Tutoriel Ollama CLI : exécuter Ollama via le terminal
Mar 04, 2025
/
Chaimaa C.
/
8 minutes de lecture
En tant qu’outil puissant permettant d’exécuter localement de grands modèles de langage (LLM), Ollama offre aux développeurs, aux scientifiques des données et aux utilisateurs techniques un plus grand contrôle et une plus grande flexibilité dans la personnalisation des modèles.
Bien que vous puissiez utiliser Ollama avec des interfaces graphiques tierces comme Open WebUI pour des interactions plus simples, l’exécuter via l’interface de ligne de commande (CLI) vous permet de créer des modèles personnalisés basés sur des paramètres spécifiques et d’automatiser les flux de travail à l’aide de scripts.
Ce guide vous guidera dans l’utilisation d’Ollama via le CLI, depuis l’apprentissage des commandes de base et l’interaction avec les modèles jusqu’à l’automatisation des tâches et le déploiement de vos propres modèles. À la fin, vous serez en mesure d’adapter Ollama à vos projets basés sur l’IA.
Configuration d’Ollama dans le CLI
Avant d’utiliser Ollama dans le CLI, assurez-vous que vous avez bien l’installé sur votre système. Pour le vérifier, ouvrez votre terminal et exécutez la commande suivante :
ollama --version
Vous devriez obtenir un résultat similaire à celui-ci :

Ensuite, familiarisez-vous avec les commandes essentielles d’Ollama :
| Commande | Description |
ollama serve | Démarre Ollama sur votre système local. |
ollama create <new_model> | Crée un nouveau modèle à partir d’un modèle existant à des fins de personnalisation ou de formation. |
ollama show <model> | Affiche les détails d’un modèle spécifique, tels que sa configuration et sa date de sortie. |
ollama run <model> | Exécute le modèle spécifié, le rendant prêt pour l’interaction |
ollama pull <model> | Télécharge le modèle spécifié sur votre système. |
ollama list | Liste tous les modèles téléchargés. |
ollama ps | Affiche les modèles en cours d’exécution. |
ollama stop <model> | Arrête le modèle en cours d’exécution spécifié. |
ollama rm <model> | Supprime le modèle spécifié de votre système. |
Utilisation essentielle d’Ollama dans le CLI
Cette section couvre l’utilisation principale de l’interface de programmation d’Ollama, depuis l’interaction avec les modèles jusqu’à l’enregistrement des résultats du modèle dans des fichiers.
Exécution des modèles
Pour commencer à utiliser des modèles dans Ollama, vous devez d’abord télécharger le modèle souhaité à l’aide de la commande pull. Par exemple, pour télécharger Llama 3.2, exécutez la commande suivante :
ollama pull llama3.2
Attendez la fin du téléchargement, la durée peut varier en fonction de la taille du fichier du modèle.
Conseil de pro
Si vous ne savez pas quel modèle télécharger, consultez la bibliothèque de modèles officiels d'Ollama. Elle fournit des détails importants pour chaque modèle, notamment les options de personnalisation, la prise en charge des langues et les cas d'utilisation recommandés.
Après avoir extrait le modèle, vous pouvez l’exécuter à l’aide d’une invite prédéfinie comme celle-ci :
ollama run llama3.2 "Expliquez les bases de l'apprentissage automatique."
Voici le résultat attendu :

Vous pouvez également exécuter le modèle sans invite pour démarrer une session interactive :
ollama run llama3.2
Dans ce mode, vous pouvez saisir vos questions ou vos instructions, et le modèle générera des réponses. Vous pouvez également poser des questions complémentaires pour obtenir des informations plus approfondies ou clarifier une réponse précédente, par exemple :
Pouvez-vous expliquer comment l'apprentissage automatique est utilisé dans le secteur de la santé ?
Lorsque vous avez fini d’interagir avec le modèle, tapez :
/bye
Cette opération permet de quitter la session et de revenir à l’interface normale du terminal.
Lecture conseillée
Apprenez à créer des prompts IA efficaces pour améliorer vos résultats et vos interactions avec les modèles Ollama.
Modèles de formation
Si les modèles open-source pré-entraînés tels que Llama 3.2 sont performants pour des tâches générales comme la génération de contenu, ils ne répondent pas toujours aux besoins des cas d’utilisation spécifiques. Pour améliorer la précision d’un modèle sur un sujet particulier, vous devez l’entraîner à l’aide de données pertinentes.
Notez toutefois que ces modèles ont une mémoire à court terme limitée, ce qui signifie que les données d’entraînement ne sont conservées que pendant la conversation en cours. Lorsque vous quittez la session et en démarrez une nouvelle, le modèle ne se souvient pas des informations avec lesquelles vous l’avez formé précédemment.
Pour entraîner le modèle, démarrez une session interactive. Ensuite, lancez la formation en saisissant une invite telle que :
Salut, je veux que tu apprennes [sujet]. Puis-je t'entraîner sur cela ?
Le modèle répondra par quelque chose comme :

