¿Qué es la seguridad en el vibe coding? Riesgos y buenas prácticas
Jun 24, 2026
/
Faradilla A.
/
19 min de lectura
La seguridad en el vibe coding consiste en mantener seguras las aplicaciones generadas con IA mediante la revisión del código, las dependencias, los controles de acceso y los procesos de desarrollo.
El vibe coding consiste en generar código con IA mediante prompts en lenguaje natural en lugar de escribirlo todo manualmente. Esto acelera el desarrollo, pero también implica riesgos.
La IA puede crear funciones que parecen funcionar bien a simple vista, pero que aun así incluyen configuraciones predeterminadas inseguras, secretos expuestos, autenticación débil o dependencias vulnerables.
Desarrollar aplicaciones más seguras impulsadas por IA depende de detectar esas carencias a tiempo. Eso significa aplicar controles de seguridad desde el principio, comprobar lo que el código hace realmente y usar las herramientas adecuadas para detectar problemas antes de que lleguen a producción.
¿Cómo genera riesgos de seguridad el vibe coding?
El vibe coding conlleva riesgos de seguridad porque la IA genera código sin validarlo desde el punto de vista de la seguridad.
Los modelos de lenguaje grandes (LLM) no entienden la seguridad como lo hace una persona desarrolladora o especialista en seguridad.
Estos modelos predicen el patrón más probable siguiente a partir de los datos de entrenamiento. Eso les ayuda a generar código rápidamente, pero no les ayuda a evaluar si el código es seguro. Un modelo puede generar algo que parece limpio y funciona en una demo, pero aun así no supera ni siquiera los controles de seguridad básicos.
El primer problema es que los LLM predicen patrones, no una lógica segura. Copian patrones de código habituales a partir de ejemplos que han visto y muchos de esos ejemplos están incompletos, desactualizados o no son seguros.
Un flujo de inicio de sesión, un formulario de pago, una función para subir archivos o un endpoint de una API pueden parecer correctos a simple vista, pero aun así pasar por alto las comprobaciones que protegen a las personas usuarias y a los datos reales.
El segundo problema es la falta de comprensión del contexto. La seguridad del código depende de todo el sistema que lo rodea: cómo inician sesión las personas usuarias, a qué datos pueden acceder, dónde se almacenan los secretos, qué roles existen y qué debe ocurrir cuando algo falla.
Un modelo de IA normalmente solo ve el prompt y la pequeña porción de código que le has dado. No entiende de forma fiable toda tu aplicación, tu modelo de amenazas ni tus requisitos de cumplimiento.
Como resultado, puede añadir código que entre en conflicto con el resto del sistema o crear una brecha entre componentes que por sí solos parecían seguros.
El tercer problema es que no hay comprobaciones de seguridad integradas durante la generación. Un modelo puede generar código, pero generarlo no es lo mismo que revisarlo, probarlo o validarlo.
Desarrollar software seguro requiere pasos adicionales, como validar las entradas, controlar el acceso, gestionar los secretos, limitar la tasa de solicitudes, registrar la actividad, revisar las dependencias y hacer pruebas de abuso. La IA no añade esas protecciones de forma predeterminada solo porque haya escrito el código.
El vibe coding fomenta un desarrollo rápido, y el desarrollo rápido suele pasar por alto la revisión. Cuando una función parece funcionar de inmediato, es más probable que los equipos la publiquen sin revisar bien el código, sin hacer una revisión de seguridad o sin probarla adecuadamente.
Eso crea un patrón peligroso: cuanto más rápido llega el código, más fácil es confiar en él antes de que alguien compruebe si es seguro.
Veamos un ejemplo. Le pides a la IA: “Crea un sistema de inicio de sesión.” Crea un formulario, comprueba el nombre de usuario y la contraseña y devuelve un token de sesión.
A primera vista, parece terminado. Pero el código podría almacenar las contraseñas de forma incorrecta, omitir la autenticación multifactor, no bloquear las cuentas tras varios intentos o permitir que se mantengan tokens de sesión débiles durante demasiado tiempo.
El sistema de inicio de sesión funciona, pero la autenticación no es lo bastante sólida como para proteger cuentas reales.
Ese es el riesgo principal del vibe coding: elimina la fricción al escribir código, pero también elimina las pausas en las que normalmente se detectan los errores de seguridad.
¿Cuáles son los principales riesgos de seguridad del vibe coding?
Los principales riesgos son generar código inseguro, usar secretos integrados en el código, depender de componentes con vulnerabilidades, no contar con autenticación ni autorización, conceder permisos excesivos y tener una falsa sensación de seguridad.
Cada uno de estos factores debilita una parte distinta del sistema, desde cómo se escribe el código hasta cómo se controla el acceso y cuánta confianza depositan los equipos de desarrollo en los resultados generados por la IA.
