Commande cut sous Linux: syntaxe, options et exemples pratiques
Apr 16, 2026
/
Katerina B.
/
8 minutes de lecture
Lorsque vous travaillez avec Linux, vous êtes souvent amené à manipuler des données textuelles structurées dans un fichier, la sortie d’une commande ou des caractères générés par un script. La plupart du temps, vous n’avez pas besoin de tout. Vous pouvez simplement vouloir une colonne précise, quelques caractères ou une partie particulière de chaque ligne. C’est là qu’intervient la commande cut.
cut est une commande Linux simple, intégrée, qui extrait des parties de texte de chaque ligne d’entrée. Il peut fonctionner à partir de positions de caractères, de décalages d’octets ou de champs séparés par un caractère délimiteur. C’est rapide, facile à intégrer dans des scripts et idéal pour ne conserver dans la sortie que les éléments qui vous intéressent.
Ce guide explique le fonctionnement de cut, comment utiliser ses principales options et dans quels cas l’employer au quotidien comme dans des scripts en conditions réelles. Si vous êtes de plus en plus à l’aise avec la ligne de commande Linux, c’est un outil que vous utiliserez plus souvent que vous ne le pensez.

Aperçu de la syntaxe de la commande Linux cut
La syntaxe de base de la commande Linux cut dépend de la provenance des données d’entrée. Vous pouvez utiliser cut de deux manières principales :
- Avec un fichier d’entrée – transmettez le nom du fichier texte comme argument, puis cut lit et traite chaque ligne.
- Avec l’entrée standard (stdin) – Transférez directement la sortie d’une autre commande vers cut à l’aide de |.
Cette flexibilité signifie que la commande cut fonctionne avec presque tout ce qui produit une sortie ligne par ligne : des fichiers, les résultats de commandes comme ls, ps ou cat, et même de simples instructions echo dans des scripts.
Voici à quoi ressemble la syntaxe générale :
cut [OPTION] [VALEUR] [FICHIER] [DONNÉES] | cut [OPTION] [VALEUR]
[/VALEUR][/OPTION][/FICHIER][/VALEUR][/OPTION]
La commande `cut` renvoie les données vers la sortie standard (stdout).
Options essentielles de la commande cut
La commande `cut` propose trois options principales :
- -c (caractère) – sélectionne un seul caractère ou plusieurs caractères définis dans chaque ligne en fonction de leur position spécifiée.
- -b (octet) – sélectionne un seul octet ou plusieurs octets dans chaque ligne.
- -f (champ) – extrait les champs séparés par un délimiteur. C’est l’option la plus couramment utilisée en pratique.
Les trois options principales nécessitent une valeur numérique, qui peut indiquer :
- Position exacte – une seule valeur. L’utilisation de -f 2 renverra le deuxième champ d’une ligne. Les champs ne peuvent utiliser que des positions exactes.
- Plage – Une liste de nombres séparés par un trait d’union. Utiliser `-b 2-5` renverra les octets précis compris entre 2 et 5.
- Argument LISTE – Une combinaison des éléments ci-dessus, séparés par des virgules. L’utilisation de -c 1,5-7 renverra le premier caractère ainsi que les caractères 5, 6 et 7.
Vous pouvez également passer des options supplémentaires à la commande cut :
- -d – définit le délimiteur d’entrée lors du traitement des champs. Cela sert de séparateur de champ entre plusieurs champs. Le délimiteur par défaut est le caractère de tabulation.
- –output-delimiter – définit un délimiteur de sortie différent lors de la sélection de plusieurs champs. Elle correspond à l’option -d si celle-ci n’est pas spécifiée.
- –complement – inverse la sélection. Au lieu d’inclure les octets, caractères ou champs spécifiés, il les exclut et renvoie tout le reste.
Exemples d’utilisation de la commande Linux cut
Maintenant que nous avons vu les bases, examinons comment chaque option de découpe fonctionne en pratique.
