Comment intégrer n8n à Ollama pour les flux de travail LLM locaux ?
Sep 10, 2025
/
Chaimaa C.
/
12 minutes de lecture
L’intégration de n8n à Ollama vous permet d’exploiter divers modèles d’IA dans votre flux de travail automatisé, ce qui lui permet d’effectuer des opérations complexes qui seraient autrement impossibles.
Cependant, le processus peut s’avérer délicat, car vous devez configurer divers paramètres sur les deux outils afin qu’ils fonctionnent de manière transparente.
Si n8n et Ollama sont déjà installés sur votre serveur, vous pouvez les intégrer en quatre étapes simples :
- Ajoutez le nœud du modèle de chat Ollama
- Choisissez le modèle d’IA et ajustez ses paramètres d’exécution
- Configurez les paramètres d’invite du nœud de l’agent IA
- Envoyez une invite de test pour vérifier le bon fonctionnement
Une fois ces étapes terminées, vous disposerez d’un flux de travail de traitement IA fonctionnel, alimenté par Ollama, que vous pourrez intégrer dans un système d’automatisation plus complet. Par exemple, vous pouvez connecter des applications de messagerie telles que WhatsApp pour créer un chatbot IA fonctionnel.
De plus, le fait de l’exécuter localement sur un serveur privé tel qu’un VPS Hostinger vous offre un niveau de contrôle plus élevé sur vos données. Cette intégration est donc particulièrement adaptée à l’automatisation de tâches impliquant des informations sensibles, telles que la synthèse de documents internes ou la création d’un chatbot interne.
Voyons en détail comment connecter Ollama à n8n et créer un chatbot basé sur cette intégration. À la fin, nous expliquerons également les cas d’utilisation courants de cette intégration et étendrons ses capacités à l’aide des nœuds LangChain.
Prérequis
Pour intégrer n8n à Ollama, vous devez remplir les conditions préalables suivantes :
- Ollama doit être installé localement. Assurez-vous d’avoir installé Ollama localement sur un serveur privé virtuel (VPS). L’hôte doit disposer d’un matériel suffisant pour exécuter les modèles d’IA souhaités, ce qui peut nécessiter plus de 8 Go de RAM.
- n8n doit être configuré et accessible. Installez n8n sur un VPS et créez un compte. Il doit être configuré sur le même serveur qu’Ollama en raison de contraintes de compatibilité.
- Assurez-vous que les ports nécessaires sont ouverts. Vérifiez que les ports 11434 et 5678 de votre serveur sont ouverts afin de garantir l’accessibilité d’Ollama et de n8n. Si vous les hébergez sur Hostinger VPS, vérifiez les ports et configurez-les en demandant simplement à notre assistant Kodee IA.
- Connaissances de base en JSON. Apprenez à lire le JSON, car les nœuds n8n échangent principalement des données dans ce format. Le comprendre vous aidera à sélectionner les données et à résoudre les erreurs plus efficacement.
Important ! Nous vous recommandons vivement d’installer n8n et Ollama dans le même conteneur Docker pour une meilleure isolation. C’est la méthode que nous avons utilisée pour tester ce tutoriel, elle a donc fait ses preuves.
Si vous utilisez un VPS Hostinger, vous pouvez commencer par installer n8n ou Ollama dans un conteneur Docker en sélectionnant simplement le template d’OS correspondant. L’application sera installée dans un conteneur par défaut. Vous devrez ensuite installer l’autre application dans le même conteneur.
Comment configurer l’intégration d’Ollama dans n8n
Pour connecter Ollama à n8n, il faut ajouter le nœud nécessaire et configurer plusieurs paramètres. Dans cette section, nous allons expliquer les étapes en détail, y compris comment tester le fonctionnement de l’intégration.
1. Ajouter le nœud Ollama Chat Model
L’ajout du nœud Ollama Chat Model permet à n8n de se connecter à de grands modèles linguistiques (LLM) sur la plateforme IA via un agent conversationnel.
n8n propose deux nœuds Ollama : Ollama Model et Ollama Chat Model. Le nœud Ollama Chat Model est spécialement conçu pour la conversation et dispose d’un nœud Basic LLM Chain intégré qui transmet votre message au modèle choisi. Le nœud Ollama Model, quant à lui, convient à des tâches plus générales avec d’autres nœuds Chain. Nous aborderons ce sujet plus en détail dans la section LangChain.
Dans ce tutoriel, nous utiliserons le nœud Ollama Chat Model, car il est plus facile à utiliser et s’intègre à un flux de travail plus complet. Voici comment l’ajouter à n8n :
- Accédez à votre instance n8n. Vous devriez pouvoir l’ouvrir dans un navigateur web en utilisant le nom d’hôte ou l’adresse IP de votre VPS, selon votre configuration.
- Connectez-vous à votre compte n8n.
- Créez un nouveau flux de travail en cliquant sur le bouton en haut à droite de la page principale de n8n.