Esto no es un problema teórico. En el informe de Veracode de 2025 sobre la seguridad del código GenAI, solo el 55% del código generado era seguro, lo que significa que el 45% contenía una vulnerabilidad de seguridad conocida.
1. Generación de código inseguro
La IA puede generar código que funcione, pero aun así dejar lagunas de seguridad evidentes. El problema no es que la función falle. El problema es que funciona sin las comprobaciones que impiden el acceso a atacantes.
Una de las comprobaciones que más suelen faltar es validar correctamente las entradas de usuario. Cuando la entrada de usuario no se valida ni se sanitiza, se abren vías directas para los ataques.
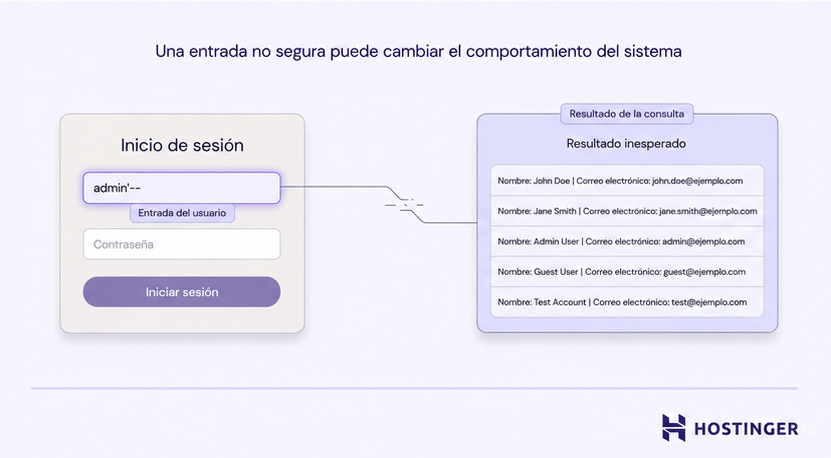
Un problema común es la inyección SQL. Esto ocurre cuando una aplicación crea una consulta a la base de datos directamente a partir de la entrada del usuario. Si no se gestiona la entrada de forma segura, una persona atacante puede modificar la consulta y extraer datos que nunca debería ver.
Por ejemplo, un formulario de inicio de sesión puede pedir un nombre de usuario y una contraseña, pero un código inseguro podría permitir que alguien escriba una entrada manipulada que convierta la consulta en “muéstrame todos los usuarios” en lugar de “comprueba esta cuenta”.
Otro riesgo de seguridad es el cross-site scripting (XSS). Aparece cuando una aplicación muestra la entrada del usuario sin limpiarla antes.
La IA suele generar funcionalidades de front-end como secciones de comentarios, formularios o perfiles de usuario sin sanitizar correctamente los datos de salida. El código funciona y muestra el contenido correctamente, pero no comprueba si es seguro mostrar ese contenido.
Una persona atacante puede enviar JavaScript malicioso y la web muestra después ese script a otras personas usuarias como si fuera contenido normal.
En la práctica, alguien podría usar un cuadro de comentarios para publicar código malicioso oculto. Cuando otra persona abre la página, ese código se ejecuta en su navegador y puede robar su sesión de inicio de sesión, lo que permite que quien ataque acceda a su cuenta.
Un tercer problema es la Insecure Direct Object Reference (IDOR), o referencia directa insegura a objetos. Ocurre cuando una aplicación usa ID en las URL, pero no comprueba si la persona usuaria puede acceder a esos datos concretos.
Por ejemplo, una persona usuaria podría abrir una página como /invoice/123 para ver su factura. Si la aplicación solo comprueba que la persona usuaria ha iniciado sesión, pero no si esa factura le pertenece, esta puede cambiar el número en la URL a /invoice/124 y ver la factura, el perfil o los detalles del pedido de otra persona.
Esto es común en el vibe coding porque la IA suele generar páginas y rutas que funcionan, pero omite las comprobaciones de propiedad que hay detrás. La función funciona, pero no controla quién debe tener acceso.
2. Secretos incrustados en el código generado por IA
La IA puede introducir datos sensibles directamente en el código en lugar de almacenarlos de forma segura.
Los secretos incluyen claves de API, contraseñas de bases de datos, tokens de acceso y credenciales privadas. No deben escribirse nunca dentro de los archivos fuente. Deben guardarse en un almacenamiento seguro, como variables de entorno o gestores de secretos, donde se pueda controlar y supervisar el acceso.
Le pides a la IA que genere código para conectarse a una API de pagos. Devuelve un fragmento de código funcional con una clave de API escrita directamente en el archivo:
API_KEY = "sk-123456789abcdef"
Esa clave parece real y el código funciona. Pero nunca debe escribirse directamente en el archivo de esa manera.
El verdadero peligro es la exposición. Una vez que un secreto entra en el código, se propaga rápidamente. Puede acabar en el control de versiones, repositorios compartidos, registros, copias de seguridad o incluso capturas de pantalla. A partir de ese momento, cualquiera que lo encuentre puede usarlo.
