Cómo integrar n8n con Ollama para flujos de trabajo LLM locales
Mar 10, 2026
/
Diego B.
/
12 min Leer
La integración de n8n con Ollama te permite aprovechar varios modelos de IA en tu flujo de trabajo de automatización, permitiéndote realizar operaciones complejas que de otro modo serían imposibles.
Sin embargo, el proceso puede ser complicado porque hay que configurar varios parámetros en ambas herramientas para que funcionen a la perfección.
Si ya tienes n8n y Ollama instalados en tu servidor, puedes integrarlos en cuatro sencillos pasos:
- Añade el nodo del modelo de chat de Ollama
- Elige el modelo de IA y ajusta sus parámetros de ejecución
- Configura los ajustes de aviso del nodo agente IA
- Envia un aviso de prueba para verificar la funcionalidad
Una vez completados estos pasos, dispondrás de un flujo de trabajo de procesamiento de IA funcional e impulsado por Ollama, que podrás integrar en un sistema de automatización más completo. Por ejemplo, puedes conectar aplicaciones de mensajería como WhatsApp para crear un chatbot de IA funcional.
Además, ejecutarlo localmente en un servidor privado como en un VPS de Hostinger te proporciona un mayor nivel de control sobre tus datos. Esto hace que la integración sea adecuada para automatizar tareas relacionadas con información confidencial, como resumir documentos internos o crear un chatbot interno.
Vamos a explorar en detalle cómo conectar Ollama con n8n y crear un chatbot basado en esta integración. También explicaremos casos de uso populares para esta integración y ampliaremos sus capacidades utilizando los nodos LangChain.
Requisitos previos
Para integrar n8n con Ollama, debes cumplir los siguientes requisitos:
- Ollama debe estar instalado localmente: asegúrate de haber instalado Ollama localmente en un servidor privado virtual (VPS). El host debe tener suficiente hardware para ejecutar los modelos de IA deseados, lo que puede requerir más de 8 GB de RAM.
- n8n debe estar configurado y accesible: instala n8n en un VPS y crea una cuenta. Debe configurarse en el mismo servidor que Ollama por razones de compatibilidad.
- Asegúrate de que los puertos necesarios están abiertos: comprueba que los puertos 11434 y 5678 de tu servidor están abiertos para garantizar el acceso a Ollama y n8n. Si los alojas en Hostinger VPS, comprueba los puertos y configúralos simplemente preguntando a nuestro asistente de IA Kodee.
- Conocimientos básicos de JSON: aprende a leer JSON porque los nodos n8n intercambian datos principalmente en este formato. Comprenderlo te ayudará a seleccionar los datos y a solucionar los errores con mayor eficacia.
¡Importante! Te recomendamos encarecidamente instalar tanto n8n como Ollama en el mismo contenedor Docker para un mejor aislamiento. Este es el método que hemos utilizado para probar este tutorial, por lo que está comprobado que funciona.
Si utilizas un VPS de Hostinger, puedes empezar instalando n8n u Ollama en un contenedor Docker simplemente seleccionando la plantilla de SO correspondiente: la aplicación se instalará en un contenedor por defecto. A continuación, tendrás que instalar la otra aplicación en el mismo contenedor.
Cómo configurar la integración de Ollama en n8n
Conectar Ollama con n8n implica añadir el nodo necesario y configurar varios parámetros. En esta sección, explicaremos los pasos en detalle, incluyendo cómo probar la funcionalidad de la integración.
1. Añade el nodo Ollama Chat Model
Agregar el nodo Ollama Chat Model permite a n8n conectarse con grandes modelos lingüísticos (LLM) en la plataforma de IA a través de un agente conversacional.
n8n ofrece dos nodos Ollama: Modelo Ollama y Modelo Ollama Chat.
El Modelo de Chat de Ollama está diseñado específicamente para conversación y tiene incorporado un nodo de Cadena LLM Básica que reenvía su mensaje al modelo elegido. Mientras tanto, el nodo Modelo de Ollama es adecuado para tareas más generales con otros nodos de la cadena. Hablaremos sobre esto más a fondo en la sección LangChain.
En este tutorial, utilizaremos el nodo Modelo de Chat de Ollama, ya que es más fácil de utilizar e integrar con un flujo de trabajo más completo. Aquí te explicamos cómo añadirlo a n8n:
- Accede a tu instancia n8n. Deberías poder abrirlo en un navegador web utilizando el nombre de host o la dirección IP de tu VPS, dependiendo de tu configuración.
- Accede a tu cuenta n8n.
- Crea un nuevo flujo de trabajo haciendo clic en el botón situado en la parte superior derecha de la página principal de tu n8n.