Vous pouvez ensuite fournir des informations de base sur le sujet pour aider le modèle à comprendre :

Pour poursuivre la formation et fournir plus d’informations, demandez au modèle de vous poser des questions sur le sujet. Par exemple :
Peux-tu me poser quelques questions sur [sujet] pour t'aider à mieux le comprendre ?
Une fois que le modèle dispose d’un contexte suffisant sur le sujet, vous pouvez mettre fin à la formation et tester si le modèle retient ces connaissances.

Prompting et enregistrement des réponses dans des fichiers
Dans Ollama, vous pouvez demander au modèle d’effectuer des tâches à partir du contenu d’un fichier, comme résumer un texte ou analyser des informations. Cette fonction est particulièrement utile pour les documents longs, car elle évite de devoir copier et coller du texte pour donner des instructions au modèle.
Par exemple, si vous disposez d’un fichier nommé input.txt contenant les informations que vous souhaitez résumer, vous pouvez exécuter la commande suivante :
ollama run llama3.2 "Résume le contenu de ce fichier en 50 mots." < input.txt
Le modèle lit le contenu du fichier et génère un résumé :

Ollama vous permet également d’enregistrer les réponses du modèle dans un fichier, ce qui facilite leur examen ou leur affinement ultérieur. Voici un exemple de question posée au modèle et d’enregistrement de la réponse dans un fichier :
ollama run llama3.2 "Parle-moi de l'énergie renouvelable."> output.txt
Cette opération permet d’enregistrer la réponse du modèle dans le fichier output.txt :

Utilisation avancée d’Ollama dans le CLI
Maintenant que vous avez compris l’essentiel, explorons des utilisations plus avancées d’Ollama à travers le CLI.
Création de modèles personnalisés
L’un des principaux avantages de l’exécution d’Ollama via l’interface de programmation est la possibilité de créer un modèle personnalisé en fonction de vos besoins spécifiques.
Pour ce faire, créez un fichier de modèle, qui constitue le plan de votre modèle personnalisé. Le fichier définit des paramètres clés tels que le modèle de base, les paramètres à ajuster et la manière dont le modèle répondra aux invites.
Suivez les étapes suivantes pour créer un modèle personnalisé dans Ollama :
1. Créer un nouveau Modelfile
Utilisez un éditeur de texte comme nano pour créer un nouveau Modelfile. Dans cet exemple, nous nommerons le fichier custom-modelfile :
nano custom-modelfile
Ensuite, copiez et collez ce modèle de base de Modelfile, que vous personnaliserez à l’étape suivante :
# Use Llama 3.2 as the base model
FROM llama3.2
# Adjust model parameters
PARAMETER temperature 0.7
PARAMETER num_ctx 3072
PARAMETER stop "assistant:"
# Define model behavior
SYSTEM "You are an expert in cyber security."
# Customize the conversation template
TEMPLATE """{{ if .System }}Advisor: {{ .System }}{{ end }}
Client: {{ .Prompt }}
Advisor: {{ .Response }}"""2. Personnaliser le Modelfile
Voici les principaux éléments que vous pouvez personnaliser dans le fichier modèle :
- Modèle de base (FROM). Définit le modèle de base pour votre instance personnalisée. Vous pouvez choisir parmi les modèles disponibles tels que Llama 3.2 :
FROM llama3.2
- Paramètres (PARAMETER). Ils contrôlent le comportement du modèle, par exemple :
- Temperature. Ajuste la créativité du modèle. Des valeurs élevées comme 1,0 le rendent plus créatif, tandis que des valeurs plus faibles comme 0,5 le rendent plus concentré.
PARAMETER temperature 0.9
- Fenêtre de contexte (num_ctx). Définit la quantité de texte précédent que le modèle utilise comme contexte.
PARAMETER num_ctx 4096
- Message du système (SYSTEM). Définit la manière dont le modèle doit se comporter. Par exemple, vous pouvez lui demander de se comporter comme un personnage spécifique ou d’éviter de répondre à des questions non pertinentes :
SYSTEM “You are an expert in cyber security. Only answer questions related to cyber security. If asked anything unrelated, respond with: ‘I only answer questions related to cyber security.’"
- Modèle (TEMPLATE). Personnaliser la façon de structurer l’interaction entre l’utilisateur et le modèle. Par exemple :
TEMPLATE """{{ if .System }}<|start|>system
{{ .System }}<|end|>{{ end }}
<|start|>user
{{ .Prompt }}<|end|>
<|start|>assistant
"""Après avoir effectué les ajustements nécessaires, enregistrez le fichier et quittez nano en appuyant sur Ctrl + X → Y → Entrée.
3. Créer et exécuter le modèle personnalisé
Une fois que votre fichier modèle est prêt, utilisez la commande ci-dessous pour créer un modèle basé sur le fichier :
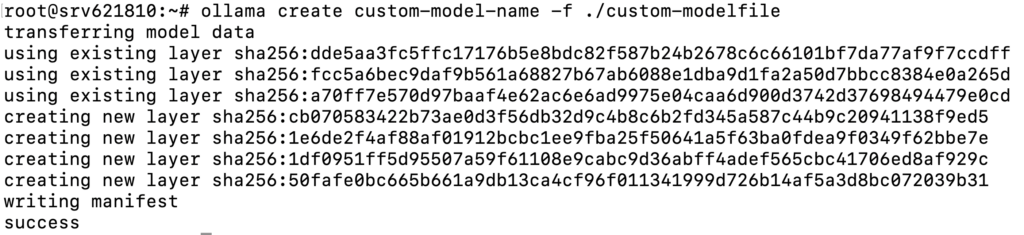
ollama create custom-model-name -f ./custom-modelfile
Vous devriez voir une sortie indiquant que le modèle a été créé avec succès :
Ensuite, il faut le faire fonctionner comme n’importe quel autre modèle :
ollama run custom-model-name
Le modèle démarre alors avec les personnalisations que vous avez appliquées, et vous pouvez interagir avec lui :