Ese acceso es inmediato. Una clave de API expuesta permite que alguien use tu cuenta, envíe solicitudes y genere costes como si fuera tu aplicación.
Una contraseña filtrada de la base de datos puede dar acceso total a los datos almacenados. Eso significa que alguien puede leer, copiar o eliminar toda tu base de datos.
Incluso un descuido breve, como subir código a un repositorio público durante unos minutos, basta para que bots automatizados detecten y capturen esos secretos. Una vez que eso ocurre, los atacantes pueden acceder a tu sistema casi de inmediato, a menudo antes de que siquiera notes la exposición.
3. Dependencias vulnerables o desactualizadas
Las dependencias vulnerables o desactualizadas generan riesgos porque la IA puede sugerir paquetes inseguros, obsoletos o inexistentes.
Las aplicaciones modernas dependen de bibliotecas de terceros para tareas como los pagos, la autenticación y la gestión de archivos. Eso te ahorra tiempo, pero también significa que estás confiando en código escrito por otra persona.
Si esa biblioteca tiene una vulnerabilidad conocida, tu aplicación la hereda. Eso significa que los atacantes pueden aprovechar esa vulnerabilidad para acceder a datos, hacer que las funciones dejen de funcionar o ejecutar acciones maliciosas dentro de tu sistema.
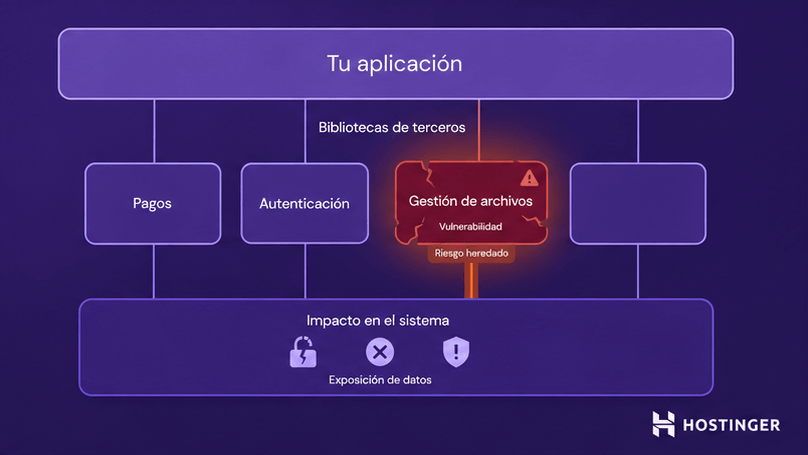
Esto se vuelve más peligroso en el vibe coding porque la IA sugiere lo que es probable, no lo que es seguro. Puede recomendar bibliotecas obsoletas con problemas conocidos o incluso generar nombres de paquetes que no existen.
Eso crea un riesgo de cadena de suministro. Puede que tu propio código esté bien, pero el paquete que instalas aun así puede dejar tu sistema expuesto. Una dependencia vulnerable puede darles a los atacantes una vía de entrada a través de sus propios fallos.
Una biblioteca falsa puede ir más allá y robar información confidencial, modificar archivos o ejecutar código malicioso durante la instalación.
Por ejemplo, le pides a la IA un paquete para gestionar la carga de archivos. Parece una biblioteca legítima, así que la instalas sin comprobarlo.
La función funciona, así que pasas a lo siguiente. Pero el paquete está desactualizado y tiene una vulnerabilidad conocida, o es un paquete malicioso con un nombre parecido. Ahora los atacantes pueden aprovechar esa dependencia para acceder a tu sistema o a tus datos.
4. Falta de autenticación y autorización
La falta de autenticación y autorización supone un riesgo grave porque el sistema no comprueba correctamente quién es una persona usuaria ni qué puede hacer.
La autenticación y la autorización resuelven dos problemas diferentes. La autenticación confirma la identidad, lo que significa que la persona usuaria es quien dice ser. La autorización controla el acceso, es decir, lo que esa persona puede ver o modificar. Si falta cualquiera de estos pasos, el sistema expone datos o acciones a las personas equivocadas.
Un fallo habitual consiste en dejar endpoints abiertos. Un endpoint es simplemente una URL que muestra datos o realiza una acción. Si esa URL no requiere iniciar sesión, cualquiera puede acceder a ella.
Por ejemplo, imagina una página como /users que muestra una lista de clientes. Si no hay ninguna comprobación de inicio de sesión, cualquiera que encuentre ese enlace puede abrirlo. Eso significa que los datos privados de las personas usuarias quedan visibles para el público, aunque debían mantenerse internos.

Otro problema común es que las comprobaciones de seguridad se aplican en algunos casos, pero faltan en otros.