Utiliser cut par caractères et octets
La commande cut vous permet d’extraire des parties précises de chaque ligne en utilisant soit des caractères (-c), soit des octets (-b). En théorie, ces options ont des usages différents : –c pour sélectionner des caractères précis, et -b pour des positions exactes en octets.
Cela avait du sens à l’époque où Linux utilisait principalement l’ASCII, où chaque caractère occupait exactement un octet, et où il était courant qu’un octet précis indique une valeur donnée, par exemple le premier octet pour signaler le niveau de journalisation dans une solution historique de journalisation.
Les systèmes modernes utilisent UTF-8, qui prend en charge des caractères multioctets comme è ou ñ. Cependant, la commande cut ne gère pas les caractères multioctets. Ainsi, lorsque vous utilisez l’option -c, elle suppose toujours qu’il s’agit de caractères à un seul octet. En pratique, cela signifie que -b et -c se comportent de la même manière dans la plupart des cas d’usage modernes.
Voici un exemple rapide pour vous le montrer :
echo "crème" > sample.txt cut -c 2-4 sample.txt cut -b 2-4 sample.txt
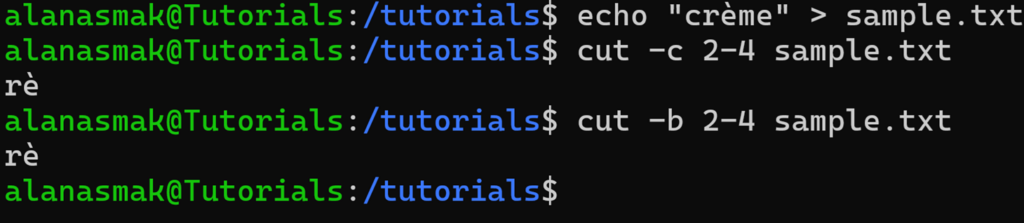
Décomposons le mot crème :
| Lettre | c | r | è | m | e |
| Octet | 1 | 2 | 3-4 | 5 | 6 |
Le point essentiel est que le caractère spécial è occupe 2 octets de stockage. Ainsi, même si vous avez défini la position de départ sur 2 et la position de fin sur 4, ce qui devrait donner trois caractères, vous n’en obtenez que deux.
Si vous essayez d’extraire uniquement le troisième caractère, voici ce qui se passe :
cut -c 3 sample.txt cut -b 3 sample.txt

Comme la position du 3e octet se situe au milieu du caractère è, la commande cut affiche un symbole incompréhensible.
Astuce
Nous vous recommandons d’utiliser la commande awk si vous prévoyez d’utiliser des caractères multioctets. Dans cet exemple, awk '{print substr($0, 3, 1)}' sample.txt renverrait correctement le caractère spécial, car il peut interpréter l’encodage UTF-8.
Utiliser cut avec des champs
L’option -f sert à extraire des champs spécifiques de chaque ligne d’entrée. Il peut être utilisé avec un délimiteur qui sépare ces champs, comme une virgule ou un espace, ou avec le délimiteur de tabulation par défaut.
Voici un exemple qui simule un tableau de base de l’état des utilisateurs :
printf "name\tstatus\trole\nalice\tactive\tadmin\nbob\tinactive\tguest\n" > users.txt
Cette commande crée un fichier appelé users.txt avec des valeurs séparées par des tabulations. Chaque ligne contient trois champs : le nom de l’utilisateur, le statut et le rôle.
Pour extraire uniquement les noms d’utilisateur, vous pouvez utiliser :
cut -f 1 users.txt

Vous pouvez également demander plusieurs champs. Pour obtenir le nom d’utilisateur et le rôle, vous pouvez exécuter :
cut -f 1,3 users.txt

Utilisation d’un délimiteur personnalisé
La plupart des données que vous rencontrerez ne sont pas séparées par des tabulations. Vous travaillerez souvent avec des fichiers ou des sorties de commande où des virgules, des deux-points ou d’autres symboles servent de séparateurs de champs, et le délimiteur de tabulation par défaut ne conviendra pas. Pour que la commande `cut` fonctionne dans ces cas, vous pouvez définir un caractère spécifique comme délimiteur avec l’option `-d`.