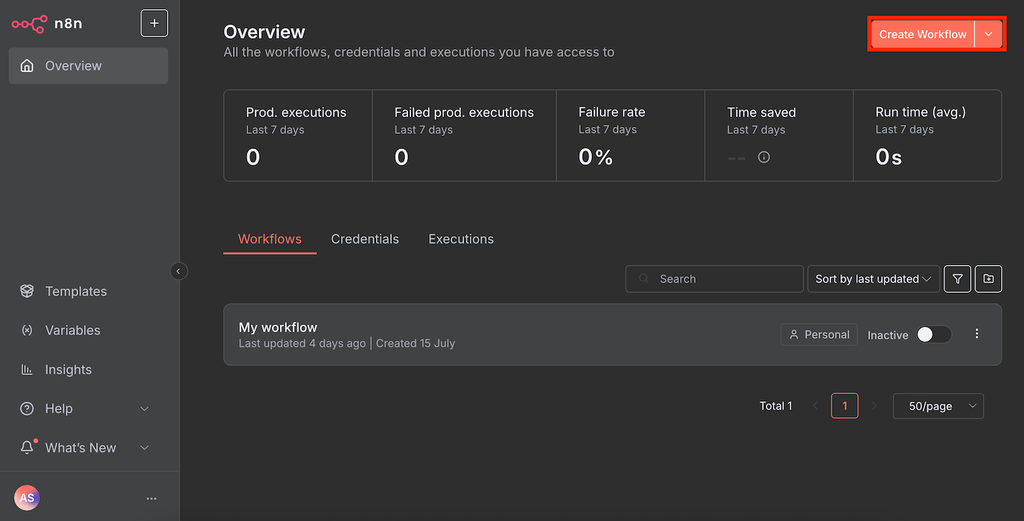
- Cliquez sur l’icône « + » et recherchez « Ollama Chat Model ».
- Ajoutez le nœud en cliquant dessus.
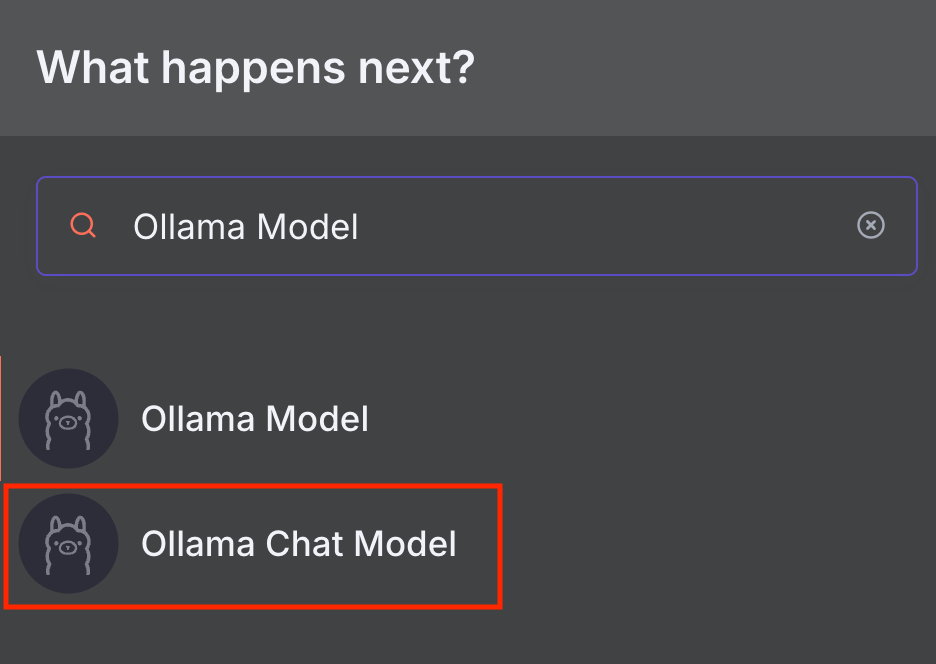
La fenêtre de configuration du nœud apparaîtra. Passons à l’étape suivante pour le configurer.
2. Choisir votre modèle et vos paramètres d’exécution
Avant de choisir un modèle d’IA et de configurer ses paramètres d’exécution, connectez n8n à votre instance Ollama auto-hébergée. Voici comment procéder :
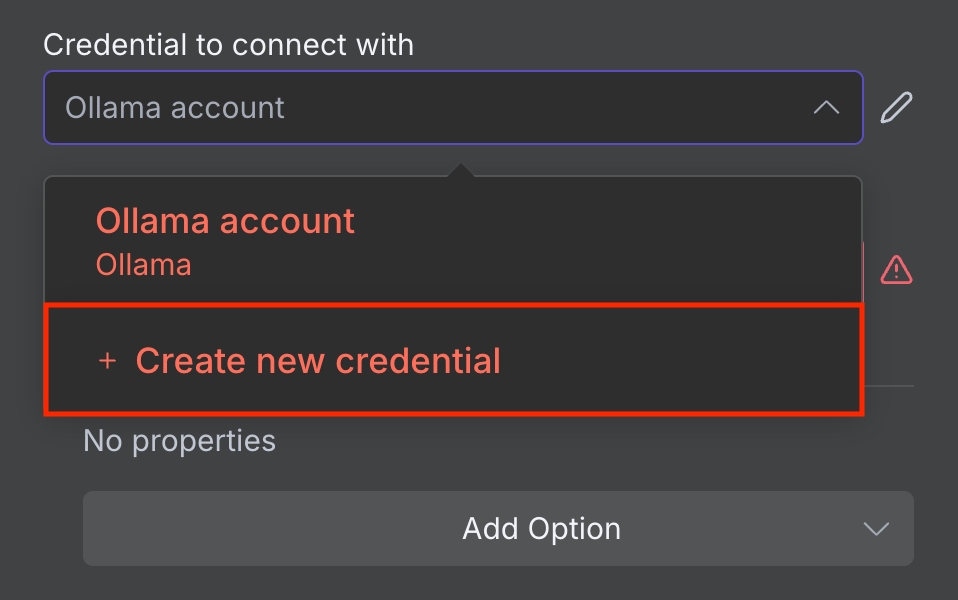
- Dans la fenêtre de configuration du nœud, développez le menu déroulant Credential to connect with.