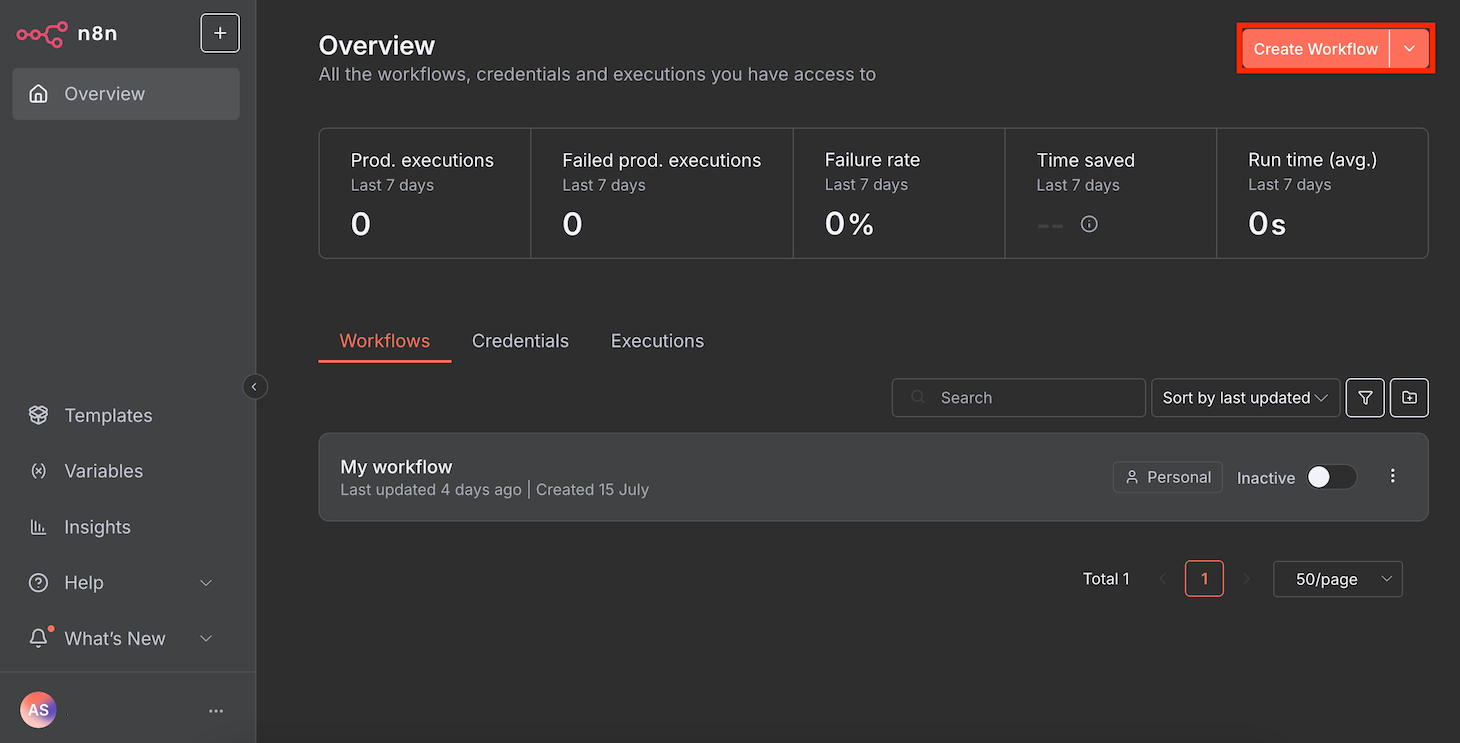
- Haz clic en el icono del signo más y busca Ollama Chat Model.
- Añade el nodo haciendo clic en él.
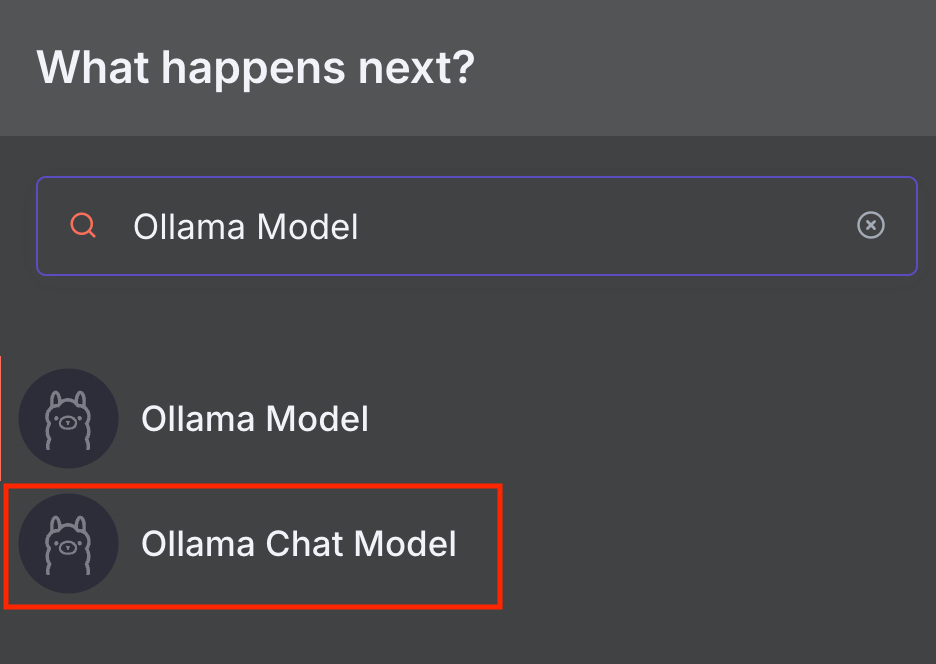
Aparecerá la ventana de configuración del nodo. Pasemos al siguiente paso para configurarlo.