Examinons un fichier d’environnement que vous pourriez trouver dans une application hébergée sur un serveur Linux :
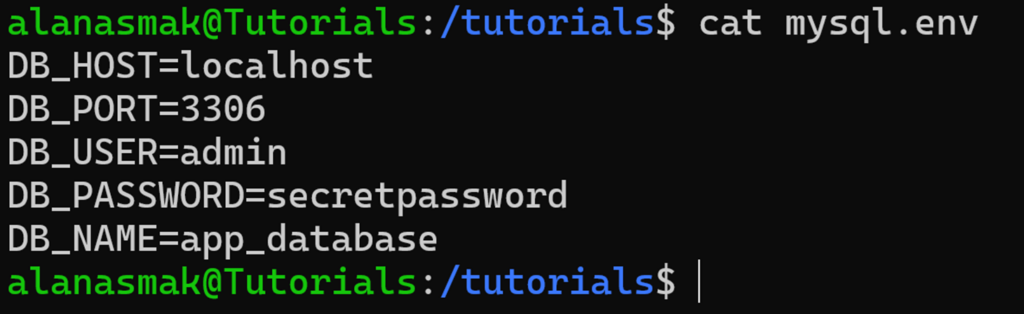
Pour obtenir toutes les valeurs de ce fichier, vous pouvez utiliser :
cut -f 2 -d = mysql.env
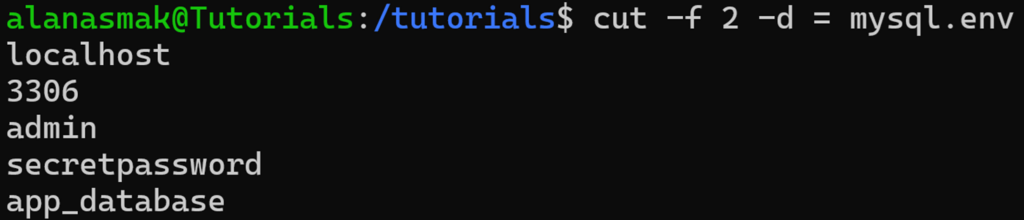
Dans cette commande, vous définissez le délimiteur de champ sur =, ce qui signifie que tout ce qui se trouve avant ou après ce symbole sur chaque ligne est compté comme un champ. Ensuite, utilisez `cut` pour extraire le champ souhaité.
Exclure les lignes sans délimiteur
Par défaut, la commande cut traite chaque ligne, même si une ligne ne contient pas le délimiteur que vous avez spécifié. Cela peut produire des résultats inattendus.