Vous pouvez continuellement améliorer et affiner le fichier de modèle en ajustant les paramètres, en modifiant les messages du système, en ajoutant des modèles plus avancés ou même en incluant vos propres ensembles de données. Enregistrez les modifications et relancez le modèle pour en voir les effets.
Automatisation des tâches avec des scripts
L’automatisation des tâches répétitives dans Ollama permet de gagner du temps et d’assurer la cohérence du flux de travail. En utilisant des scripts bash, vous pouvez exécuter des commandes automatiquement. Par ailleurs, avec les jobs cron, vous pouvez planifier des tâches à exécuter à des heures spécifiques. Voici comment commencer :
Créer et exécuter des scripts bash
Vous pouvez créer un script bash qui exécute les commandes Ollama. Voici comment procéder :
- Ouvrez un éditeur de texte et créez un nouveau fichier nommé ollama-script.sh :
nano ollama-script.sh
- Ajouter les commandes Ollama nécessaires dans le script. Par exemple, pour exécuter un modèle et enregistrer la sortie dans un fichier :
#!/bin/bash # Run the model and save the output to a file ollama run llama3.2 "What are the latest trends in AI?" > ai-output.txt
- Rendez le script exécutable en lui donnant les permissions correctes :
chmod +x ollama-script.sh
- Exécutez le script directement à partir du terminal :
./ollama-script.sh
Mettre en place des jobs cron pour automatiser les tâches
Vous pouvez combiner votre script avec un job cron pour automatiser des tâches telles que l’exécution régulière de modèles. Voici comment configurer un job cron pour exécuter automatiquement les scripts Ollama :
- Ouvrez l’éditeur crontab en tapant :
crontab -e
- Ajoutez une ligne spécifiant l’horaire et le script que vous souhaitez exécuter. Par exemple, pour exécuter le script tous les dimanches à minuit :
0 0 * * 0 /path/to/ollama-script.sh
- Sauvegardez et quittez l’éditeur après avoir ajouté la tâche cron.
Cas d’utilisation courants pour le CLI
Voici quelques exemples concrets d’utilisation de la CLI d’Ollama.
Génération de texte
Vous pouvez utiliser des modèles préformés pour créer des résumés, générer du contenu ou répondre à des questions spécifiques.
- Résumer un grand fichier texte :
ollama run llama3.2 "Résumez le texte suivant:" < long-document.txt
- Générer du contenu tel que des articles de blog ou des descriptions de produits :
ollama run llama3.2 "Rédigez un court article sur les avantages de l'utilisation de l'IA dans le domaine de la santé."> article.txt
- Répondre à des questions spécifiques pour faciliter la recherche :
ollama run llama3.2 "Quelles sont les dernières tendances en IA et comment vont-elles affecter le secteur de la santé ?"
Traitement, analyse et prévision des données
Ollama vous permet également de traiter des tâches de traitement de données telles que la classification de textes, l’analyse de sentiments et la prédiction.
- Classification des textes en sentiments positifs, négatifs ou neutres :
ollama run llama3.2 "Analyse le sentiment de cet avis client : 'Le produit est fantastique, mais la livraison a été lente'"
- Classer le texte dans des catégories prédéfinies :
ollama run llama3.2 "Classer ce texte dans les catégories suivantes : Nouvelles, Opinion ou Revue." < textfile.txt
- Prédire un résultat sur la base des données fournies :
ollama run llama3.2 "Prédire la tendance du prix de l'action pour le mois prochain en se basant sur les données suivantes :" < stock-data.txt
Intégration avec des outils externes
Une autre utilisation courante de l’interface de programmation d’Ollama consiste à la combiner avec des outils externes pour automatiser le traitement des données et étendre les capacités d’autres programmes.
- Intégrer Ollama avec une API tierce pour récupérer les données, les traiter et générer des résultats :
curl -X GET "https://api.example.com/data" | ollama run llama3.2 "Analysez les données API suivantes et résumez les informations clés."
- Utiliser du code Python pour exécuter un sous-processus avec Ollama :
import subprocess result = subprocess.run(['ollama', 'run', 'llama3.2', 'Donne-moi les dernières tendances du marché boursier'], capture_output=True) print(result.stdout.decode())