2. Elige tu modelo y la configuración del tiempo de ejecución
Antes de elegir un modelo de IA y configurar sus parámetros de ejecución, conecta n8n con tu instancia de Ollama autoalojada. Aquí te explicamos cómo hacerlo:
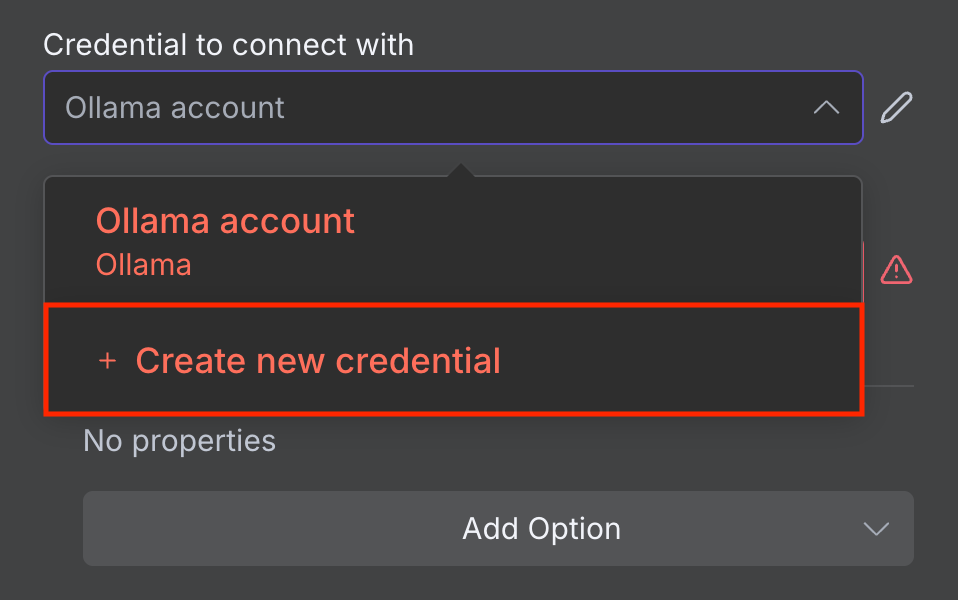
- En la ventana de configuración del nodo, despliega el menú desplegable Credencial para conectarse con.
- Selecciona Crear nueva credencial.
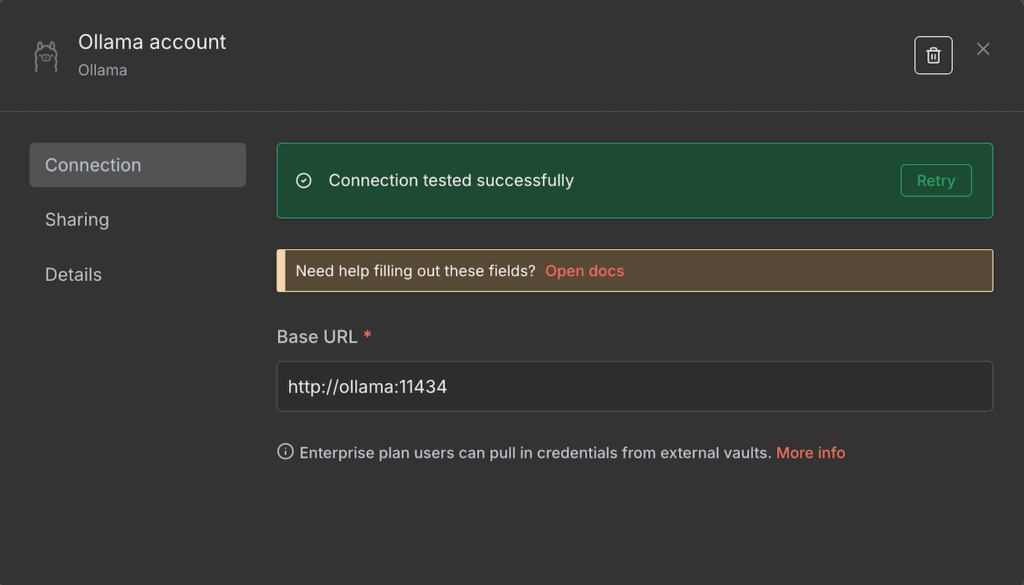
- Introduce la URL base de tu instancia de Ollama. Dependiendo de tu entorno de alojamiento, puede ser localhost o el nombre de tu contenedor Docker Ollama.
- Pulsa Guardar.
Si la conexión se realiza correctamente, verás un mensaje de confirmación. De lo contrario, asegúrate de que la dirección es correcta y de que tu instancia de Ollama está en funcionamiento.