- Sélectionnez Create new credential.
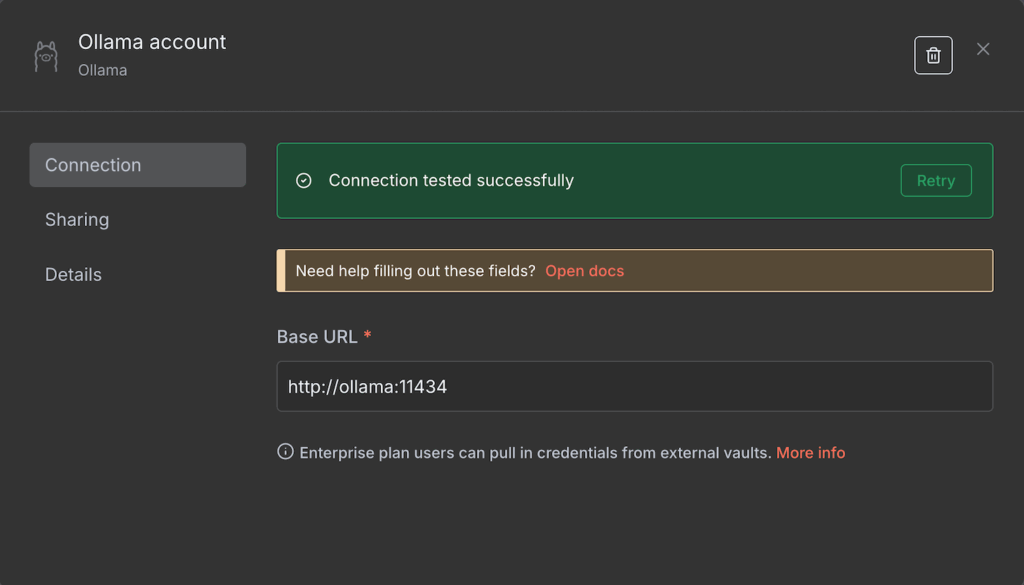
- Saisissez l’URL de base de votre instance Ollama. Selon votre environnement d’hébergement, il peut s’agir de localhost ou du nom de votre conteneur Docker Ollama.
- Cliquez sur Enregistrer.
Si la connexion est établie, un message de confirmation s’affiche. Sinon, vérifiez que l’adresse est correcte et que votre instance Ollama est en cours d’exécution.
Une fois connecté, vous pouvez choisir le LLM à utiliser dans votre nœud de modèle Ollama. Pour ce faire, il suffit de développer le menu déroulant Model et d’en sélectionner un dans la liste. S’il est grisé, actualisez n8n pour résoudre le problème.
Notez que n8n ne prend actuellement en charge que les anciens modèles tels que Llama 3 et DeepSeek R1. Si le menu Model affiche une erreur et une liste vide, cela est probablement dû au fait que votre Ollama ne dispose que de modèles incompatibles.
Pour résoudre ce problème, il suffit de télécharger d’autres modèles Ollama. Sur Ollama CLI, pour ce faire, exécutez la commande suivante dans votre environnement Ollama :
ollama run nom-du-modèle
Vous pouvez également utiliser un modèle avec des paramètres d’exécution personnalisés, tels qu’une température plus élevée. Voici comment en créer un dans Ollama CLI :
- Accédez à votre installation Ollama. Si vous utilisez Docker, utilisez la commande suivante en remplaçant ollama par le nom réel de votre conteneur :
docker exec -it ollama bash
- Créez un nouveau modelfile définissant le paramètre d’exécution de votre modèle. Par exemple, nous allons régler la température de notre modèle Llama 3 sur 0,7 :
echo "FROM llama3" > Modelfile
echo "PARAMETER temperature 0.7" >> Modelfile
- Exécutez la commande suivante pour appliquer la configuration du fichier modèle au modèle Llama 3 de base, créant ainsi un LLM personnalisé appelé llama3-temp07 :
ollama create llama3-temp07 -f Modelfile
Une fois ces étapes terminées, n8n devrait lire votre nouveau modèle Llama 3 avec la température personnalisée de 0,7.
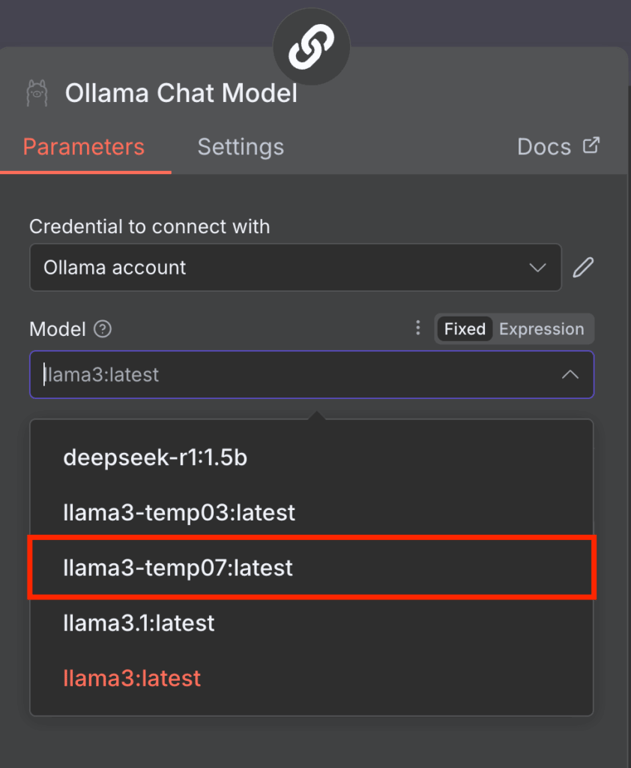
Gestion de Ollama GUI
Si vous utilisez Ollama GUI, consultez notre tutoriel pour en savoir plus sur son interface et sur la façon de gérer vos modèles.