Supposons que le fichier mysql.env contienne un commentaire :
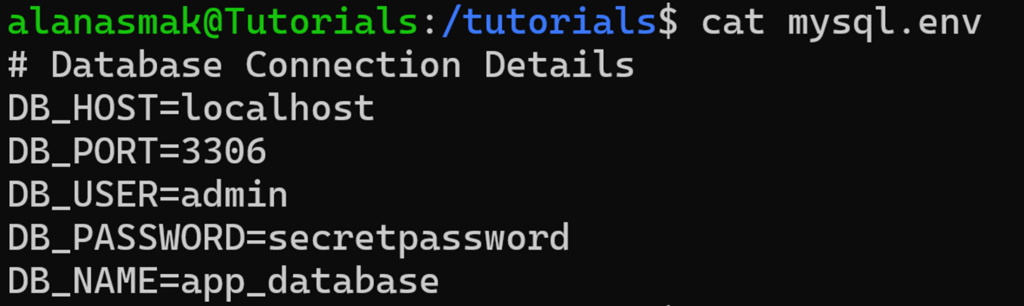
Si vous exécutez la même commande `cut` qu’auparavant, vous obtenez maintenant :
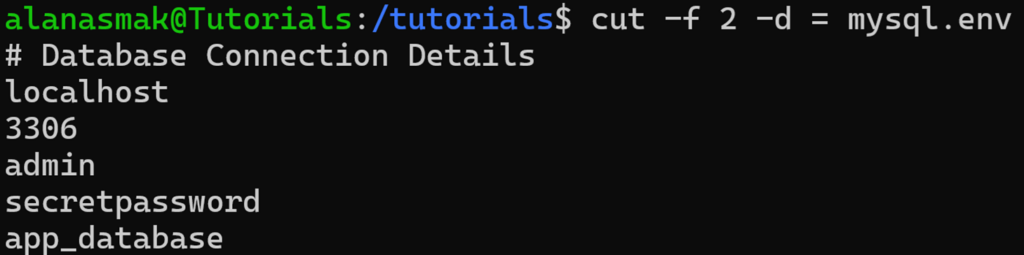
Comme le délimiteur est absent de la ligne, elle renvoie la ligne entière.
Pour exclure ce type de lignes, la commande cut dispose aussi de l’option -s. Cela exclut de la sortie toutes les lignes qui ne contiennent pas le délimiteur, afin que seules les valeurs qui vous intéressent soient renvoyées. Exécutez :
cut -f 2 -d = -s mysql.env
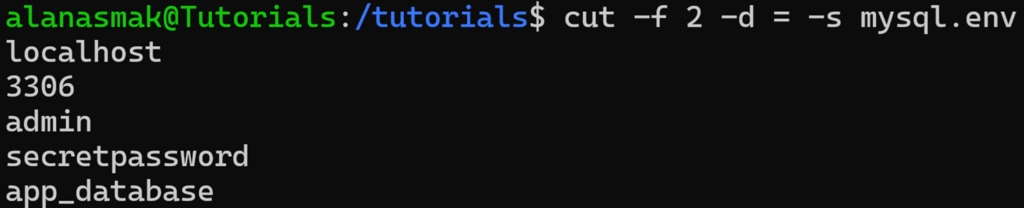
Désormais, cela exclut toute ligne dans laquelle le délimiteur spécifié n’est pas présent. Comme notre commentaire ne contient pas le symbole =, il est ignoré.
Utiliser cut avec des pipes
L’une des façons les plus pratiques d’utiliser la commande cut sous Linux est de l’intégrer à un pipeline. Au lieu de lire à partir d’un fichier, vous pouvez lui transmettre la sortie d’une autre commande à l’aide de l’opérateur de pipe (|).
Voici un exemple de base :
echo "name=admin" | cut -d '=' -f 2

Cela fonctionne de la même manière que la lecture à partir d’un fichier texte, mais traite à la place la sortie standard des données transmises par le pipe.
L’utilisation de `cut` dans des pipelines est particulièrement utile dans les scripts ou les one-liners lorsque vous devez traiter du texte rapidement sans créer de fichiers intermédiaires.
Cas d’utilisation concrets de la commande cut
Maintenant que vous savez comment fonctionne la commande cut, voyons comment l’utiliser efficacement dans des cas concrets.
Extraire des champs spécifiques d’un fichier CSV
Les fichiers de valeurs séparées par des virgules (CSV) sont un moyen courant de stocker et de partager des données structurées : listes d’utilisateurs, exportations d’applications web, rapports de facturation ou journaux. Mais la plupart du temps, vous n’avez pas besoin du fichier entier : seules une ou deux colonnes précises vous intéressent. C’est là qu’intervient la coupe.