Una vez conectado, puedes elegir el LLM que deseas utilizar en tu nodo modelo de Ollama. Para ello, basta con desplegar el menú desplegable Modelo y seleccionar uno de la lista. Si está en gris, refrescar el n8n resolverá el problema.
Ten en cuenta que n8n actualmente sólo es compatible con modelos más antiguos como Llama 3 y DeepSeek R1. Si el menú Modelo muestra un error y una lista vacía, lo más probable es que se deba a que tu Ollama sólo tiene modelos incompatibles.
Para solucionarlo, basta con descargar otros modelos de Ollama. En Ollama CLI, haz esto ejecutando el siguiente comando en tu entorno Ollama:
ollama run nombre-modelo
También puedes utilizar un modelo con ajustes de funcionamiento personalizados, como una temperatura más alta. He aquí cómo crear uno en Ollama CLI:
- Accede a tu instalación Ollama. Si utilizas Docker, usa el siguiente comando con ollama siendo el nombre real de tu contenedor:
docker exec -it ollama bash
- Crea un nuevo archivo de modelo que defina la configuración de tiempo de ejecución de tu modelo. Por ejemplo, fijaremos la temperatura de nuestro modelo Llama 3 en 0,7:
echo "FROM llama3" > Modelfile
echo "PARAMETER temperatura 0.7" >> Modelfile
- Ejecuta el siguiente comando para aplicar la configuración del archivo de modelo al modelo Llama 3 base, creando un LLM personalizado llamado llama3-temp07:
ollama create llama3-temp07 -f Modelfile
Una vez que hayas completado estos pasos, n8n debería leer tu nuevo modelo Llama 3 con la temperatura personalizada 0.7.
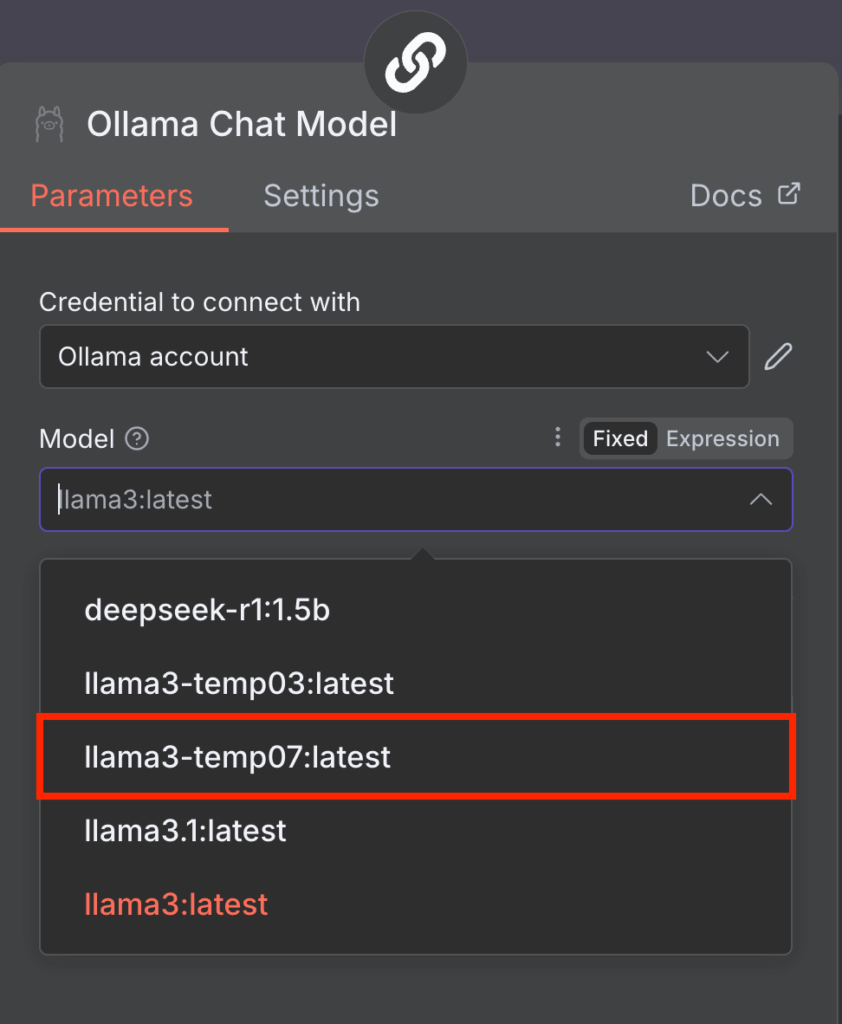
Gestión de Ollama GUI
Si utilizas Ollama GUI, consulta nuestro tutorial para aprender más sobre su interfaz y cómo gestionar tus modelos.
3. Configura las opciones de aviso
La configuración de los parámetros de aviso te permite personalizar el modo en que el nodo Cadena LLM Básica modifica tu entrada antes de pasarla a Ollama para su procesamiento. Aunque puedes utilizar la configuración predeterminada, deberías cambiarla en función de tus tareas.
