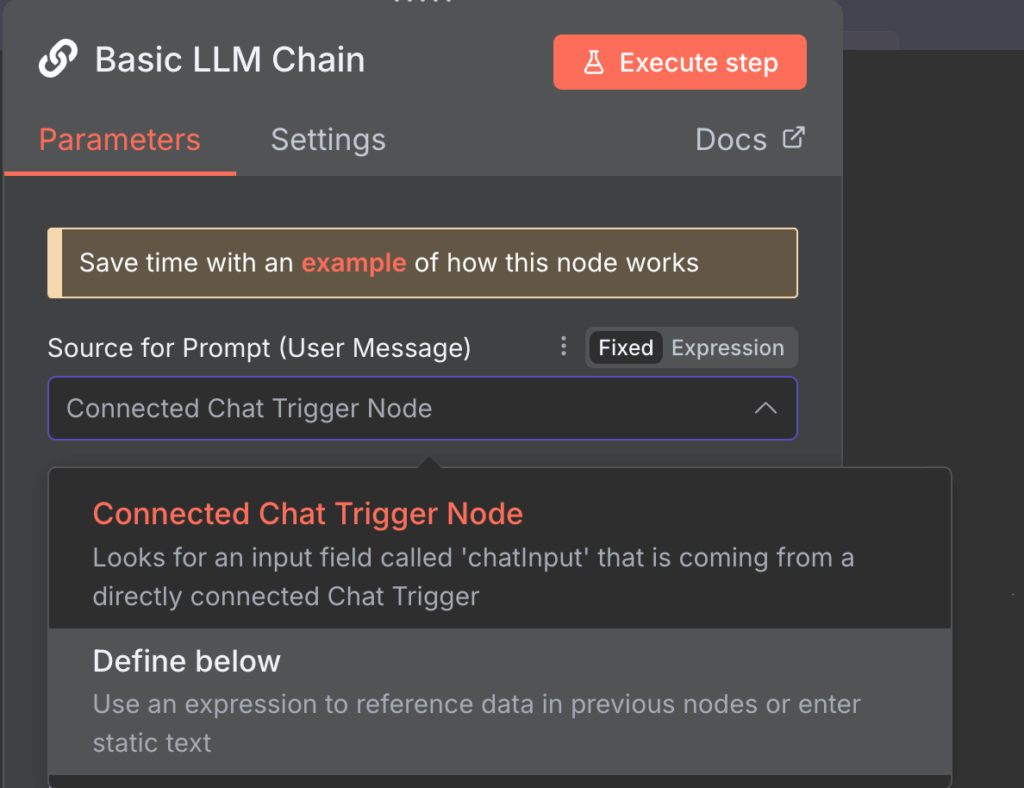
Hier sind zwei Möglichkeiten, die Prompt-Einstellungen des LLM-Chain-Knotens anzupassen, jeweils mit einem passenden Anwendungsbeispiel.
Connected Chat-Trigger-Knoten
Die Option des Connected Chat Trigger-Knoten verwendet Nachrichten aus dem standardmäßigen Chat-Knoten als Eingabe für Ollama. Dies ist standardmäßig der ausgewählte Modus und gibt Nachrichten unverändert weiter.
Sie können den Nachrichten jedoch zusätzliche Prompts hinzufügen, um die Ausgabe von Ollama zu verändern. Klicken Sie dazu in der Einstellung Chat Messages auf die Schaltfläche Add Prompt (wenn Sie ein Chat-Modell verwenden) und wählen Sie eine von drei zusätzlichen Prompt-Optionen aus:
- KI. Geben Sie im Feld Message ein Beispiel für die erwartete Antwort ein. Das KI-Modell wird versuchen, auf dieselbe Weise zu antworten wie der bereitgestellte Text.
- System. Schreiben Sie eine Nachricht, die die Antworten des Modells steuert. Sie können zum Beispiel festlegen, welchen Ton die KI verwenden soll oder welche Wörter sie in ihren Antworten vermeiden soll.