Por ejemplo, tu panel de control puede requerir que las personas usuarias inicien sesión. Esa parte funciona correctamente. Pero, entre bastidores, la aplicación también puede tener una ruta de API como /api/export-data que devuelve los mismos datos.
Si esa ruta de la API no comprueba si has iniciado sesión, cualquiera podrá acceder a ella directamente al visitar la URL o enviar una solicitud. Así que, aunque la interfaz parezca segura, los datos siguen expuestos.
Otro problema es confiar en que la interfaz aplique los permisos.
Por ejemplo, podrías ocultar un botón de “Eliminar cuenta” para los usuarios habituales. Eso hace que parezca que no pueden eliminar cuentas.
Pero si el backend no verifica los permisos, tú aún puedes enviar una solicitud manualmente con las herramientas de desarrollador del navegador o una herramienta de API y activar la misma acción.
En otras palabras, ocultar algo en la interfaz de usuario no lo protege. El servidor debe aplicar la regla.
Esto es habitual en el vibe coding porque la IA suele generar interfaces y rutas funcionales sin aplicar comprobaciones coherentes en todo el backend. La función funciona como se espera en la interfaz de usuario, pero el sistema no controla por completo quién puede acceder a esas acciones o activarlas.
5. Permisos excesivos en los agentes de IA
Los permisos excesivos generan riesgos porque a los agentes de IA se les concede acceso a más recursos de tu sistema de los que realmente necesitan.
Los agentes de IA suelen conectarse a sistemas reales, como archivos, bases de datos o servicios en la nube. Si el acceso es demasiado amplio, pueden ir mucho más allá de la tarea que deben realizar.
Un agente pensado para leer tickets de soporte también podría editar datos de usuarios. Un agente diseñado para resumir logs también podría tener permiso para eliminar archivos o cambiar la configuración.
En la práctica, esto significa que un solo error puede convertirse en un incidente grave. El agente podría exponer datos sensibles, sobrescribir archivos importantes o provocar cambios en sistemas de producción sin que nadie lo notara de inmediato.
Imagina un agente de IA que te ayuda a organizar archivos en una unidad compartida de la empresa. Solo necesita acceso a una carpeta. En cambio, se le da acceso a toda la unidad. La tarea funciona, pero ahora un prompt deficiente o un pequeño error puede mover, eliminar o dejar expuestos archivos de finanzas, del área legal o de recursos humanos.
6. Falsa sensación de seguridad en los resultados de la IA
Una falsa sensación de seguridad es un riesgo importante en el vibe coding, ya que el código generado por IA puede parecer completo aunque no se haya revisado adecuadamente.
El código funciona, la página carga y parece que la función funciona. Eso genera confianza demasiado pronto. Parece terminado, así que se envía sin una revisión más a fondo. Pero que el código funcione no significa que sea seguro.
En la práctica, esto significa que se pasan por alto comprobaciones importantes. No se valida la entrada. No se aplican los permisos. Las acciones sensibles no están protegidas.
Por ejemplo, le pides a la IA que cree una función de “olvidé mi contraseña”. Crea un formulario en el que las personas usuarias introducen su email y les envía un enlace para restablecer la contraseña.
El enlace funciona. Haces clic en él, estableces una contraseña nueva y todo parece correcto.
Pero el enlace no caduca y no está vinculado a la persona usuaria correcta. Si alguien consigue acceder a ese enlace, podrá restablecer la contraseña y hacerse con el control de la cuenta.
¿Por qué los procesos de seguridad tradicionales fallan en el vibe coding?
Cuando comparas el vibe coding con la programación tradicional, la diferencia clave está en la rapidez con la que el código pasa de la idea a producción, a menudo sin pasar por las etapas de revisión en las que se detectan los problemas de seguridad.
Por ejemplo, imagina que creas una función para subir archivos que permita a las personas usuarias subir fotos de perfil. La función funciona: los usuarios suben un archivo y aparece en la página.
Pero nadie comprueba qué tipos de archivos se permiten.
Una persona atacante puede subir un archivo malicioso, como un script disfrazado de imagen. Cuando el sistema procesa o entrega ese archivo, puede ejecutar código malicioso o dejar expuesta la aplicación.
En un flujo de trabajo tradicional, quien revisa lo detectaría pronto. Aplicarían restricciones a los tipos de archivo, validarían las subidas de archivos y bloquearían los archivos ejecutables antes del lanzamiento.
En un flujo de trabajo de vibe coding, ese paso de revisión suele omitirse porque la función ya parece terminada.
Cómo proteger los flujos de trabajo del vibe coding
Para mantener tu flujo de trabajo seguro al usar IA, sigue estos pasos en tu proceso de desarrollo:
- Paso 1: revisa el código generado por IA. Revisa cada resultado antes de usarlo y comprueba cómo gestiona las entradas, los permisos y los errores.