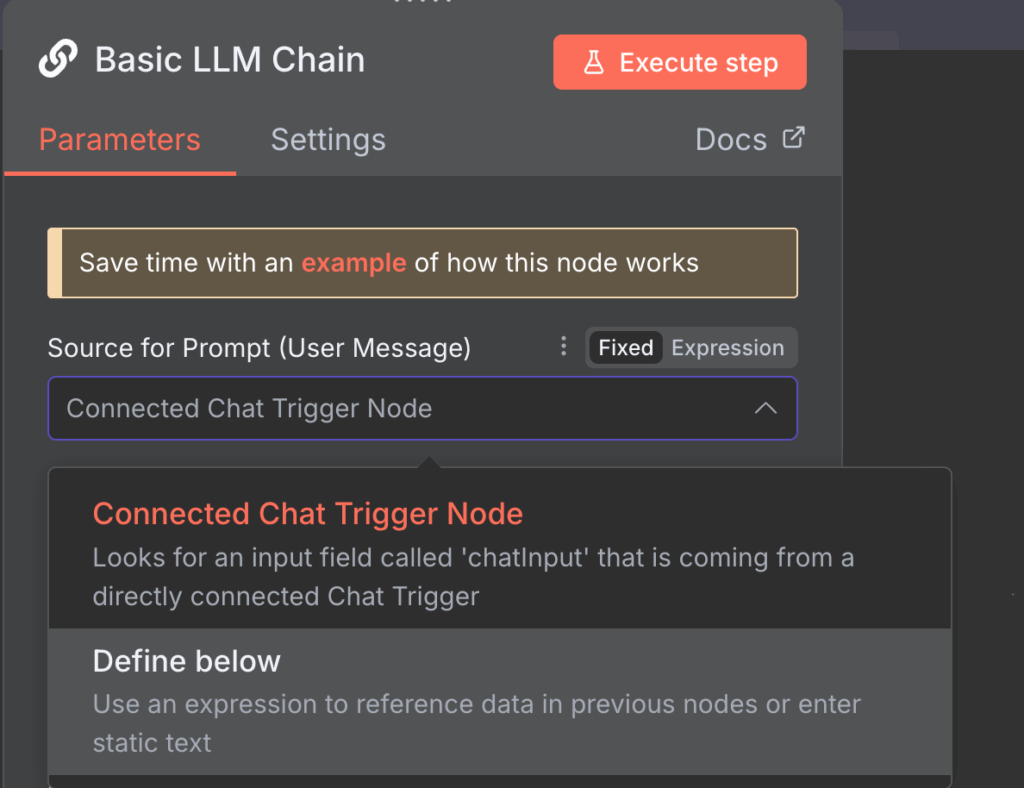
A continuación dos formas de modificar la configuración de los avisos del nodo de cadena LLM y sus casos de uso de ejemplo.
Nodo de activación del chat conectado
La opción del nodo disparador Chat Conectado utiliza los mensajes del nodo Chat por defecto como entrada para Ollama. Es el modo elegido por defecto y pasa los mensajes tal cual.
Sin embargo, puedes incluir avisos adicionales junto con los mensajes para modificar la salida de Ollama. Para ello, haz clic en el botón Añadir aviso en la configuración Mensajes de chat (si se utiliza un modelo de chat) y elige entre tres opciones de aviso adicionales:
- AI: introduce un ejemplo de la respuesta esperada en el campo Mensaje. El modelo de IA intentará responder de la misma manera que el texto proporcionado.
- Sistema: escribe un mensaje que guíe las respuestas del modelo. Por ejemplo, puedes definir el tono que utilizará la IA o las palabras que debe evitar al responder.
- Usuario: añade una muestra de la entrada del usuario para la IA, como un mensaje, una URL o una imagen. Dar a la IA una muestra de lo que puede esperar de los usuarios le permitirá ofrecer respuestas más coherentes.
Definir a continuación
La opción Definir a continuación es adecuada si deseas introducir un mensaje preescrito reutilizable. También es ideal para enviar datos dinámicos, ya que puede capturarlos mediante Expressions, una biblioteca JavaScript que manipula la entrada o selecciona un campo específico.
Por ejemplo, el nodo anterior obtiene datos sobre el uso de los recursos de tu VPS y deseas analizarlos utilizando IA. En este caso, la indicación sigue siendo la misma, pero las métricas de uso cambiarán continuamente.
Tu prompt podría parecerse a la siguiente, siendo {{ $json.metric }} el campo que contiene los datos dinámicos sobre el uso de los recursos de tu servidor:
El último uso de mi servidor es {{ $json.metric }}. Analiza estos datos y compáralos con el historial de uso anterior para comprobar si se trata de algo anormal.Ten en cuenta que aún puedes añadir indicaciones adicionales como en el modo anterior para dar más contexto a la IA.
4. Envia un aviso de prueba
El envío de un aviso de prueba verifica que tu modelo Ollama funciona correctamente al recibir entradas a través de n8n. La forma más sencilla de hacerlo es introduciendo un mensaje de muestra siguiendo estos pasos:
- Guarda tu flujo de trabajo haciendo clic en el botón situado en la parte superior derecha del lienzo.