- Benutzer. Fügen Sie ein Beispiel für die Eingabe des Benutzers für die KI hinzu, etwa eine Nachricht, eine URL oder ein Bild. Wenn Sie der KI ein Beispiel dafür geben, was sie von Nutzern erwarten kann, liefert sie konsistentere Antworten.
Definieren Sie unten
Die Option „Weiter unten definieren“ eignet sich, wenn Sie einen vorformulierten Prompt eingeben möchten, den Sie wiederverwenden können. Es eignet sich auch ideal zum Weiterleiten dynamischer Daten, da Sie diese mit Expressions erfassen können – einer JavaScript-Bibliothek, die die Eingabe verarbeitet oder ein bestimmtes Feld auswählt.
Zum Beispiel ruft der vorherige Knoten Daten zur Ressourcennutzung Ihres VPS ab, und Sie möchten diese mit KI analysieren. In diesem Fall bleibt der Prompt unverändert, aber die Nutzungsmetriken ändern sich fortlaufend.
Ihr Prompt könnte beispielsweise wie folgt aussehen, wobei {{ $json.metric }} das Feld ist, das die dynamischen Daten zur Ressourcennutzung Ihres Servers enthält:
Die aktuelle Auslastung meines Servers beträgt {{ $json.metric }}. Analysiere diese Daten und vergleiche sie mit dem bisherigen Nutzungsverlauf, um zu prüfen, ob dies ungewöhnlich ist.Beachten Sie, dass Sie weiterhin zusätzliche Prompts wie im vorherigen Modus hinzufügen können, um der KI mehr Kontext zu geben.
4. Senden Sie einen Test-Prompt
Das Senden eines Test-Prompts bestätigt, dass Ihr Ollama-Modell ordnungsgemäß funktioniert, wenn es über n8n Eingaben empfängt. Am einfachsten geht das, indem Sie anhand der folgenden Schritte eine Beispielnachricht eingeben:
- Speichern Sie Ihren Workflow, indem Sie auf die Schaltfläche oben rechts auf Ihrer Arbeitsfläche klicken.
- Bewegen Sie den Mauszeiger über den Chat trigger-Knoten und klicken Sie auf Open chat.
- Senden Sie in der Chat-Oberfläche eine Testnachricht.
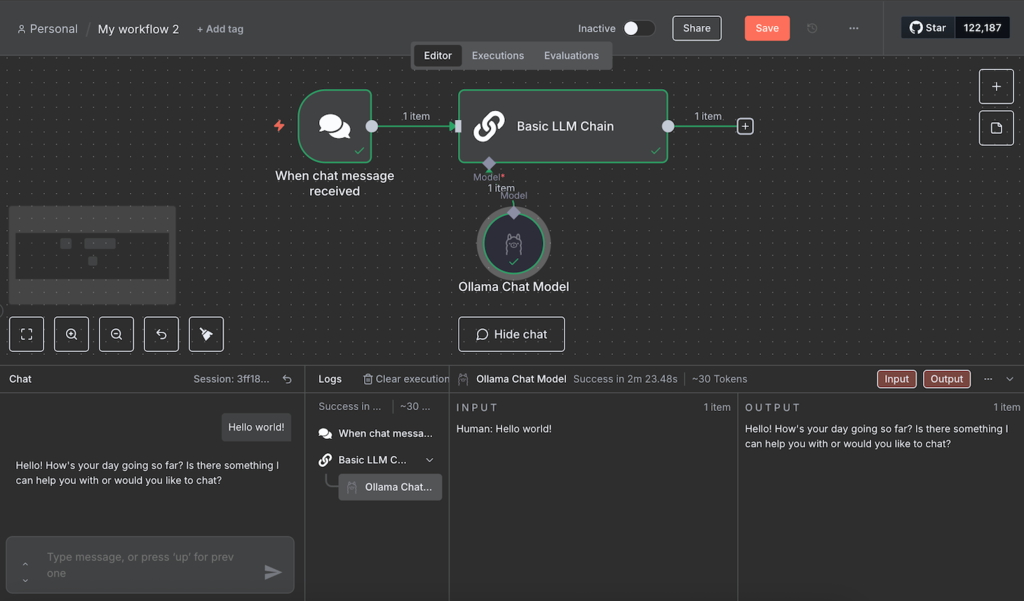
Warten Sie, bis der Workflow Ihre Nachricht vollständig verarbeitet hat. Während unserer Tests blieb der Workflow einige Male hängen. Wenn Sie auf dasselbe Problem stoßen, laden Sie n8n einfach neu und senden Sie eine neue Nachricht.
