Hermes Agent: Kosten und Aufschlüsselung 2026
Jun 17, 2026
/
Vera P.
/
8 Min. Lesezeit
Die Nutzung von Hermes Agent kostet zwischen 5 € und 80 € pro Monat, je nachdem, welches Sprachmodell Sie für die Argumentation verwenden.
Die Software ist unter der MIT-Lizenz kostenlos, daher ergeben sich Kosten aus zwei Quellen: dem VPS-Hosting für den Agent-Prozess und den LLM-API-Aufrufen für jeden einzelnen Argumentations-Schritt.
Die vollständige Rechnung gliedert sich in vier Teile:
- VPS-Hosting: 4 € bis 25 € pro Monat für den Server, auf dem der Agent-Prozess läuft.
- LLM-API-Aufrufe: 2 € bis 60 € pro Monat, abhängig davon, welches Modell das Reasoning übernimmt.
- Optionale Nous-Portal-Mitgliedschaft: 0 € für die kostenlose Stufe oder 20 € pro Monat für die Plus-Stufe mit enthaltenen Tools.
- Optionale Tool-Services: Websuche, Bilderzeugung, Browser-Automatisierung und Text-zu-Sprache-Funktion, sofern diese nicht im Paket enthalten sind.
Im Vergleich zu ChatGPT Plus mit 20 € pro Monat oder Claude Pro mit 17 € pro Monat kostet eine kostengünstige Hermes-Konfiguration weniger als die Hälfte. Eine Premium-Konfiguration kostet das Zwei- bis Vierfache, ist dafür aber nicht durch Nutzungslimits begrenzt.
Ob sich die Konfiguration lohnt, hängt von der Nutzung ab. Ab einigen Hundert Agent-Sitzungen pro Monat und mehr wird das Preis-Leistungs-Verhältnis günstiger. Unterhalb dieser Schwelle ist ein Pauschalabonnement für Privatkunden günstiger und unkomplizierter.
VPS-Hosting
VPS-Hosting ist die feste monatliche Gebühr für den Server, auf dem Hermes Agent läuft. Der Agent-Prozess ist ressourcenschonend, daher reicht in der Regel eine Instanz mit 1 GB RAM und 1 vCPU für die meisten Cloud-LLM-Setups aus.
Hinweise zur Größenbestimmung nach Workload:
- Mindestens 1 GB RAM und 1 vCPU reichen aus, wenn ein Cloud-LLM das Reasoning übernimmt.
- Browser-Automatisierung. 2 bis 4 GB RAM.
- Lokales Ollama, 7B bis 13B. Mindestens 4 GB RAM.
- Lokale 70B-Modelle. Serverloses GPU-Modell mit sekundengenauer Abrechnung, etwa 40 € bis 80 € pro Monat bei geringer Nutzung. Eine ständig laufende Instanz ist deutlich teurer.
Zu den gängigen Anbietern gehören Hostinger ab €5.49/Monat, Hetzner, DigitalOcean sowie serverlose Optionen wie Modal, die im Leerlauf in den Ruhezustand wechseln. Die meisten Setups kosten 4 € bis 25 € pro Monat.
Hostinger-VPS mit 1-Klick-Docker-Einrichtung deckt den RAM-Bereich von 1-4 GB ab, den Hermes Agent für leichtgewichtige Setups und Browser-Automatisierung benötigt.
Eine typische Budgetfalle besteht darin, dass die Einstiegspreise für VPS nicht von Dauer sind. Die Verlängerungspreise sind in der Regel höher als die Aktionspreise. Planen Sie Ihr Budget daher auf Basis des Verlängerungspreises und nicht des Einführungspreises. Ein Tarif, der bei 4 € pro Monat beginnt, kann bei Verlängerun 10-12 € pro Monat kosten.
Stundenhonorare sind eine weitere Falle. Eine Instanz mit 0,24 € pro Stunde kostet etwa 173 € pro Monat, wenn sie dauerhaft läuft. Für dauerhaft laufende Hermes-Bereitstellungen ist eine feste monatliche Preisgestaltung vorteilhafter als eine Abrechnung nach Stunden.

LLM-API-Aufrufe (Inference)
LLM-API-Aufrufe sind die variablen Kosten für jede Modellanfrage, die der Hermes Agent stellt. Die Abrechnung der Anbieter erfolgt in Dollar pro einer Million Eingabe- und Ausgabe-Token, und die Reasoning-Schleife des Agenten kann in einer einzigen Sitzung Dutzende von Anfragen senden.