3. Configurer les paramètres de prompt
La configuration des paramètres d’invite vous permet de personnaliser la manière dont le nœud Basic LLM Chain modifie votre entrée avant de la transmettre à Ollama pour traitement. Bien que vous puissiez utiliser les paramètres par défaut, vous devriez les modifier en fonction de vos tâches.
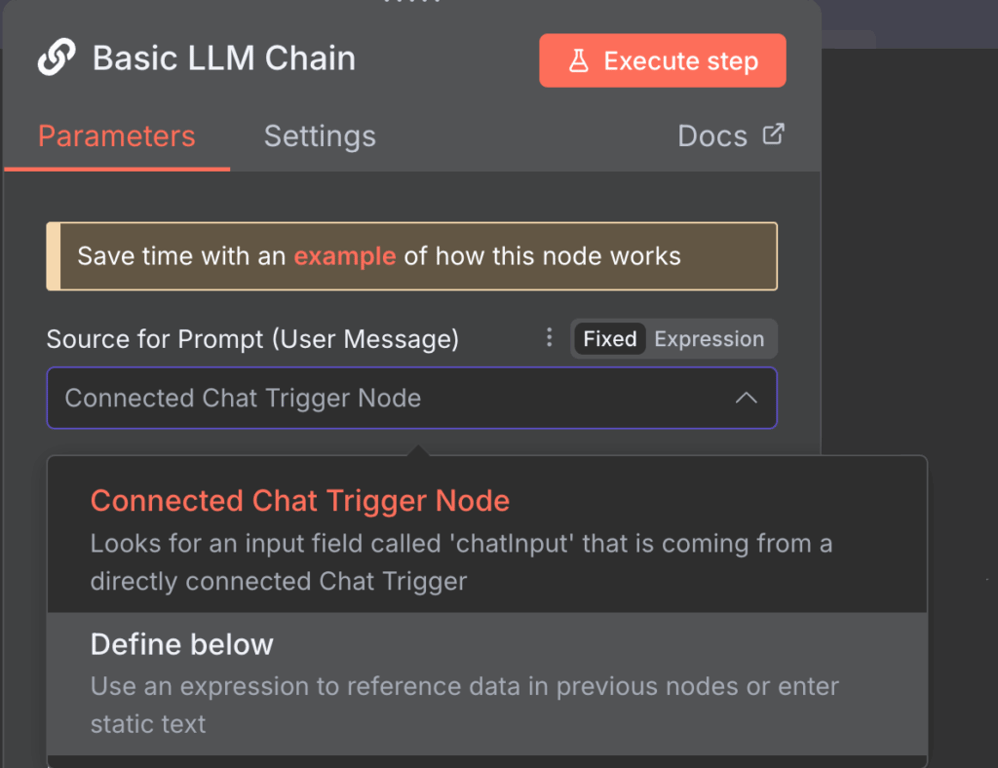
Voici deux façons de modifier les paramètres d’invite du nœud LLM chain et des exemples d’utilisation.
Nœud déclencheur Connected Chat
L’option Connected Chat trigger node utilise les messages du nœud Chat par défaut comme entrée pour Ollama. Il s’agit du mode sélectionné par défaut, qui transmet les messages tels quels.
Cependant, vous pouvez inclure des invites supplémentaires avec les messages afin de modifier la sortie d’Ollama. Pour ce faire, cliquez sur le bouton Add Prompt dans le paramètre Chat Messages (si vous utilisez un modèle de chat) et choisissez parmi trois options de prompt supplémentaires :
- IA. Entrez un exemple de réponse attendue dans le champ Message. Le modèle d’IA tentera de répondre de la même manière que le texte fourni.
- Système. Rédigez un message qui guide les réponses du modèle. Par exemple, vous pouvez définir le ton que l’IA utilisera ou les mots qu’elle doit éviter dans ses réponses.
- Utilisateur. Ajoutez un exemple de saisie utilisateur pour l’IA, tel qu’un message, une URL ou une image. En fournissant à l’IA un exemple de ce à quoi elle peut s’attendre de la part des utilisateurs, vous lui permettrez de renvoyer des réponses plus cohérentes.
Option Define below
L’option Define below est appropriée si vous souhaitez saisir une invite pré-saisie réutilisable. Elle est également idéale pour transférer des données dynamiques, car vous pouvez les capturer à l’aide d’Expressions, une bibliothèque JavaScript qui manipule les entrées ou sélectionne un champ spécifique.
Par exemple, le nœud précédent récupère des données sur l’utilisation de vos ressources VPS et vous souhaitez les analyser à l’aide de l’IA. Dans ce cas, l’invite reste la même, mais les mesures d’utilisation changent continuellement.