Wenn der Test erfolgreich ist, werden alle Knoten grün. Den JSON-Eingang und -Ausgang jedes Knotens können Sie anzeigen, indem Sie auf den jeweiligen Knoten doppelklicken und die Bereiche auf beiden Seiten des Konfigurationsfensters prüfen.
So erstellen Sie einen Chatbot-Workflow mit Ollama und n8n
Durch die Integration von Ollama in n8n können Sie verschiedene Aufgaben mit LLMs automatisieren, darunter einen KI-gestützten Workflow in n8n erstellen, der auf Benutzeranfragen reagiert, ähnlich wie ein Chatbot. In diesem Abschnitt werden die Schritte zur Entwicklung eines solchen Systems erläutert.
Wenn Sie ein Automatisierungssystem für andere Aufgaben erstellen möchten, finden Sie in unseren n8n-Workflow-Beispielen Inspiration.
1. Fügen Sie einen Trigger-Knoten hinzu
Der Trigger-Knoten in n8n legt fest, welches Ereignis Ihren Workflow startet. Zu den verschiedenen Möglichkeiten, einen Chatbot zu erstellen, gehören vor allem diese:
Chat-Trigger
Standardmäßig verwendet der Ollama-Chat-Modell-Knoten Chat message als Auslöser; der Workflow wird gestartet, sobald eine Nachricht eingeht.
Dieser standardmäßige Chat -Knoten eignet sich perfekt, um einen Chatbot zu entwickeln. Damit es funktioniert, müssen Sie nur die Chat-Oberfläche öffentlich zugänglich machen.
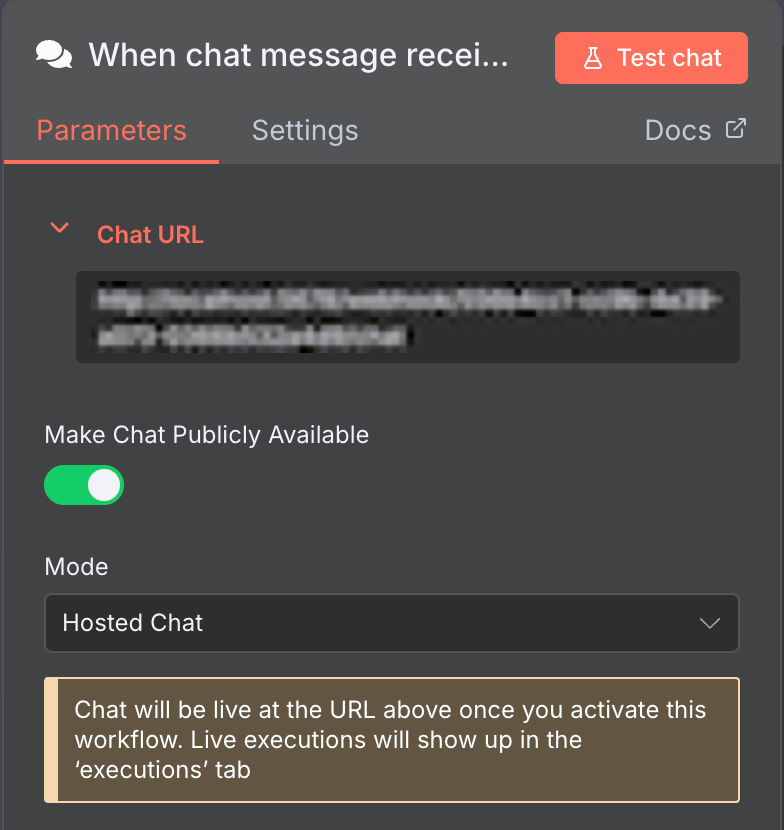
Öffnen Sie dazu den Chat -Knoten und klicken Sie auf den Schalter Make Chat Publicly Available. Anschließend können Sie diese Chatfunktion mit einer Benutzeroberfläche in Ihren benutzerdefinierten Chatbot integrieren.