- Pasa el ratón por encima del nodo Activador del chat y haz clic en Abrir chat.
- En la interfaz de chat, envía un mensaje de prueba.
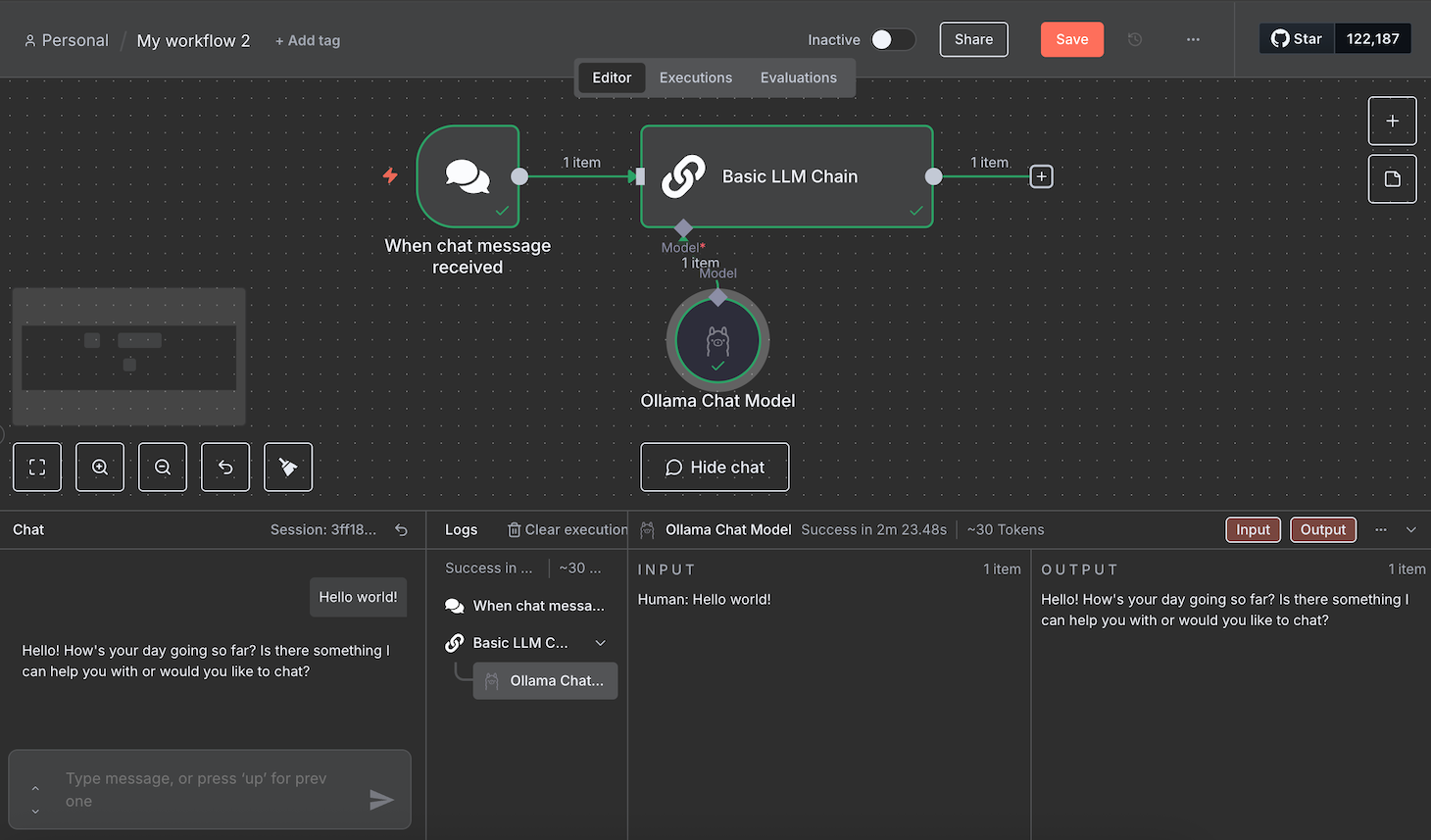
Esperq hasta que el flujo de trabajo termine de procesar tu mensaje. Durante nuestras pruebas, el flujo de trabajo se atascó unas cuantas veces. Si encuentras el mismo problema, simplemente recarga n8n y envía un nuevo mensaje.
Si la prueba se realiza correctamente, todos los nodos se volverán verdes. Puedes leer la entrada y salida JSON de cada nodo haciendo doble clic en él y comprobando los paneles a ambos lados de la ventana de configuración.
Cómo crear un flujo de trabajo de chatbot utilizando Ollama y n8n
La integración de Ollama en n8n te permite automatizar varias tareas con LLM, incluida la creación de un flujo de trabajo impulsado por IA en n8n que responda a las consultas de los usuarios, como un chatbot. En esta sección se analizan los pasos necesarios para elaborar uno.