Conclusion
Dans cet article, vous avez appris les bases de l’utilisation d’Ollama via le CLI, y compris l’exécution de commandes, l’interaction avec les modèles et l’enregistrement des réponses des modèles dans des fichiers.
L’interface en ligne de commande permet également d’effectuer des tâches plus avancées, telles que la création de nouveaux modèles basés sur des modèles existants, l’automatisation de flux de travail complexes à l’aide de scripts et de tâches cron, et l’intégration d’Ollama avec des outils externes.
Nous vous encourageons à explorer les fonctionnalités de personnalisation d’Ollama afin de libérer tout son potentiel et d’améliorer vos projets d’IA. Si vous avez des questions ou si vous souhaitez partager votre expérience de l’utilisation d’Ollama dans le CLI, n’hésitez pas à utiliser la boîte de commentaires ci-dessous.
Tutoriel Ollama CLI – FAQ
Que puis-je faire avec la version CLI d’Ollama ?
Avec la version CLI d’Ollama, vous pouvez exécuter des modèles, générer du texte, effectuer des tâches de traitement de données comme l’analyse des sentiments, automatiser des flux de travail avec des scripts, créer des modèles personnalisés et intégrer Ollama avec des outils externes ou des API pour des applications avancées.
Comment installer des modèles pour Ollama dans le CLI ?
Pour installer des modèles via le CLI, assurez-vous d’abord que vous avez téléchargé Ollama sur votre système d’exploitation. Ensuite, utilisez la commande ollama pull suivie du nom du modèle. Par exemple, pour installer Llama 3.2, exécutez ollama pull llama3.2.
Puis-je utiliser des modèles multimodaux dans la version CLI ?
Bien qu’il soit techniquement possible d’utiliser des modèles multimodaux comme LlaVa dans le CLI d’Ollama, ce n’est pas pratique car le CLI est optimisé pour les tâches textuelles. Nous suggérons à d’utiliser Ollama avec des outils d’interface graphique pour gérer les tâches visuelles.
Tout le contenu des tutoriels de ce site est soumis aux normes éditoriales et aux valeurs rigoureuses de Hostinger.

Chaimaa est spécialiste du référencement (SEO) et du marketing de contenu chez Hostinger. Passionnée par le marketing digital et la technologie, elle s’attache à créer des contenus utiles et accessibles pour aider chacun à résoudre ses problématiques et à réussir en ligne. En dehors du travail, Chaimaa est cinéphile, passionnée par l’analyse de films et la randonnée. Suivez-la sur LinkedIn.


Commentaires
0 responses