Dans cet exemple, vous gérez une application web et devez envoyer un e-mail à tous les utilisateurs actifs. Vous exportez votre liste d’utilisateurs, et vous obtenez un fichier users.csv comme celui-ci :
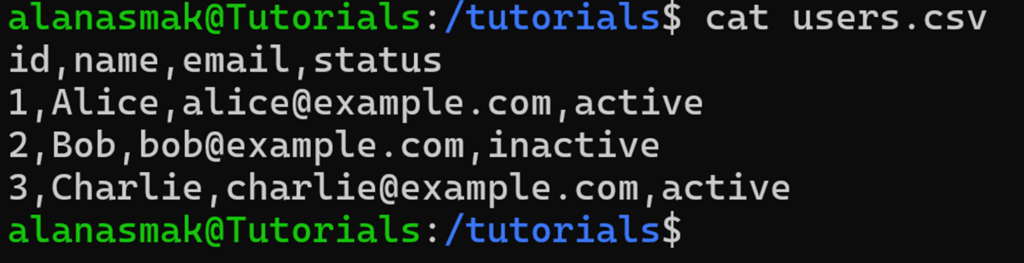
Pour obtenir la liste des seules adresses e-mail actives, vous pouvez combiner grep et cut :
grep ',active$' users.csv | cut -d ',' -f 3 >> active.txt

Cela enregistrera toutes les adresses e-mail de tous les utilisateurs actifs dans un fichier active.txt, que vous pourrez ensuite utiliser comme liste de diffusion.
C’est là que la commande cut se distingue : le fichier CSV est déjà structuré, et vous n’avez besoin que d’une colonne précise. C’est rapide, fiable et facile à enchaîner avec d’autres commandes comme grep lorsque vous travaillez directement dans le terminal.
Chargement des identifiants de base de données depuis un fichier .env
Se connecter à une base de données MySQL depuis le terminal est assez fastidieux. Pour simplifier cela, de nombreux développeurs utilisent des fichiers .env pour stocker les identifiants de base de données et écrivent des scripts simples pour automatiser la connexion.
Examinons à nouveau notre fichier mysql.env de l’exemple précédent :
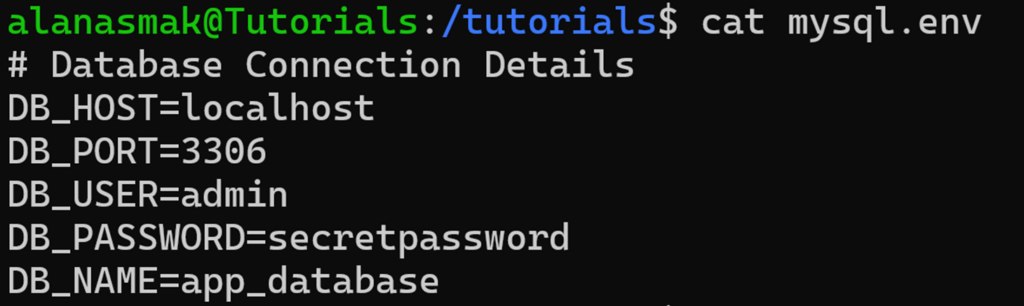
Sur le papier, il contient tout ce dont vous avez besoin pour vous connecter à un hôte MySQL, et il vous suffit de renseigner la commande mysql avec les valeurs exactes. Mais les saisir manuellement ou les coder en dur dans un script n’est pas une solution idéale. À la place, vous pouvez associer `cut` à d’autres commandes pour extraire et utiliser uniquement les valeurs dont vous avez besoin.