Trigger-Knoten für Messaging-Apps
n8n verfügt über Trigger-Knoten, die Eingaben aus beliebten Messaging-Apps wie Telegram und WhatsApp empfangen. Sie eignen sich, wenn Sie für solche Anwendungen einen Bot erstellen möchten.
Die Konfiguration dieser Knoten ist ziemlich knifflig, weil Sie für die Verbindung mit ihren APIs ein Entwicklerkonto und Authentifizierungsschlüssel benötigen. In der entsprechenden Dokumentation erfahren Sie mehr darüber, wie Sie sie konfigurieren.
Webhook-Trigger
Der Webhook -Trigger startet Ihren Workflow, sobald die zugehörige Endpunkt-URL eine HTTP-Anfrage empfängt. Das ist geeignet, wenn Sie Ihren Chatbot über andere Ereignisse als das Senden einer Nachricht starten möchten, etwa per Klick.
In den folgenden Schritten verwenden wir diesen Knoten, um unseren Workflow jedes Mal zu starten, wenn ein Discord-Chatbot eine Nachricht empfängt. Wenn Sie mitmachen möchten, sehen Sie sich zunächst unser Tutorial n8n mit Discord integrieren an. Dort erfahren Sie, wie Sie einen Discord-Bot erstellen.
Wichtig! Wenn Ihre Webhook-URL mit localhost beginnt, ersetzen Sie localhost durch die Domain, den Hostnamen oder die IP-Adresse Ihres VPS. Sie können dies tun, indem Sie die Umgebungsvariable WEBHOOK_URL von n8n in seiner Konfigurationsdatei ändern.
2. Verbinden Sie den Ollama-Knoten
Wenn Sie den Ollama-Knoten verbinden, kann der Trigger-Knoten Benutzereingaben zur Verarbeitung weiterleiten.
Der Ollama Chat Model-Knoten lässt sich nicht direkt mit Trigger-Knoten verbinden und kann nur mit einem KI-Knoten integriert werden. Standardmäßig ist der Basic LLM Chain-Knoten ausgewählt, Sie können für komplexere Verarbeitungen aber auch andere Chain -Knoten verwenden.
Einige Chain -Knoten unterstützen zusätzliche Tools zur Verarbeitung Ihrer Daten. Mit dem AI Agent -Knoten können Sie zum Beispiel einen Parser hinzufügen, um die Ausgabe neu zu formatieren, oder einen Speicher einbinden, der die vorherigen Antworten speichert.
Für einen Chatbot, der keine komplexe Datenverarbeitung erfordert, wie unseren Discord-Chatbot, reicht die Basic LLM Chain aus.