Anbieter berechnen getrennte Gebühren für die Tokens, die Sie senden (Input), und für die Tokens, die das Modell als Antwort erzeugt (Output). Hier sind die voraussichtlichen Preisstufen Mitte 2026:
- Budget. DeepSeek V4 Flash kostet 0,14 USD pro einer Million gesendeter Tokens und 0,28 USD pro einer Million generierter Tokens. GPT-5.4 Nano kostet 0,20 USD für gesendete Tokens und 1,25 USD für generierte Tokens. Gemini 3.1 Flash-Lite kostet 0,25 USD pro gesendeter und 1,50 USD pro generierter Einheit.
- Mittelklasse. Claude Haiku 4.5 kostet 1,00 USD für gesendete Tokens bzw. 5,00 USD für generierte Tokens je eine Million Tokens.
- Premium. Claude Sonnet 4.6 kostet 3,00 USD gesendet / 15,00 USD generiert. Claude Opus 4.8 kostet 5,00 USD für gesendete Tokens und 25,00 USD für generierte Tokens pro einer Million Tokens.
- Aggregator. OpenRouter stellt Ihnen über einen einzigen API-Schlüssel Zugriff auf mehr als 300 Modelle mit einem geringen Aufschlag bereit.
Zwei Mechanismen beeinflussen die Rechnung über den reinen Listenpreis hinaus. Das erste ist die Bepreisung bei Cache-Treffern. Beispielsweise berechnet DeepSeek V4 Flash pro einer Million Eingabetoken 0,14 USD bei Cache-Misses und 0,0028 USD bei Cache-Hits – ein Rabatt von 98 %.
Die Cache-Preise sind für Hermes wichtiger als für Chatbots, weil der Agent bei jeder Anfrage eine feste Datenlast mit Tool-Definitionen erneut sendet. Das bedeutet, dass sich der Rabatt im Verlauf einer Sitzung aufaddiert.
Der zweite Mechanismus ist der Kompressionszusammenfasser. Wenn ein Gespräch den standardmäßigen Kontextschwellenwert von 50 % überschreitet, sendet Hermes einen separaten LLM-Aufruf, um den Verlauf zu komprimieren, was zusätzliche Tokens auf der Rechnung verursacht.
Wie Sie mit dem Agenten sprechen, wirkt sich ebenfalls auf die Rechnung aus. Hermes sendet bei jeder Anfrage 6.000 bis 8.000 Token an Tool-Definitionen über die CLI und 15.000 bis 20.000 Token über Messaging-Gateways wie Telegram oder Discord.
Der Wechsel von einem Gateway zur CLI verringert den Overhead pro Anfrage um das Zwei- bis Dreifache.
In einer kostengünstigen Umgebung mit DeepSeek V4 Flash kostet ein intensiver Tag mit mehrstufigem Agenten-Einsatz nur wenige Euro an Tokens. Die gleiche Arbeitslast kostet mit Claude Opus 4.8 ungefähr das 30‑Fache, da Opus 5 USD/25 USD pro einer Million Token berechnet, verglichen mit 0,14 USD/0,28 USD bei Flash.
Nous-Portal-Abonnement (optional)

Nous Portal ist ein optionales Abonnement von Nous Research. Kostenpflichtige Tarife bündeln über 300 Modelle und vier zentrale Tools – Websuche, Bildgenerierung, Text-zu-Sprache und Browser-Automatisierung – in einer einzigen Rechnung.
Es wurde am 27. April 2026 gestartet und wird über ein einziges OAuth-Setup mit hermes setup –portal verbunden. Die aktuellen Stufen sind:
- Kostenlos. 0 € pro Monat, mit nutzungsbasierten Credits ab ca. 10 USD die eins zu eins umgerechnet werden. 10 USD entsprechen 10 USD Nutzung. Das reicht für eine schnelle Einschätzung, aber nicht für echte Arbeitslasten.
- Plus. 20 USD pro Monat, mit 22 USD monatlichem Nutzungsguthaben.
- Super. 100 USD pro Monat, mit 110 USD monatlichem Nutzungsguthaben.
- Ultra. Ca. 200 USD pro Monat, mit 220 USD monatlichem Nutzungsguthaben und den höchsten Ratenlimits aller Tarife.