Votre invite pourrait ressembler à ce qui suit, {{ $json.metric }} étant le champ contenant les données dynamiques sur l’utilisation des ressources de votre serveur :
The latest usage of my server is {{ $json.metric }}. Analyze this data and compare it with the previous usage history to check if this is abnormal.Notez que vous pouvez toujours ajouter des invites supplémentaires comme dans le mode précédent pour donner plus de contexte à l’IA.
4. Envoyer une invite de test
L’envoi d’une invite de test permet de vérifier que votre modèle Ollama fonctionne correctement lorsqu’il reçoit des entrées via n8n. La façon la plus simple de le faire est de saisir un exemple de message en suivant ces étapes :
- Enregistrez votre flux de travail en cliquant sur le bouton en haut à droite de votre canevas.
- Passez la souris sur le nœud de déclenchement Chat et cliquez sur Open chat.
- Dans l’interface Chat, envoyez un message test.
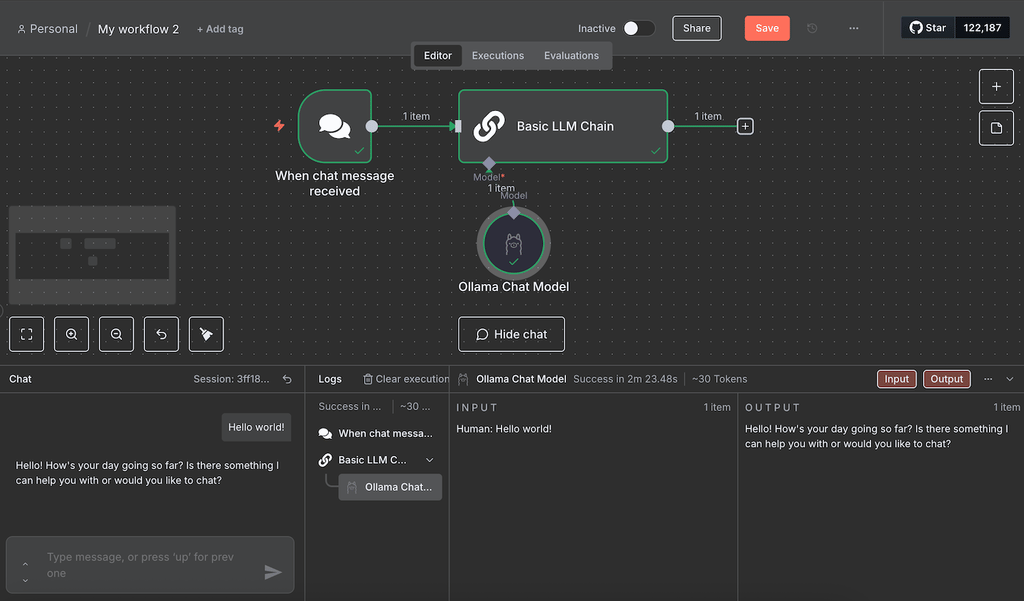
Attendez que le flux de travail ait fini de traiter votre message. Lors de nos tests, le flux de travail s’est bloqué à plusieurs reprises. Si vous rencontrez le même problème, rechargez simplement n8n et envoyez un nouveau message.
Si le test est réussi, tous les nœuds deviendront verts. Vous pouvez lire les entrées et sorties JSON de chaque nœud en double-cliquant dessus et en vérifiant les volets des deux côtés de la fenêtre de configuration.
Comment créer un workflow de chatbot à l’aide d’Ollama et de n8n
L’intégration d’Ollama dans n8n vous permet d’automatiser diverses tâches avec les LLM, notamment la création d’un workflow alimenté par l’IA qui répond aux requêtes des utilisateurs, comme un chatbot. Cette section explore les étapes nécessaires à son développement.
Si vous souhaitez créer un système d’automatisation pour d’autres tâches, consultez nos exemples de workflows n8n pour trouver l’inspiration.
1. Ajouter un nœud de déclenchement
Le nœud de déclenchement dans n8n définit l’événement qui lancera votre workflow. Parmi plusieurs options, voici les plus courantes pour créer un chatbot :
Déclencheur de chat
Par défaut, le nœud du modèle de chat Ollama utilise Chat message comme déclencheur, qui lance votre flux de travail dès réception d’un message.
Ce nœud Chat par défaut est parfait pour développer un chatbot. Pour le faire fonctionner, il vous suffit de rendre l’interface de chat accessible au public.