- Paso 2: no incluyas datos confidenciales en tu código. Guarda las claves de API y los tokens en variables de entorno o en un gestor de secretos.
- Paso 3: configura la autenticación y la autorización desde el principio. Exige autenticación y aplica el control de acceso en cada solicitud.
- Paso 4: revisa y limpia todos los datos introducidos por la persona usuaria. Acepta solo los formatos previstos y maneja los datos de forma segura antes de usarlos.
- Paso 5: revisa las dependencias con regularidad. Escanea vulnerabilidades y mantén los paquetes actualizados.
- Paso 6: limita a qué pueden acceder los agentes de IA. Da solo el acceso necesario y restringe todo lo demás.
1. Valida todo el código generado por IA
Revisa cada contenido generado por IA antes de usarlo en tu base de código.
Empieza probando cómo el código maneja la entrada del usuario. Introduce datos no válidos directamente en la interfaz de usuario o en la API:
- Escribe letras en los campos numéricos
- Envía formularios vacíos
- Pega scripts como alert(1)
El sistema debe rechazar estas entradas con errores claros. Si las acepta o falla, falta validación.
A continuación, comprueba el control de acceso modificando las solicitudes. Inicia sesión como un usuario y luego:
- Cambia los ID en las URL (p. ej. /orders/123 → /orders/124)
- Repite las solicitudes a la API con distintos datos de usuario
Si puedes acceder a los datos de otra persona usuaria, falta autorización.
Escanea el código en busca de secretos. Busca en tu proyecto patrones como:
- API_KEY =
- password =
Elimina cualquier valor codificado de forma fija y pásalo a variables de entorno.
Revisa las dependencias introducidas por la IA. Mira package.json o los archivos de requisitos y:
- Busca el nombre del paquete en Google o GitHub
- Comprueba la fecha de la última actualización y el número de personas usuarias
- Ejecuta un análisis con herramientas como Snyk o npm audit
No instales paquetes que no puedas verificar.
Prueba directamente los casos de fallo. Haz que la funcionalidad falle a propósito:
- Envía solicitudes incompletas
- Elimina los campos obligatorios
- Simula sesiones caducadas
El sistema debería devolver errores, no fallar ni exponer datos.
Por último, compara el código con los patrones existentes en tu proyecto. Revisa cómo funciones similares gestionan la validación, los permisos y el acceso a los datos, y asegúrate de que el código nuevo siga la misma estructura.
2. Evita incrustar secretos en el código
Nunca guardes secretos directamente en tu código.
No incluyas secretos directamente en el código. Guarda las claves de la API, las contraseñas y los tokens fuera del código.
Defínelos en tu entorno:
API_KEY=abc123
Luego accede a ellos en tu código:
const apiKey = process.env.API_KEY;
Así mantienes los secretos fuera de tu base de código.
Antes de cada commit, comprueba si hay filtraciones con herramientas como git-secrets o Gitleaks. Estas herramientas analizan tu código y bloquean los commits que contienen datos confidenciales.
Guarda las credenciales sensibles en un gestor de secretos para los sistemas de producción. Usa herramientas como AWS Secrets Manager, HashiCorp Vault o Doppler para almacenar y acceder a los secretos de forma segura durante el tiempo de ejecución en lugar de guardarlos en archivos locales.
Restringe el acceso a cada secreto. Solo los servicios o las partes de tu sistema que necesiten un secreto deben poder leerlo.
Renueva los secretos periódicamente. Sustituye las claves de API y las contraseñas de forma periódica o inmediatamente después de cualquier sospecha de exposición.
Por último, comprueba si hay exposición. Sube el código a un repositorio privado y comprueba que no aparezca ninguna información confidencial en:
- Historial de commits
- Registros
- Mensajes de error
Si una clave secreta aparece en cualquier parte de tu código o de los registros, considérala comprometida y reemplázala de inmediato.
3. Implementa la autenticación y la autorización desde el principio
Configura la autenticación y la autorización desde el inicio de tu proyecto.
Añade comprobaciones de autenticación a todas las rutas que no sean públicas. En tu backend, protege las rutas con middleware o validaciones de acceso, por ejemplo, middleware de JWT o comprobaciones de sesión. Cada solicitud debe verificar que hayas iniciado sesión antes de devolver datos.
Compruébalo abriendo las rutas en una ventana privada del navegador o usando una herramienta como Postman sin iniciar sesión. La solicitud debería devolver un error, como 401 Unauthorized.
A continuación, aplica la autorización en cada solicitud. Después de confirmar que la persona usuaria ha iniciado sesión, comprueba a qué puede acceder. En la lógica de backend, compara el ID de la persona usuaria autenticada con el del propietario del recurso.
Por ejemplo, cuando gestiones una solicitud como /orders/123, obtén el pedido y verifica:
if (order.userId !== currentUser.id) {
return res.status(403).send("Forbidden");
}Ponlo a prueba iniciando sesión como una persona usuaria e intentando acceder a los datos de otra al cambiar los ID en la URL o en la solicitud a la API. El sistema debe devolver un error 403 Forbidden.