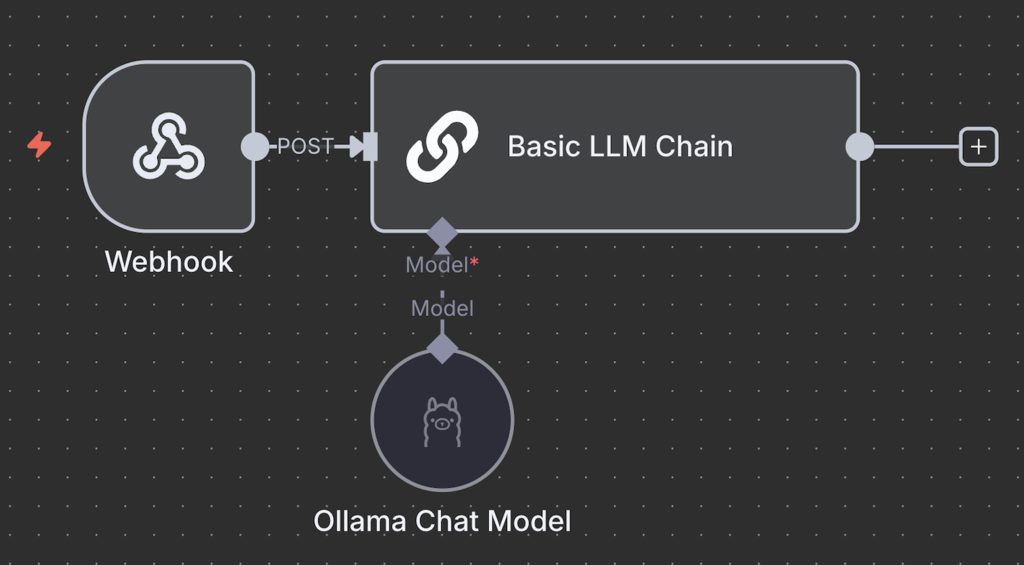
Verbinden Sie also den Trigger-Knoten mit dem Basic LLM Chain -Knoten und legen Sie fest, wie die Eingabe übergeben wird. Verwenden Sie Fixed, um die Nachricht als Prompt zu übergeben. Wählen Sie in der Zwischenzeit Expression aus, um dynamische Daten zu verwenden oder die Eingabe zu bearbeiten, bevor Sie sie an Ollama weiterleiten.
Zum Beispiel verwenden wir den folgenden Ausdruck, um das JSON-Feld body.content als Eingabe auszuwählen, das sich je nach den Discord-Nachrichten der Benutzer ändert:
{{ $json.body.content }}3. Geben Sie die Antwort aus
Wenn Sie die Antwort aus dem KI-Agenten – oder Basic LLM Chain-Knoten ausgeben, können Nutzer die Antwort Ihres Bots sehen. An dieser Stelle können Sie die Ausgabe nur in der Chatoberfläche oder im Ausgabebereich des Knotens lesen.
Verwenden Sie zum Senden der Antwort denselben Knoten wie für Ihren Trigger. Wenn Sie beispielsweise einen WhatsApp-Chatbot entwickeln, verbinden Sie den Knoten WhatsApp send message.
Wenn Sie den standardmäßigen Chat -Trigger verwenden, können Sie den Webhook-Knoten nutzen, um die Nachricht an Ihren individuell programmierten Bot oder Ihre Chatbot-Oberfläche weiterzuleiten.
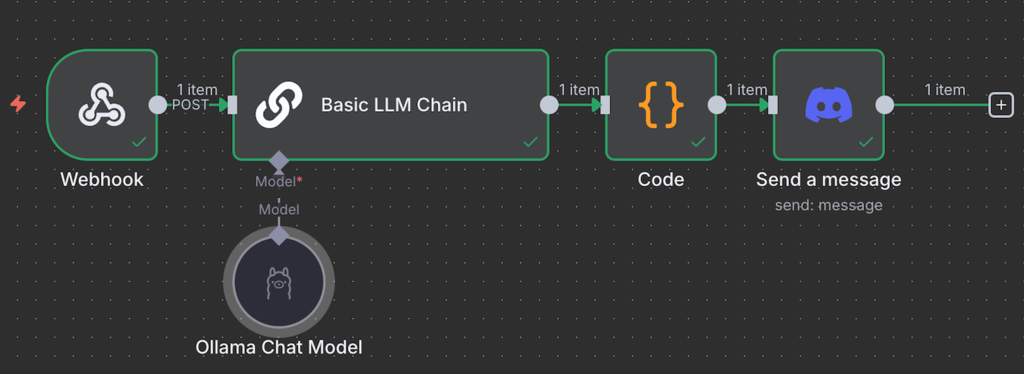
Da der Workflow unseres Discord-Bots den Webhook -Trigger verwendet, können wir für die Ausgabe auch den Webhook -Knoten nutzen. Alternativ können wir denselben Bot verwenden, um die Antwort zu senden, indem wir den Discord Send a Message-Knoten verbinden und in unseren Chatbot integrieren. Der fertige Workflow sieht so aus:
Sie wissen nicht, wie Sie einen vollständigen Workflow erstellen?