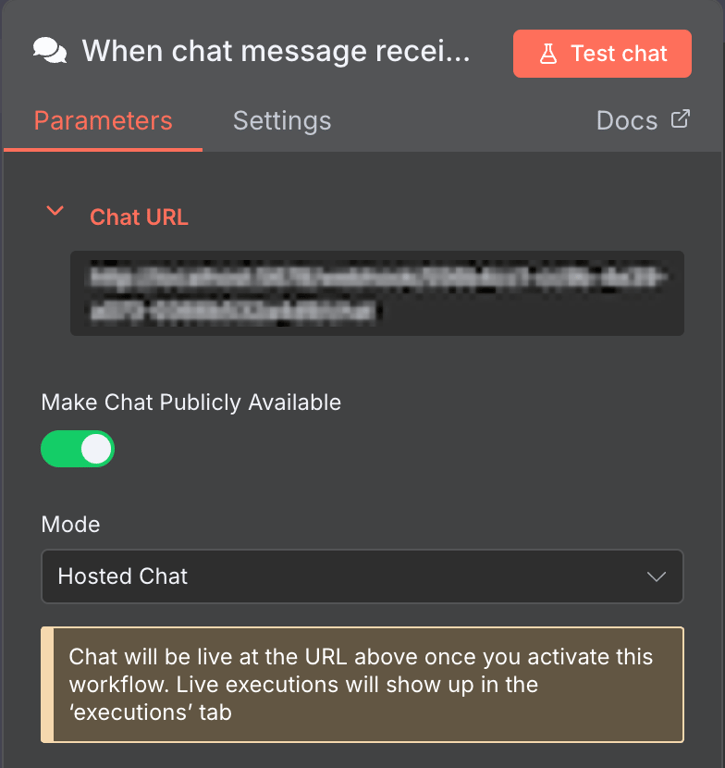
Pour ce faire, ouvrez le nœud Chat et cliquez sur le bouton Make Chat Publicly Available. Vous pouvez ensuite intégrer cette fonctionnalité de chat dans votre chatbot personnalisé avec une interface utilisateur.
Nœuds de déclenchement d’applications de messagerie
n8n dispose de nœuds de déclenchement qui acceptent les entrées provenant d’applications de messagerie populaires telles que Telegram et WhatsApp. Ils sont adaptés si vous souhaitez créer un bot pour ces applications.
La configuration de ces nœuds est assez délicate, car vous avez besoin d’un compte développeur et de clés d’authentification pour vous connecter à leurs API. Consultez leur documentation pour en savoir plus sur leur configuration.
Déclencheur Webhook
Le déclencheur Webhook lance votre flux de travail lorsque son URL de point de terminaison reçoit une requête HTTP. Il est adapté si vous souhaitez lancer votre chatbot à l’aide d’événements autres que l’envoi d’un message, comme un clic.
Dans les étapes ci-dessous, nous utiliserons ce nœud pour démarrer notre workflow chaque fois qu’un chatbot Discord reçoit un message.
Important ! Si votre URL webhook commence par localhost, remplacez-la par le nom de domaine, le nom d’hôte ou l’adresse IP de votre VPS. Pour ce faire, modifiez la variable d’environnement WEBHOOK_URL de n8n dans son fichier de configuration.
2. Connecter le nœud Ollama
La connexion du nœud Ollama permet au nœud de déclenchement de transférer les entrées utilisateur pour traitement.
Le nœud Ollama Chat Model ne se connecte pas directement aux nœuds de déclenchement et s’intègre uniquement à un nœud IA. Le nœud par défaut est le nœud Basic LLM Chain, mais vous pouvez également utiliser d’autres nœuds Chain pour un traitement plus complexe.
Certains nœuds Chain prennent en charge des outils supplémentaires pour le traitement de vos données. Par exemple, le nœud AI Agent vous permet d’ajouter un analyseur syntaxique pour reformater la sortie ou d’inclure une mémoire pour stocker les réponses précédentes.
Pour un chatbot qui ne nécessite pas de traitement de données complexe, comme notre chatbot Discord, la chaîne LLM de base suffit.
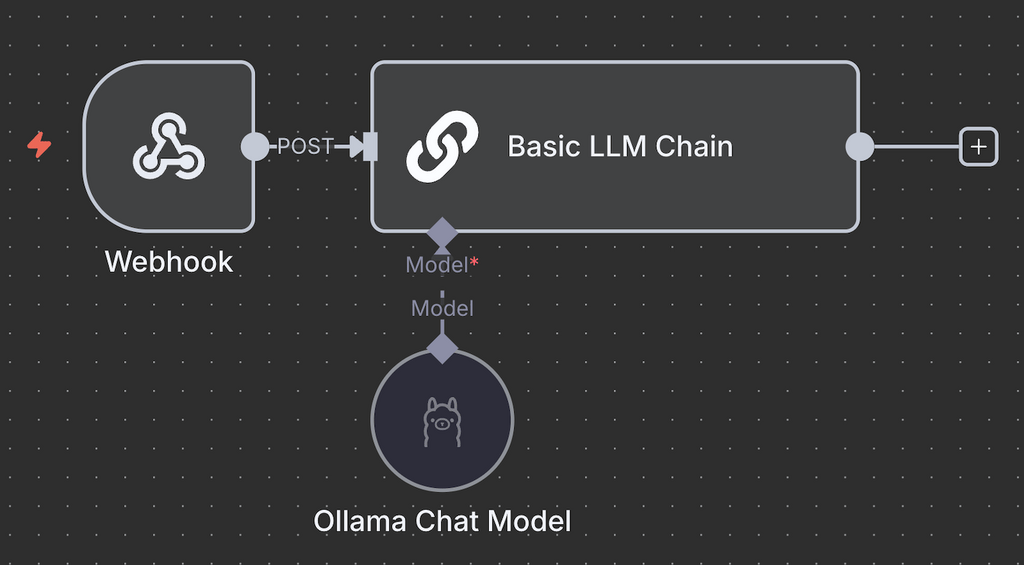
Connectez donc le nœud de déclenchement au nœud Basic LLM Chain et définissez comment transmettre l’entrée. Utilisez Fixed pour transmettre le message en tant qu’invite. Parallèlement, sélectionnez Expression pour utiliser des données dynamiques ou manipuler l’entrée avant de la transmettre à Ollama.