Jeder kostenpflichtige Tarif umfasst in jedem Abrechnungszeitraum das angegebene monatliche Guthaben. Die kostenlose Stufe ist die Ausnahme: Sie enthält kein gebündeltes Guthaben und umfasst das Tool Gateway nicht, daher eignet sie sich eher für eine kurze Evaluierung als für eine dauerhafte Nutzung.
Wenn Sie bereits separat für Websuche, Bildgenerierung und Browserautomatisierung bezahlen, ist die Plus-Stufe für 20 USD in der Regel günstiger, als jedes Tool einzeln zu beziehen. Das Nous-Portal ist nicht erforderlich: OpenRouter, direkte Anthropic- oder OpenAI-API-Schlüssel und das lokale Ollama funktionieren alle auch ohne das Portal.
Tooldienste (optional)
Tooldienste sind externe APIs, die der Hermes-Agent aufruft, wenn er im Web recherchiert, einen Browser ausführt, Bilder erzeugt oder Text in Sprache umwandelt. Wenn Sie sie nicht über das Nous-Portal leiten, berechnet jeder Dienst seine eigene nutzungsabhängige Gebühr.
Typische Anbieter nach Kategorie sind:
- Websuche. Firecrawl, Tavily, Exa.
- Browser-Automatisierung. Browser-Nutzung.
- Bildgenerierung. FAL.
- Text-zu-Sprache. ElevenLabs, OpenAI-Audio.
- Sandbox für Codeausführung. Modalfenster.
Bei gelegentlicher Nutzung erhöhen diese Dienste die monatlichen Kosten nur um wenige Euro. Intensivere Tool-Nutzung ist der Punkt, an dem sich das enthaltene Nous-Portal-Plus-Paket auszuzahlen beginnt.
Browser-Automatisierung beansprucht von allen Tools die meiste CPU-Leistung und erfordert häufig ein Upgrade über einen VPS-Tarif mit 1 GB RAM hinaus.
Lokaler Hardwarepfad (alternativ)
Der lokale Hardwarepfad erspart Ihnen die monatlichen Datenverarbeitungskosten, er setzt jedoch voraus, dass Sie die Hardware besitzen und eine geringere Qualität beim Reasoning in Kauf nehmen. Der Hermes-Agent kommuniziert über die standardisierte, OpenAI-kompatible API mit einem lokal ausgeführten Modell.
Hardwareanforderungen nach Modellgröße:
- Modelle mit 7B bis 13B Parametern. Mindestens 4 GB RAM oder 6 bis 8 GB VRAM für GPU-Beschleunigung.
- 27B-Modelle. Apple Silicon mit einheitlichem Speicher. Ein M3 Pro mit 36 GB kann zum Beispiel ein 27B-Modell mit einem Kontext von 64K verarbeiten.
- 70B-Modelle. Serverlose Cloud-GPU mit sekundengenauer Abrechnung, etwa 40 € bis 80 € pro Monat bei geringer Nutzung. Eine dauerhaft laufende Instanz kostet deutlich mehr.
Sinnvolle Ausgangspunkte sind Qwen 3 8B für ein gutes Preis-Leistungs-Verhältnis und Llama 4 Maverick für stärkeres Schlussfolgern.
Die meisten Entwickler-Laptops können Qwen 3 8B ausführen. Der Komprimierungsschritt von Hermes Agent benötigt ein zusätzliches Modell mit einem Kontextfenster von mindestens 64K, daher können Sie eine Standardkonfiguration von Ollama mit 4K nicht unverändert wiederverwenden.
Lokale Modelle bleiben bei komplexem, mehrstufigem Denken hinter Claude Sonnet zurück. Sie bewältigen Routineaufgaben gut, aber nicht solche, bei denen eine einzige falsche Schlussfolgerung eine ganze Ausführung zum Scheitern bringen kann.
So senken Sie die Hermes Agent-Kosten
Der schnellste Weg, Hermes-Agent-Kosten zu senken, besteht darin, Ihre Einstellungen zu überprüfen – nicht darin, das Modell zu wechseln. Durch das Anpassen der Tools, des Komprimierungsmodells und der Ausgabenobergrenzen für Anbieter lassen sich die Kosten senken, ohne dass Sie Ihr primäres LLM ändern müssen.