No confíes en los ID que vienen del cliente. Valídalos siempre en el servidor. Aunque el frontend oculte ciertos datos, asume que las personas usuarias pueden modificar las solicitudes manualmente.
Aplica la misma lógica de control de acceso en toda la aplicación. Usa middleware, funciones auxiliares o políticas compartidas en lugar de escribir comprobaciones personalizadas para cada endpoint. Esto evita que queden rutas sin proteger.
Prueba directamente los escenarios no autorizados. Usa herramientas como Postman o las herramientas de desarrollo del navegador para:
- Elimina los tokens de autenticación
- Modifica las cargas útiles de las solicitudes
- Repite las solicitudes con distintos datos de usuario
Se debe bloquear toda solicitud no autorizada.
Por último, incluye comprobaciones de autenticación y autorización al desarrollar cada nueva funcionalidad. No los añadas más tarde. Cuando crees un nuevo endpoint, empieza por añadir la protección primero y luego implementa la lógica de la funcionalidad.
4. Sanitiza y valida las entradas de usuario
Trata toda entrada de usuario como no segura y valídala antes de usarla en cualquier parte de tu sistema.
Empieza añadiendo reglas de validación en tu backend. Usa una biblioteca de validación como Joi, Zod o los validadores integrados del framework para definir qué debe aceptar cada campo.
Por ejemplo:
const schema = z.object({
email: z.string().email(),
age: z.number().int().min(0)
});Ejecuta esta validación antes de procesar la solicitud. Si la entrada no coincide con el esquema, devuelve un error y detén la ejecución:
if (!schema.safeParse(req.body).success) {
return res.status(400).send("Invalid input");
}No intentes corregir una entrada no válida. Recházala y pídele a la persona usuaria que envíe los datos correctos.
A continuación, sanitiza los datos antes de usarlos en consultas o mostrarlos en una página. Usa protecciones integradas, como motores de plantillas que escapan el HTML de forma predeterminada y bibliotecas como DOMPurify para el contenido generado por usuarios.
Para las consultas a la base de datos, usa siempre consultas parametrizadas en lugar de concatenar cadenas:
// safe
db.query("SELECT * FROM users WHERE email = ?", [email]);
// unsafe
db.query(`SELECT * FROM users WHERE email = '${email}'`);Prueba directamente cómo gestionas la entrada. Prueba:
- Introduce scripts como <script>alert(1)</script>
- Enviar cadenas largas o inesperadas
- Enviar formatos no válidos a través de herramientas de API como Postman
El sistema debe rechazar la entrada o escapar de ella de forma segura. No debe ejecutar código ni devolver datos inesperados.
Si tu aplicación incluye la carga de archivos, restringe los tipos y tamaños de archivo en el servidor. No confíes en las comprobaciones del lado del cliente.
Por último, aplica las mismas reglas de validación y saneamiento a cada fuente de entrada. Esto incluye formularios, solicitudes de API, parámetros de URL y cargas de archivos. No des por hecho que una entrada es segura solo porque proviene de tu frontend.
5. Supervisa las dependencias de forma continua
Haz un seguimiento de todas las dependencias de tu proyecto y revísalas periódicamente para detectar vulnerabilidades conocidas.
Empieza por ejecutar un análisis de dependencias en tu entorno local. Usa herramientas integradas como:
npm audit
o
pip-audit
Esto muestra las vulnerabilidades conocidas en tus dependencias actuales.
A continuación, automatiza esto en tu flujo de trabajo. Añade a tu repositorio un escáner de dependencias como Dependabot, Snyk o Aikido. Por ejemplo, activa Dependabot en GitHub para que analice automáticamente tus dependencias y abra pull requests con correcciones de seguridad.
Esto elimina la necesidad de comprobarlo manualmente.
Antes de instalar cualquier paquete, compruébalo manualmente:
- Busca el nombre del paquete en npm o PyPI
- Comprueba la fecha de la última actualización
- Comprueba el número de descargas o de estrellas en GitHub
Si el paquete no tiene actividad o parece sospechoso, no lo instales.
Fija las versiones de tus dependencias para evitar cambios inesperados. Usa archivos de bloqueo como:
- package-lock.json
- yarn.lock
- requirements.txt
Evita versiones flexibles como:
"library": "^1.0.0"
Usa versiones fijas en su lugar:
"library": "1.0.0"
Actualiza las dependencias con regularidad. Cuando una herramienta marca una vulnerabilidad:
- Ejecuta la actualización (npm update o algo similar)
- Revisa qué cambió
- Prueba la función afectada
No retrases las actualizaciones, porque las vulnerabilidades conocidas se suelen explotar activamente.