Par exemple, nous utilisons l’Expression suivante pour choisir le champ JSON body.content comme entrée, qui change en fonction des messages Discord des utilisateurs :
{{ $json.body.content }}3. Afficher la réponse
La sortie de la réponse à partir du nœud AI Agent ou Basic LLM Chain permet aux utilisateurs de voir la réponse de votre bot. À ce stade, vous ne pouvez lire la sortie qu’à partir de l’interface de chat ou du volet de sortie du nœud.
Pour envoyer la réponse, utilisez le même nœud que votre déclencheur. Par exemple, si vous développez un chatbot WhatsApp, connectez le nœud WhatsApp send message.
Si vous utilisez le déclencheur Chat par défaut, vous pouvez utiliser le nœud Webhook pour transférer le message vers votre bot personnalisé ou votre interface de chatbot.
Étant donné que le flux de travail de notre bot Discord utilise le déclencheur Webhook, nous pouvons également utiliser le nœud Webhook pour la sortie. Nous pouvons également utiliser le même bot pour envoyer la réponse en connectant le nœud Discord Send a Message et en l’intégrant à notre chatbot. Le flux de travail complet ressemblera à ceci :

Vous ne savez pas comment créer un workflow complet ?
n8n fournit divers workflows prêts à l'emploi que vous pouvez facilement importer dans votre canevas. Cela vous permet de créer un système d'automatisation alimenté par l'IA sans avoir à développer le workflow à partir de zéro.
Consultez notre tutoriel sur les meilleurs templates n8n pour découvrir des workflows sélectionnés et prêts à l'emploi pour divers usages.
Quels sont les meilleurs cas d’utilisation de l’intégration n8n Ollama ?
Étant l’un des outils d’automatisation IA les plus puissants, l’intégration de n8n avec les LLM personnalisables d’Ollama vous permet d’automatiser un large éventail de tâches.
Voici quelques exemples de tâches que vous pouvez automatiser avec n8n et l’intelligence artificielle :
- Workflow automatisé pour le service client. Utilisez les LLM d’Ollama pour générer des réponses aux demandes des clients, résumer les tickets ou acheminer les problèmes sur des plateformes telles que Zendesk et Intercom, le tout via n8n.
- Rédaction d’e-mails contextuels. Rédigez automatiquement des e-mails pour différents contextes ou tâches à l’aide d’Ollama. Par exemple, vous pouvez rédiger un message pour accueillir un nouveau prospect, rappeler aux clients l’expiration de leur abonnement et annoncer les mises à jour de produits à l’aide de différents événements.
- Assistant de base de connaissances interne. Utilisez n8n pour interroger la documentation interne, comme Notion, Confluence ou Airtable, et transmettez les données à Ollama pour générer des réponses ou des résumés intelligents aux questions de l’équipe interne.
- Extraction et synthèse de données. Utilisez n8n pour surveiller les documents texte entrants, extraire leur texte et extraire les informations clés avec Ollama, ce qui est utile pour résumer des rapports, des factures ou des documents juridiques.
- Pipeline de production de contenu automatisé. Générez du contenu à l’aide de n8n et Ollama en créant un flux de travail qui automatise la recherche de mots-clés, la rédaction et le processus d’édition.
- Chatbots sécurisés à usage interne. Créez des chatbots internes qui traitent des données internes sensibles, où n8n gère l’orchestration et Ollama exécute le LLM entièrement hors ligne pour des raisons de sécurité et de confidentialité.
Pourquoi héberger vos flux de travail n8n-Ollama avec Hostinger ?
L’hébergement de vos flux de travail n8n-Ollama avec Hostinger présente divers avantages par rapport à l’utilisation d’une machine personnelle ou du plan d’hébergement officiel. Voici quelques-uns de ces avantages :
- Contrôle accru. Le service d’hébergement VPS n8n de Hostinger offre aux utilisateurs un accès root complet aux paramètres et aux données de leur serveur. Cela vous permet de configurer vos environnements d’hébergement n8n et Ollama selon vos préférences spécifiques.
- Confidentialité améliorée. Comme vous hébergerez n8n et Ollama sur un serveur sur lequel vous avez un contrôle total, vous aurez la liberté d’ajuster les limites d’accès et les paramètres de sécurité.
- Évolutivité. Les plans VPS Hostinger sont facilement évolutifs sans temps d’arrêt et offrent le template de mode de file d’attente n8n qui vous permet de décharger votre tâche vers plusieurs travailleurs.
- Configuration simplifiée. Nos VPS templates vous permettent d’installer n8n ou Ollama en un seul clic, ce qui rend le processus plus efficace.
- Gestion facile. La gestion d’un VPS Hostinger est facile grâce au panneau de contrôle intuitif hPanel ou au terminal intégré au navigateur. Les débutants peuvent également demander à notre assistant IA, Kodee, d’effectuer des tâches d’administration système via le chat.

Utilisation du nœud LM Ollama de LangChain dans n8n
LangChain est un framework qui facilite l’intégration des LLM dans les applications. Dans n8n, cette implémentation implique la connexion de différents nœuds d’outils et modèles d’IA afin d’obtenir des capacités de traitement particulières.
Dans n8n, la fonctionnalité LangChain utilise des nœuds Cluster, un groupe de nœuds interconnectés qui fonctionnent ensemble pour fournir des fonctionnalités dans votre flux de travail.