Die Standardeinstellungen des Agents gehen davon aus, dass Sie alle Tools aktivieren und Unterhaltungen möglichst stark zusammenfassen möchten. Diese Standardeinstellungen können Ihre Kosten erhöhen.
Vier Taktiken, nach Wirkung geordnet:
- Zu einem Cache-freundlichen Modell wechseln. DeepSeek V4 Flash bietet einen Preisnachlass von 98 % auf Cache-Treffer, der sich über lange Agentensitzungen hinweg kumuliert. Bei stark cache-lastigen Workloads können dieselben Aufgaben nur halb so viel oder sogar noch weniger kosten als auf Claude Opus.
- Nicht verwendete Tools entfernen. Der Wechsel von einem Messaging-Gateway zur CLI reduziert den Token-Overhead pro Anfrage um den Faktor 2 bis 3. Wenn Sie nicht benötigte Tools deaktivieren, sinkt er noch weiter.
- Ein günstigeres Komprimierungsmodell verwenden. Hermes sendet eine separate Zusammenfassungsanforderung, sobald eine Unterhaltung den standardmäßigen Kontextschwellenwert von 50 % überschreitet. Wenn Sie diese Anfrage an ein günstiges Modell wie DeepSeek V4 Flash oder GPT-5.4 Nano richten, senkt das einen versteckten Kostenfaktor.
- Ausgabengrenzen für Anbieter festlegen. OpenRouter, Anthropic und OpenAI bieten alle feste monatliche Ausgabenlimits an. Legen Sie eines leicht oberhalb Ihres Zielbudgets fest, um zu verhindern, dass eine aus dem Ruder laufende Agent-Schleife unerwartete Kosten verursacht.
Die beiden häufigsten unerwarteten Kosten bei der Abrechnung sind der Aufschlag durch die Tool-Definition und der Komprimierungs-Summarizer. Wenn Ihre Rechnung unerwartet stark ansteigt, überprüfen Sie zuerst die Wahl Ihres Gateways.
Vom Telegram-Client zur CLI zu wechseln, ist oft die schnellste Lösung. Prüfen Sie anschließend, ob Ihr primäres Modell Cache-Preise unterstützt. Der Wechsel zu DeepSeek V4 Flash kann eine stark Claude-lastige Rechnung bei cacheintensiven Workloads um 50 % oder mehr senken.
Hermes-Agent-Kosten im Vergleich zu ChatGPT Plus, Claude Pro und OpenClaw Cloud
Im Vergleich zu einfachen Verbrauchertarifen verursacht eine günstige Hermes-Konfiguration geringere Kosten, während eine Premium-Konfiguration eine höhere Monatsrechnung gegen unbegrenzte Nutzung eintauscht. Die folgende Tabelle vergleicht die typischen monatlichen Kosten für einen einzelnen Entwickler auf Basis der öffentlichen Preise vom Juni 2026.
Plan | Monatliche Kosten | Kostenart | Am besten geeignet für |
Hermes Agent (Budget) | 5-8 USD | Variabel (Hosting + Tokens) | Allein arbeitende Entwickler mit geringer Auslastung |
Hermes Agent (Premium) | 40-80 USD | Variabel | Workflows mit Frontier-Modellen ohne Nutzungslimits |
ChatGPT Plus | 20 USD | Pauschalabonnement | Einzelbenutzer-Chat mit begrenzter Nutzung |
Claude Pro | 17 USD | Pauschalabonnement | Anthropic-Nutzer mit begrenzter Nutzung |
OpenClaw Cloud | 59 USD | Pauschaler Managed Service | Teams, die eine vorhersehbare Agenteninfrastruktur wünschen |
Wählen Sie Hermes Agent, wenn Sie die volle Kontrolle wünschen und Ihr Arbeitsvolumen unter 1 Million Tokens pro Tag bleibt. Wählen Sie ein Pauschalabonnement, wenn Sie eine gut planbare monatliche Rechnung bevorzugen und keine autonomen Agent-Workflows benötigen.
OpenClaw Cloud ist in diesem Vergleich die einzige verwaltete Alternative. Die Unterschiede zwischen Hermes Agent und OpenClaw ergeben sich aus dem Bereitstellungsmodell und den Gesamtkosten.
Ist Hermes Agent günstiger als ChatGPT Plus?