Si deseas crear un sistema de automatización para otras tareas, consulta nuestros ejemplos de flujos de trabajo n8n para inspirarte.
1. Añade un nodo desencadenante
El nodo desencadenante en n8n define el evento que iniciará tu flujo de trabajo. Entre varias opciones, éstas son las más comunes para crear un chatbot:
Activador de chat
Por defecto, el nodo modelo de chat de Ollama utiliza Chat message como disparador, que inicia tu flujo de trabajo al recibir un mensaje.
Este nodo Chat por defecto es perfecto para desarrollar un chatbot. Para que funcione, basta con poner la interfaz de chat a disposición del público.
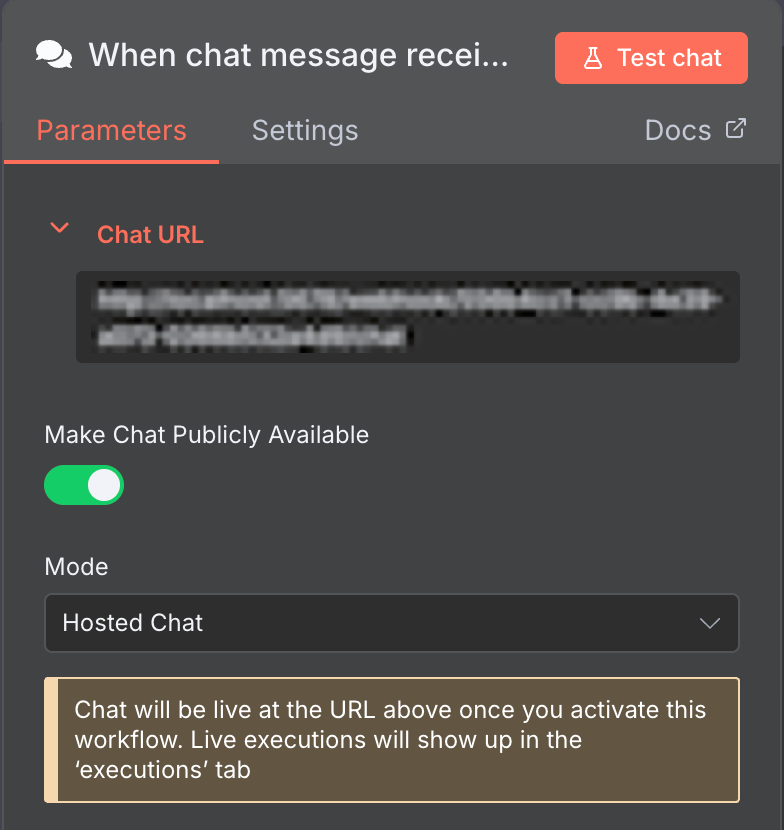
Para ello, abre el nodo Chat y haz clic en el botón Hacer público el chat. A continuación, puedes incrustar esta funcionalidad de chat en tu chatbot personalizado con una interfaz de usuario.
Nodos de activación de aplicaciones de mensajería
n8n cuenta con nodos de activación que toman datos de aplicaciones de mensajería populares como Telegram y WhatsApp. Son adecuados si quieres crear un bot para este tipo de aplicaciones.
Configurar estos nodos es bastante complicado porque necesitas una cuenta de desarrollador y claves de autenticación para conectarte a sus API. Consulta su documentación para saber más sobre cómo configurarlos.
Activador Webhook
El disparador Webhook inicia tu flujo de trabajo cuando tu URL de punto final recibe una solicitud HTTP. Esto es ideal si quieres iniciar tu chatbot utilizando eventos distintos al envío de un mensaje, como un clic.
En los siguientes pasos, utilizaremos este nodo para iniciar nuestro flujo de trabajo cada vez que un chatbot de Discord reciba un mensaje.
¡Importante! Si la URL de tu webhook comienza con localhost, cámbiala por el dominio, nombre de host o dirección IP de tu VPS. Puedes hacerlo modificando la variable de entorno WEBHOOK_URL de n8n dentro de tu archivo de configuración.
2. Conecta el nodo Ollama
La conexión del nodo Ollama permite que el nodo de activación reenvíe la entrada del usuario para su procesamiento.
El nodo Ollama Chat Model no se conecta directamente a los nodos de activación y sólo se integra con un nodo de IA. El predeterminado es el nodo Cadena LLM Básico, pero también puede utilizar otros nodos Cadena para un procesamiento más complejo.
Algunos nodos de la Cadena admiten herramientas adicionales para procesar tus datos. Por ejemplo, el nodo Agente IA permite añadir un analizador sintáctico para reformatear la salida o incluir una memoria para almacenar las respuestas anteriores.
Para un chatbot que no requiera un procesamiento de datos complejo, como nuestro chatbot Discord, la cadena LLM básica es suficiente.