Elimina las dependencias que no uses revisando los archivos de tu proyecto. Si un paquete no se importa ni se usa en ninguna parte, elimínalo y ejecuta:
npm uninstall package-name
Esto reduce los riesgos innecesarios.
Después de cada actualización, prueba la función que depende de ese paquete. Por ejemplo:
- actualiza la biblioteca de cargas → prueba la carga de archivos
- actualiza la biblioteca de autenticación → prueba el flujo de inicio de sesión
Por último, comprueba que todo funcione y que no quede ninguna vulnerabilidad:
npm audit
El análisis no debería detectar ningún problema crítico.
6. Limita los permisos de los agentes de IA
Dale a cada agente de IA solo el acceso que necesita para completar su tarea.
Empieza por definir de forma concreta el alcance del agente. Escribe exactamente lo que debe hacer, por ejemplo: “Leer tickets de soporte desde la API /tickets” o “Resumir los archivos de la carpeta /reports“.
Crea credenciales restringidas en lugar de usar claves con acceso completo. Cuando generes una clave o un token de API, configura los permisos para permitir solo acciones específicas. Por ejemplo:
- Permitir: GET /tickets
- Bloquear: POST, DELETE o acciones de administración
Evita usar credenciales de root, admin o de acceso total.
Limita el acceso a recursos específicos. En tu sistema o proveedor en la nube:
- Concede acceso a una sola carpeta en lugar de a todo el bucket de almacenamiento
- Permite una sola tabla de la base de datos en lugar de toda la base de datos
- Restringe las API a endpoints específicos
Usa roles de IAM o políticas de permisos para aplicar esto.
Empieza con acceso de solo lectura. Asigna permisos que solo permitan leer datos. Luego prueba el agente. Añade permisos de escritura o eliminación solo si la tarea falla sin ellos.
Primero, ejecuta el agente en un entorno de prueba. Conéctalo a los datos del entorno de pruebas en lugar de a producción. Verifica cómo funciona antes de darle acceso a personas reales o a sistemas.
Prueba los permisos intentando vulnerarlos. Usa el agente o la API manualmente para:
- Acceder a otra carpeta
- Modificar datos cuando solo debería leer
- Invocar endpoints fuera de su ámbito
Cada intento debería fallar con una respuesta de “acceso denegado” o “403 Forbidden“.
Activa el registro de todas las acciones del agente. Registra:
- A qué archivos accede
- A qué API llama
- Qué acciones realiza
Revisa los registros después de ejecutar el agente. Confirma que solo realiza las acciones que definiste antes.
Si el agente puede hacer más de lo previsto, reduce sus permisos y vuelve a probar.
¿Qué herramientas ayudan a proteger el código generado por IA?
Las herramientas de vibe coding te ayudan a crear aplicaciones rápidamente, pero no las protegen de forma predeterminada. Para proteger el código generado por IA, necesitas un conjunto independiente de herramientas que se divide en tres grupos: análisis de código, análisis de dependencias y protección en tiempo de ejecución.
Herramientas como Aikido, Snyk y CodeAnt cubren distintas partes de este flujo de trabajo, mientras que la matriz de controles de IA de CSA ayuda a definir qué controles aplicar.
Análisis de código (SAST)
Las pruebas estáticas de seguridad de aplicaciones o SAST, analizan el código fuente en busca de patrones de riesgo antes de que lo publiques.
Esto te resulta útil para detectar problemas en el código generado por IA, como el manejo inseguro de entradas, secretos expuestos o una lógica débil en las pull requests y los IDE. Las herramientas de este grupo incluyen Aikido, CodeAnt y Snyk Code.
Análisis de dependencias
Los escáneres de dependencias revisan los paquetes de terceros de los que depende tu código y señalan las vulnerabilidades conocidas. Esto importa en el vibe coding porque la IA puede sugerir bibliotecas desactualizadas o incluso nombres de paquetes que debes verificar antes de instalarlos.
Snyk y Aikido analizan las dependencias de código abierto y CodeAnt también incluye análisis de composición de software en su plataforma.
Protección en tiempo de ejecución
Algunos problemas solo aparecen con tráfico real, no durante la revisión del código. La protección en tiempo de ejecución supervisa lo que sucede después de implementar el código y ayuda a detectar o bloquear ataques en vivo.
Aikido es un ejemplo de plataforma que va más allá del análisis de código y dependencias para detectar y bloquear amenazas en tiempo de ejecución.
Dónde encaja CSA
CSA es diferente de las herramientas anteriores. No es un escáner. La matriz de controles de IA de Cloud Security Alliance es un marco de controles neutral respecto a proveedores para proteger sistemas de IA, por lo que te conviene usarla para definir tu proceso, revisar los requisitos y establecer una base de seguridad en torno al código generado por IA.