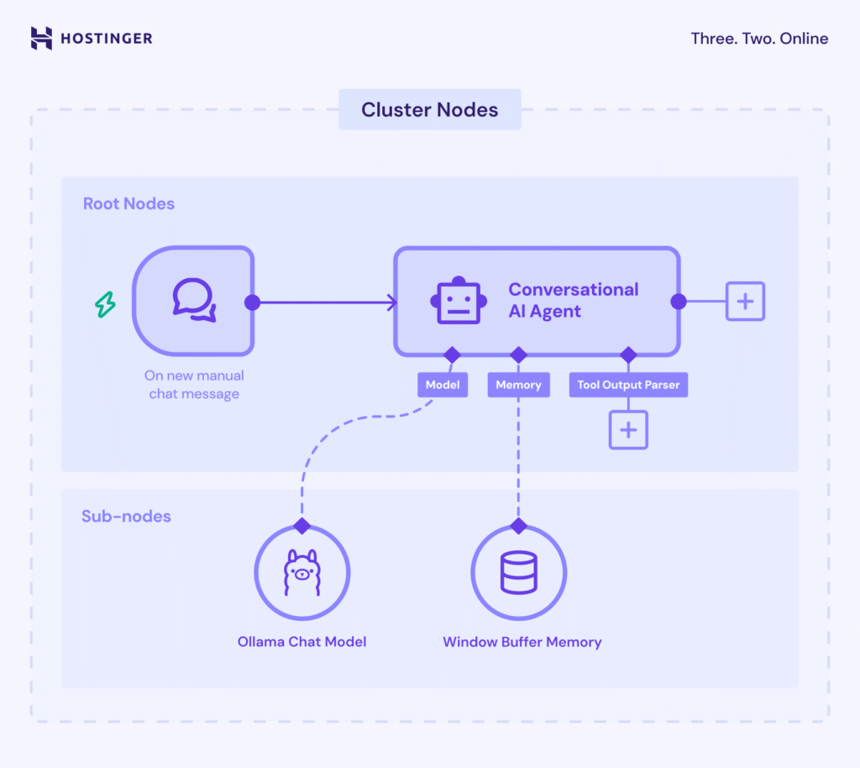
Les nœuds de cluster se composent de deux parties : les nœuds racines qui définissent la fonctionnalité principale et les sous-nœuds qui ajoutent la capacité LLM ou des fonctionnalités supplémentaires.
La partie la plus importante de l’implémentation de LangChain dans n8n est la chaîne à l’intérieur des nœuds racines. Elle rassemble et configure la logique de différents composants IA, tels que le modèle Ollama et le nœud analyseur, afin de créer un système cohérent.
Voici les chaînes dans n8n et leurs fonctions :
- Chaîne LLM de base. Vous permet de définir l’invite que le modèle d’IA utilisera et un analyseur syntaxique optionnel pour reformater la réponse.
- Chaîne de recherche Q&A. Vous permet de récupérer des données traitées par l’IA à l’aide de magasins de vecteurs, des bases de données conçues pour stocker des informations sous forme numérique.
- Chaîne de synthèse. Résume le contenu de plusieurs documents ou entrées.
- Analyse des sentiments. Analyse le sentiment du texte saisi et le classe dans des catégories telles que positif, neutre et négatif.
- Classificateur de texte. Trie les données d’entrée en différentes catégories créées par l’utilisateur en fonction des critères et paramètres spécifiés.
Lorsque vous créez un flux de travail dans n8n, vous pouvez également rencontrer des agents, qui sont des sous-ensembles de chaînes capables de prendre des décisions. Alors que les chaînes fonctionnent selon un ensemble de règles prédéterminées, un Agent utilise le LLM connecté pour déterminer les actions suivantes à entreprendre.
Quelle est la prochaine étape après avoir connecté n8n à Ollama ?
Alors que les tendances de l’automatisation continuent d’évoluer, la mise en œuvre d’un système de traitement automatique des données vous aidera à garder une longueur d’avance sur la concurrence. Associé à l’IA, vous pouvez créer un système qui fera passer le développement et la gestion de vos projets à un niveau supérieur.
L’intégration d’Ollama dans votre flux de travail n8n vous offre une automatisation basée sur l’IA qui va au-delà des capacités du nœud intégré. De plus, la compatibilité d’Ollama avec divers LLM vous permet de choisir et d’adapter différents modèles d’IA afin de répondre au mieux à vos besoins.
Comprendre comment connecter Ollama à n8n n’est que la première étape de la mise en œuvre de l’automatisation alimentée par l’IA dans votre projet. Étant donné le nombre impressionnant de cas d’utilisation possibles, l’étape suivante consiste à expérimenter et à développer un flux de travail qui correspond le mieux à votre projet.
Si vous utilisez n8n ou Ollama pour la première fois, Hostinger est le point de départ idéal. Outre nos plans VPS riches en fonctionnalités, nous proposons un catalogue complet de tutoriels sur n8n qui vous aideront à vous lancer dans l’automatisation.
Tout le contenu des tutoriels de ce site est soumis aux normes éditoriales et aux valeurs rigoureuses de Hostinger.

Chaimaa est spécialiste du référencement (SEO) et du marketing de contenu chez Hostinger. Passionnée par le marketing digital et la technologie, elle s’attache à créer des contenus utiles et accessibles pour aider chacun à résoudre ses problématiques et à réussir en ligne. En dehors du travail, Chaimaa est cinéphile, passionnée par l’analyse de films et la randonnée. Suivez-la sur LinkedIn.

Commentaires
0 responses