n8n stellt verschiedene sofort einsatzbereite Workflows bereit, die Sie ganz einfach in Ihre Canvas importieren können. Damit können Sie ein KI-gestütztes Automatisierungssystem erstellen, ohne den Workflow von Grund auf neu entwickeln zu müssen. In unserem Tutorial zu den besten n8n-Vorlagen finden Sie sorgfältig ausgewählte, sofort einsetzbare Workflows für verschiedene Anwendungsfälle.
Was sind die besten Anwendungsfälle für die n8n-Ollama-Integration?
Als eines der leistungsstärksten KI-Automatisierungstools ermöglicht Ihnen die Integration von n8n mit Ollamas anpassbaren LLMs, eine Vielzahl von Aufgaben zu automatisieren.
Hier sind Beispiele für Aufgaben, die Sie mit n8n automatisieren und mit KI erledigen können:
- Automatisierter Workflow für den Kundensupport. Nutzen Sie die LLMs von Ollama, um über n8n Antworten auf Kundenanfragen zu erstellen, Tickets zusammenzufassen oder Anliegen auf Plattformen wie Zendesk und Intercom weiterzuleiten.
- Kontextbezogenes Verfassen von E-Mails. E-Mails für unterschiedliche Kontexte oder Aufgaben automatisch mit Ollama entwerfen. So können Sie beispielsweise einem neuen Lead eine Willkommensnachricht senden, Kunden an das Auslaufen ihres Abonnements erinnern und Produktaktualisierungen anhand verschiedener Ereignisse ankündigen.
- Assistent für die interne Wissensdatenbank. Verwenden Sie n8n, um interne Dokumentation wie Notion, Confluence oder Airtable abzufragen und die Daten an Ollama zu übergeben, damit Ollama intelligente Antworten oder Zusammenfassungen für interne Teamanfragen erstellt.
- Datenextraktion und Zusammenfassung. Verwenden Sie n8n, um eingehende Textdokumente zu überwachen, deren Text zu extrahieren und mit Ollama wichtige Informationen herauszuziehen – nützlich zum Zusammenfassen von Berichten, Rechnungen oder juristischen Dokumenten.
- Automatisierte Pipeline für die Content-Produktion. Erstellen Sie Inhalte mit n8n und Ollama, indem Sie einen Workflow erstellen, der die Keyword-Recherche sowie den Schreib- und Bearbeitungsprozess automatisiert.
- Sichere Chatbots für den internen Einsatz. Erstellen Sie interne Chatbots, die mit sensiblen internen Daten arbeiten, wobei n8n die Orchestrierung übernimmt und Ollama das LLM aus Sicherheits- und Datenschutzgründen vollständig offline ausführt.
Warum sollten Sie Ihre n8n-Ollama-Workflows bei Hostinger hosten?
Wenn Sie Ihre n8n-Ollama-Workflows bei Hostinger hosten, profitieren Sie von verschiedenen Vorteilen gegenüber der Nutzung eines eigenen Geräts oder des offiziellen Hosting-Tarifs. Hier sind einige der Vorteile:
- Mehr Kontrolle. Der n8n-VPS-Hosting -Dienst von Hostinger bietet Benutzern vollen Root-Zugriff auf ihre Servereinstellungen und Daten. Damit können Sie Ihre Hosting-Umgebungen für n8n und Ollama an Ihre spezifischen Anforderungen anpassen.
- Verbesserter Datenschutz. Da Sie n8n und Ollama auf einem Server hosten, über den Sie die vollständige Kontrolle haben, können Sie Zugriffsbeschränkungen und Sicherheitseinstellungen frei anpassen.
- Skalierbarkeit. Die VPS-Tarife von Hostinger lassen sich ohne Ausfallzeit problemlos upgraden und bieten die n8n-Vorlage für den Queue-Modus, mit der Sie Ihre Aufgaben auf mehrere Worker verteilen können.