Checklist de seguridad para el vibe coding
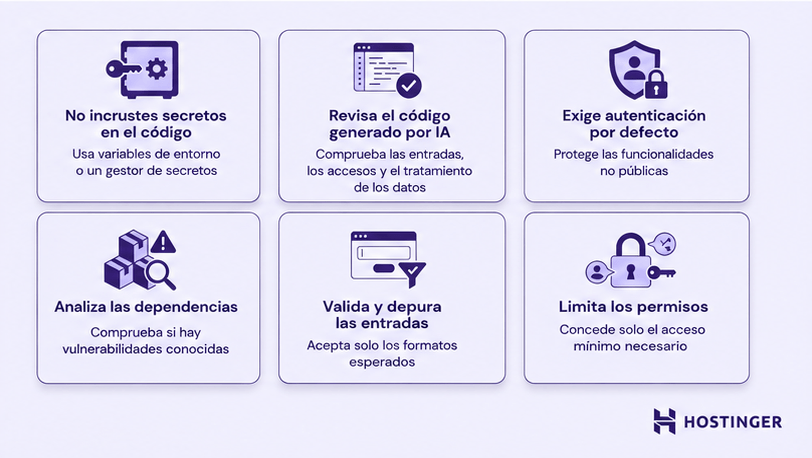
Usa esta lista de verificación como una forma rápida de detectar los riesgos más comunes antes de que el código llegue a producción.
- No incrustes secretos en el código: mantén las claves de API, las contraseñas y los tokens fuera del código y guárdalos en variables de entorno o en un gestor de secretos.
- Revisa todo el código generado por IA: trata el resultado de la IA como un borrador y comprueba cómo maneja la entrada de datos, el control de acceso y los datos sensibles antes de usarlo.
- Exige autenticación de forma predeterminada: haz que iniciar sesión sea lo habitual en cualquier función no pública para que los endpoints no queden abiertos por accidente.
- Analiza las dependencias para detectar vulnerabilidades conocidas: revisa periódicamente los paquetes de terceros para evitar incorporar código inseguro o desactualizado en tu aplicación.
- Valida y sanitiza las entradas de las personas usuarias: asegúrate de que todas coincidan con los formatos esperados y no puedan usarse para inyectar código malicioso.
- Limita los permisos de los agentes y las herramientas de IA: dales solo el acceso mínimo necesario para que los errores o los usos indebidos queden contenidos.
Qué debes saber antes de usar vibe coding en producción
El vibe coding te permite avanzar más rápido, pero también aumenta el riesgo de seguridad.
La IA te permite generar funcionalidades que funcionan rápidamente, pero un código más rápido no significa necesariamente que sea más seguro. Cuando se produce más código en menos tiempo, resulta más fácil pasar por alto las revisiones y no detectar problemas de seguridad.
Esto cambia la forma en que necesitas enfocar el desarrollo. No trates el código generado por IA como si fuera de confianza. Trátalo como un borrador que debes revisar, probar y validar antes de publicarlo.
Por ejemplo, la IA puede generar un panel de control funcional en cuestión de minutos. Las páginas cargan y los datos aparecen, pero sin comprobaciones de acceso adecuadas, las personas usuarias pueden ver datos que no deberían. La función funciona, pero no es segura.
Para usar el vibe coding de forma segura en producción, sigue por defecto las mejores prácticas de seguridad para aplicaciones web. Exige autenticación, valida la entrada, protege los secretos, revisa las dependencias y limita los permisos.
La seguridad también debe integrarse en tu flujo de trabajo. No confíes en las comprobaciones manuales al final. Añade análisis automatizados, exige revisiones y prueba los casos límite como parte del desarrollo.
La plataforma que usas también influye en lo seguro que puede ser crear y lanzar apps generadas con IA. Por ejemplo, la herramienta de vibe coding de Hostinger Horizons combina la creación de apps a partir de prompts, hosting integrado y publicación con 1 clic en un solo entorno, lo que reduce el trabajo de configuración que suele dar lugar a errores durante el despliegue.
También incluye protecciones a nivel de infraestructura, como un firewall, análisis de malware y protección contra ataques DDoS, junto con funciones como el historial de versiones del proyecto y soporte de backend integrado para cuentas, inicios de sesión y almacenamiento de datos.
Esto ayuda a acelerar el lanzamiento y a reforzar la seguridad operativa, pero no sustituye la seguridad a nivel de aplicación. Aún necesitas revisar la lógica generada, validar las entradas, aplicar autenticación y autorización, proteger los secretos y probar cómo se comporta la app antes de publicarla.
Todo el contenido tutorial en este sitio web está sujeto a los estándares y valores editoriales más rigurosos de Hostinger.

Faradilla, or Ninda, is a Content Marketing Specialist with a passion for technology, a curiosity for digital marketing trends, and a love for languages. When she's not writing Hostinger tutorials, you can find her learning about life sciences. Follow her on LinkedIn.
Comentarios
0 responses