Das hängt von dem Modell ab, das Sie verwenden. Eine kostengünstige Hermes-Agent-Konfiguration auf Hetzner mit DeepSeek V4 Flash beginnt bei etwa 5 € pro Monat und liegt damit deutlich unter ChatGPT Plus mit 20 € pro Monat. Ein Premium-Setup mit Claude Sonnet 4.6 ist teurer.
Der Break-even-Punkt hängt von zwei Faktoren ab. Die Nutzung von Tokens bestimmt, ab wann ein Premium-Setup teurer wird als das pauschale Abo für ca. 20 €, während das Sitzungsvolumen darüber entscheidet, ob sich der Zeitaufwand für Einrichtung und Wartung von Hermes Agent im Verhältnis zur Kostenersparnis lohnt.
Wann sich die Kosten für Hermes Agent lohnen (und wann nicht)
Die Kosten für Hermes Agent lohnen sich, wenn Sie den Dienst regelmäßig und für umfangreiche Workflows nutzen und nicht nur für gelegentliche Rückfragen. Die Hermes-Agent-Anwendungsfälle, die sich wirklich lohnen, sind mehrstufige Aufgaben, bei denen viele Modellaufrufe ausgelöst werden und ein dauerhaftes Setup die Kosten rechtfertigen kann.
Bei wenigen hundert Agent-Sitzungen pro Monat sind Pauschalabos für Endkunden in der Regel preislich im Vorteil, da sich ihre Fixgebühren auf eine Nutzung verteilen, die Sie nicht selbst steuern müssen.
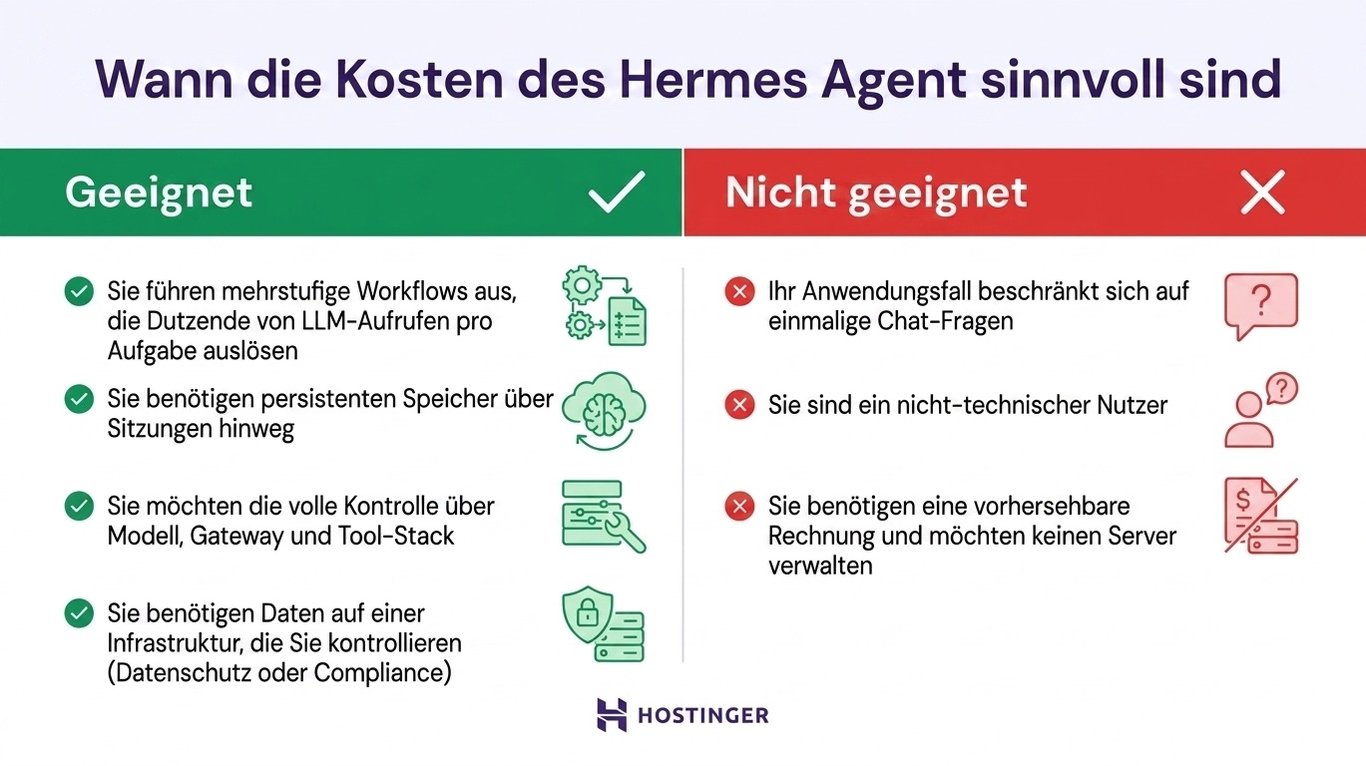
Gut geeignet, wenn:
- Sie mehrstufige Workflows ausführen, die bei jeder Aufgabe Dutzende von LLM-Aufrufen auslösen.