- Optimierte Einrichtung. Mit unseren VPS-Vorlagen installieren Sie n8n oder Ollama mit nur einem Klick und machen den Prozess damit effizienter.
- Einfache Verwaltung. Die Verwaltung eines Hostinger-VPS ist mit dem intuitiven hPanel-Kontrollpanel oder dem integrierten Browser-Terminal ganz einfach. Auch Einsteiger können unseren KI-Assistenten Kodee per Chat mit Systemadministrationsaufgaben beauftragen.

Den LM Ollama-Knoten von LangChain in n8n verwenden
LangChain ist ein Framework, das die Integration von LLMs in Anwendungen erleichtert. In n8n umfasst diese Implementierung das Verbinden verschiedener Tool-Knoten und KI-Modelle, um bestimmte Verarbeitungsfunktionen zu erreichen.
In n8n verwendet die LangChain-Funktion Cluster-Knoten – eine Gruppe miteinander verbundener Knoten, die in Ihrem Workflow gemeinsam eine Funktion bereitstellen.
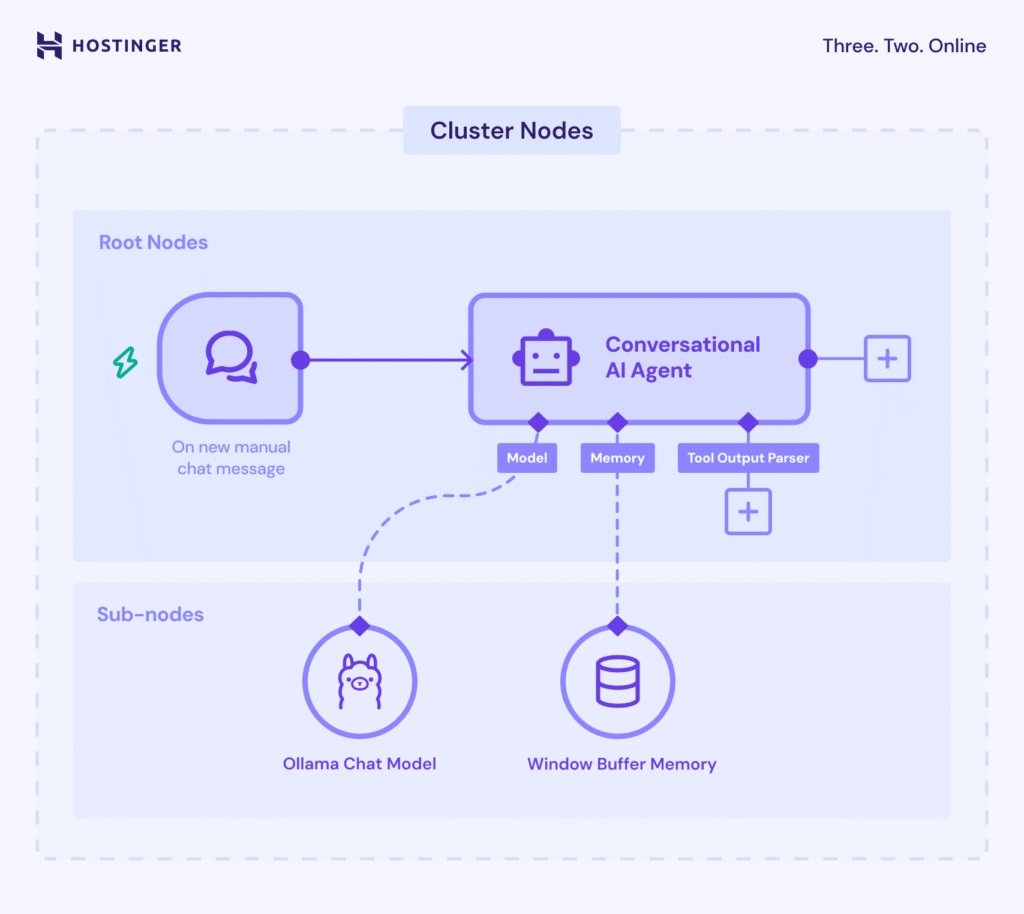
Cluster-Knoten bestehen aus zwei Teilen: Root-Knoten, die die Hauptfunktionalität festlegen, und Unterknoten, die die LLM-Funktion oder zusätzliche Features hinzufügen.