- Créez un nouveau fichier de script :
touch connect.sh chmod +x connect.sh
- Ouvrez le fichier avec l’éditeur de votre choix. Pour cet exemple, nous utiliserons nano :
nano connect.sh
- Saisissez les valeurs suivantes :
#!/bin/bash DB_HOST=$(grep DB_HOST mysql.env | cut -d '=' -f 2) DB_PORT=$(grep DB_PORT mysql.env | cut -d '=' -f 2) DB_USER=$(grep DB_USER mysql.env | cut -d '=' -f 2) DB_PASSWORD=$(grep DB_PASSWORD mysql.env | cut -d '=' -f 2) DB_NAME=$(grep DB_NAME mysql.env | cut -d '=' -f 2)
Vous utilisez une combinaison de grep pour récupérer la ligne exacte dont vous avez besoin et de cut pour renvoyer la valeur, qui est ensuite stockée dans une variable du shell.
- Pour tester cela, ajoutez la chaîne suivante :
echo 'La chaîne de connexion est : mysql -h ' $DB_HOST ' -P ' $DB_PORT ' -u ' $DB_USER ' -p ' $DB_PASSWORD $DB_NAME
La commande ci-dessus affichera la chaîne analysée dans votre terminal. Voici à quoi ressemble le script complet :

- Enregistrez le fichier avec Ctrl+X → Y → Entrée.
Maintenant, si vous exécutez le script connect.sh, vous obtiendrez la chaîne de connexion complète de votre base de données :

Vous pouvez également remplacer l’instruction echo par :
mysql -h $DB_HOST -P $DB_PORT -u $DB_USER -p $DB_PASSWORD $DB_NAME
De cette façon, au lieu de vous fournir la chaîne de connexion, il tentera automatiquement de se connecter.
La commande cut est particulièrement puissante lorsqu’elle est utilisée en combinaison avec d’autres commandes. C’est un outil polyvalent pour analyser les données nécessaires à l’automatisation.
Conclusion
La commande `cut` sous Linux est un outil simple mais efficace pour travailler avec des données structurées. Il est rapide, fiable et facile à utiliser dans des scripts ou des commandes d’une seule ligne. Lorsque la structure est cohérente, cut fait souvent le travail plus rapidement que des outils plus lourds.
Si vous êtes à l’aise avec le terminal Linux et que vous souhaitez automatiser certaines parties de votre flux de travail, la commande cut vous sera très utile, et plus encore lorsqu’elle est combinée à d’autres commandes Linux.
FAQ sur la commande Linux cut
À quoi sert la commande cut sous Linux ?
La commande `cut` sous Linux extrait des sections spécifiques de chaque ligne de texte d’un fichier ou d’un flux d’entrée. Vous pouvez sélectionner des octets, des caractères ou des champs en fonction de délimiteurs. Il est couramment utilisé pour extraire des colonnes à partir de fichiers CSV, de fichiers de configuration, de journaux ou de la sortie de commandes dans des scripts et des commandes en une ligne.
Comment extraire des champs spécifiques d’un fichier avec la commande cut ?
Pour extraire des champs spécifiques, utilisez l’option -f avec -d pour définir le délimiteur. Par exemple, `cut -d ‘,’ -f 2 file.csv` extrait le deuxième champ d’un fichier séparé par des virgules. Vous pouvez également utiliser -f avec une plage ou une liste, comme -f 1,3, pour extraire plusieurs champs.
Puis-je utiliser plusieurs délimiteurs avec la commande cut ?
Non, `cut` ne prend en charge qu’un seul délimiteur à la fois, mais vous pouvez définir un délimiteur de sortie différent de celui que vous avez indiqué avec l’option `-d`. Si vous devez utiliser plusieurs délimiteurs d’entrée, prétraitez votre fichier avec une commande comme sed afin de vous assurer que tous les délimiteurs correspondent.
Tout le contenu des tutoriels de ce site est soumis aux normes éditoriales et aux valeurs rigoureuses de Hostinger.

Katerina is a Localization Project Manager at Hostinger, bringing over 5 years of project management experience and a 6-year background as a linguist. She focuses on making technology more approachable by transforming complex guides into clear, easy-to-follow tutorials. In her free time, when she’s not staying up-to-date with the latest in localization, she enjoys watching movies and reading books.



Commentaires
0 responses