- Sie sitzungsübergreifenden, persistenten Speicher benötigen, den Hermes nativ bereitstellt.
- Sie die volle Kontrolle über Modell, Gateway und Tool-Stack möchten.
- Sie sicherstellen müssen, dass Daten aus Gründen des Datenschutzes oder zur Einhaltung von Vorschriften in einer Infrastruktur verbleiben, die Sie selbst kontrollieren.
Schlecht geeignet, wenn:
- Ihr Anwendungsfall einmalige Chat-Anfragen sind, nicht autonome Workflows.
- Sie ein nicht technischer Benutzer sind, da das Einrichten von Hermes Agent möglicherweise mehr Zeit kostet, als es einspart.
- Sie eine kalkulierbare Rechnung benötigen und möchten keinen Server verwalten.
Wenn Sie hauptsächlich gelegentliche Einzelfragen stellen, bleiben Sie bei ChatGPT oder Claude. Ab einigen hundert Sitzungen pro Monat können die Einsparungen und die zusätzliche Kontrolle den Aufwand rechtfertigen.
Budget für Ihren Hermes Agent festlegen
Um das Budget für Ihren Hermes Agent festzulegen, wählen Sie zuerst das Modell und erst danach den Anbieter. Diese eine Entscheidung kann Ihre monatlichen Kosten um das bis zu 30‑Fache verändern – weit mehr, als es jede Hosting-Wahl könnte.
Ein kostengünstiges LLM auf einem Server für 4 € pro Monat und ein Spitzen-LLM auf demselben Server können Rechnungen verursachen, die sich um etwa das 30-Fache unterscheiden. Deshalb sollte sich Ihre erste Planungsentscheidung auf das Modell konzentrieren, das Ihr Workload tatsächlich benötigt.
Sobald Sie eine Modellstufe ausgewählt haben, beobachten Sie zwei Kennzahlen in Ihrem Anbieter-Dashboard. Die erste Kennzahl ist die Cache-Hit-Rate. Bei einem cachefreundlichen Modell wie DeepSeek V4 Flash treffen wiederholte Tool-Definitionen auf den Cache und qualifizieren sich für rabattierte Preise, sodass das Verhältnis im Laufe der Zeit steigen sollte.
Die zweite Kennzahl ist die Anzahl der Tokens pro Anfrage. Eine CLI-Einrichtung fügt pro Anfrage in der Regel einen Overhead von 6.000 bis 8.000 Token hinzu. Wenn diese Zahl auf 15.000 bis 20.000 Token ansteigt, haben Sie möglicherweise auf ein Nachrichtengateway wie Telegram oder Discord umgestellt oder ein Tool hinzugefügt, das über ein solches Gateway läuft.
Stellen Sie abschließend eine Erinnerung auf zwei Wochen vor Ihrem VPS-Verlängerungsdatum ein, damit Sie eine Preiserhöhung nicht unvorbereitet trifft.
Alle Tutorial-Inhalte auf dieser Website unterliegen Hostingers strengen redaktionellen Standards und Normen.

Vera ist eine erfahrene Lokalisierungs-Spezialistin bei Hostinger und optimiert erfolgreich Inhalte für globale Zielgruppen. Dank ihres umfassenden SEO-Wissens sorgt sie dafür, dass Hostingers Webhosting-Dienste für ein breites Publikum sichtbar, zugänglich und attraktiv sind. Mit Kreativität mit Präzision überwindet sie Sprachbarrieren in ihren Projekten und trägt so dazu bei, Hostingers Reichweite zu vergrößern und Kunden weltweit ein nahtloses Erlebnis zu bieten.


Comments
0 responses