Der wichtigste Teil der LangChain-Implementierung in n8n ist die Chain innerhalb der Root-Knoten. Es führt die Logik verschiedener KI-Komponenten wie des Ollama-Modells und des Parser-Knotens zusammen und richtet sie ein, um ein stimmiges Gesamtsystem zu schaffen.
Hier sind die Chains in n8n und ihre Funktionen:
- Einfache LLM-Kette. Damit legen Sie den Prompt fest, den das KI-Modell verwendet, sowie optional einen Parser, der die Antwort neu formatiert.
- Abruf-Frage-und-Antwort-Kette. Ermöglicht Ihnen, von KI verarbeitete Daten über Vektorspeicher abzurufen – Datenbanken, die Informationen in numerischer Form speichern.
- Zusammenfassungskette. Fasst die Inhalte mehrerer Dokumente oder Eingaben zusammen.
- Sentimentanalyse. Analysiert die Stimmung des Eingabetextes und ordnet sie Kategorien wie positiv, neutral und negativ zu.
- Textklassifikator. Sortiert Eingabedaten anhand der angegebenen Kriterien und Parameter in verschiedene benutzerdefinierte Kategorien.
Beim Erstellen eines Workflows in n8n können Ihnen auch Agents begegnen – Untergruppen von Chains, die Entscheidungen treffen können. Während Chains auf der Grundlage einer Reihe vordefinierter Regeln arbeiten, nutzt der Agent das verbundene LLM, um die als Nächstes auszuführenden Aktionen zu bestimmen.
Wie geht es weiter, nachdem Sie n8n mit Ollama verbunden haben?
Da sich die Trends in der Automatisierung ständig weiterentwickeln, hilft Ihnen die Einführung eines automatischen Datenverarbeitungssystems dabei, der Konkurrenz einen Schritt voraus zu sein. In Verbindung mit KI können Sie ein System schaffen, das die Entwicklung und das Management Ihrer Projekte auf ein neues Niveau hebt.
Die Integration von Ollama in Ihren n8n-Workflow erweitert Ihre KI-gestützte Automatisierung über die Möglichkeiten des integrierten Knotens hinaus – und dank der Kompatibilität von Ollama mit verschiedenen LLMs können Sie unterschiedliche KI-Modelle auswählen und gezielt an Ihre Anforderungen anpassen.
Zu verstehen, wie Sie Ollama in n8n einbinden, ist nur der erste Schritt, um KI-gestützte Automatisierung in Ihrem Projekt umzusetzen. Angesichts der Vielzahl möglicher Anwendungsfälle besteht der nächste Schritt darin, zu experimentieren und einen Workflow zu entwickeln, der am besten zu Ihrem Projekt passt.
Wenn Sie zum ersten Mal mit n8n oder Ollama arbeiten, ist Hostinger der richtige Ausgangspunkt. Neben leistungsstarken VPS-Tarifen bieten wir Ihnen auch einen umfassenden Katalog mit Tutorials zu n8n, der Ihnen den Einstieg in die Automatisierung erleichtert.
Alle Tutorial-Inhalte auf dieser Website unterliegen Hostingers strengen redaktionellen Standards und Normen.

Faradilla, auch bekannt als Ninda, ist Content Marketing Specialist bei Hostinger mit über fünf Jahren Erfahrung und einem zehnjährigen Hintergrund als Linguistin. Sie möchte Technologie für alle zugänglich machen, indem sie komplexe Anleitungen in klare und leicht verständliche Schritt-für-Schritt-Guides verwandelt. In ihrer Freizeit interessiert sie sich für Biowissenschaften oder schaut gerne lustige Tiervideos. Vernetzen Sie sich mit ihr auf LinkedIn.


Comments
0 responses