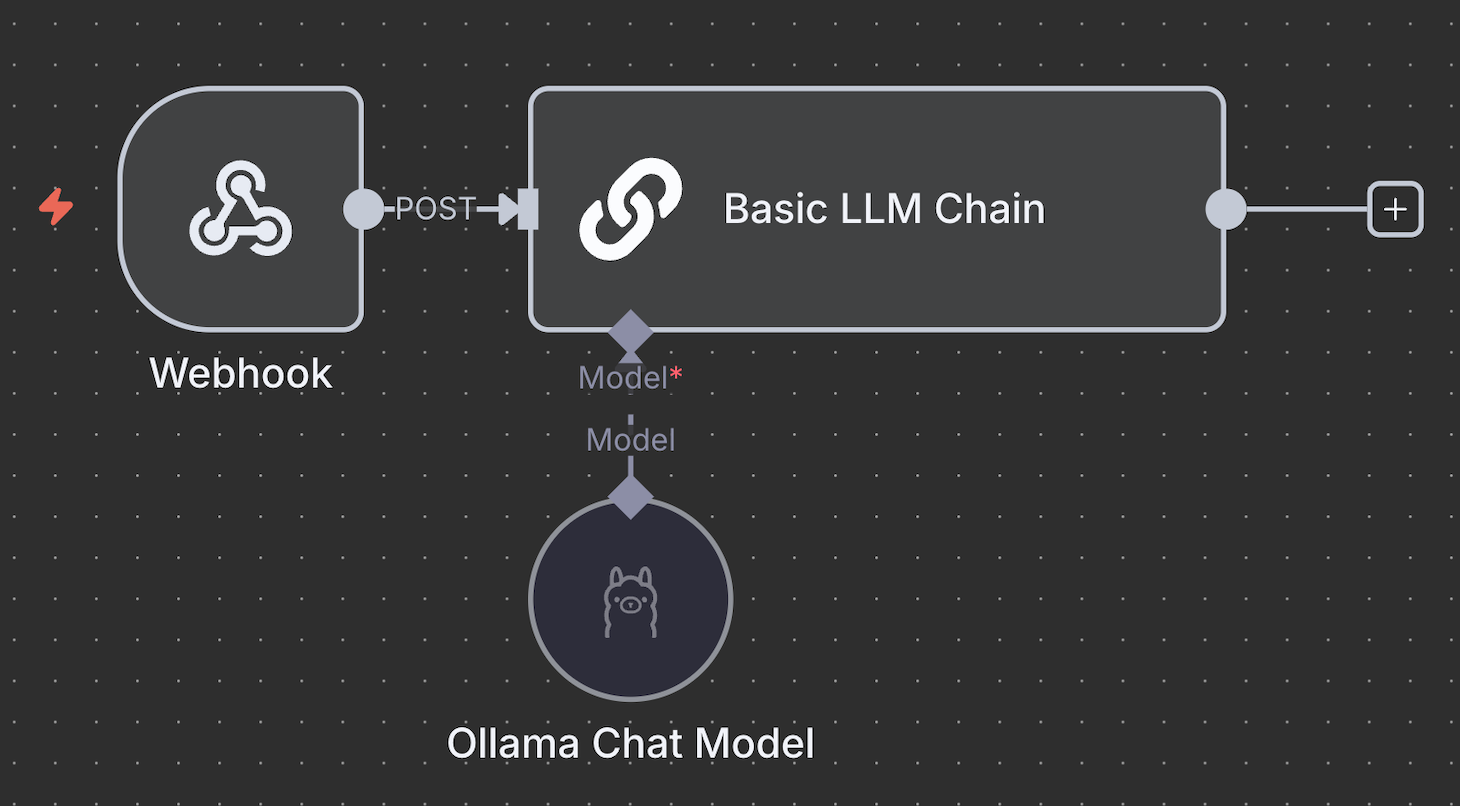
Por lo tanto, conecta el nodo de activación con el nodo de la cadena LLM básica y define cómo pasar la entrada. Utiliza Fixed para pasar el mensaje como prompt. Mientras tanto, selecciona Expresión para utilizar datos dinámicos o manipular la entrada antes de reenviarla a Ollama.
Por ejemplo, utilizamos la siguiente Expresión para elegir como entrada el campo JSON body.content , que cambia en función de los mensajes de Discord de los usuarios:
{{ $json.body.content }}3. Emisión de la respuesta
La salida de la respuesta del nodo Agente IA o Cadena LLM Básica hace posible que los usuarios vean la respuesta de tu bot. En este punto, sólo puedes leer la salida de la interfaz de chat o el panel de salida del nodo.
Para enviar la respuesta, utiliza el mismo nodo que tu activador. Por ejemplo, si estás desarrollando un chatbot de WhatsApp, conecta el nodo de envío de mensajes de WhatsApp.
Si utilizas el activador de chat predeterminado, puedes utilizar el nodo Webhook para reenviar el mensaje a tu bot o interfaz de chatbot con código personalizado.
Dado que el flujo de trabajo de nuestro bot Discord utiliza el disparador Webhook , también podemos utilizar el nodo Webhook para la salida. Alternativamente, podemos utilizar el mismo bot para enviar la respuesta conectando el nodo Discord Send a Message e integrándolo con nuestro chatbot. El flujo de trabajo completado tendrá el siguiente aspecto:
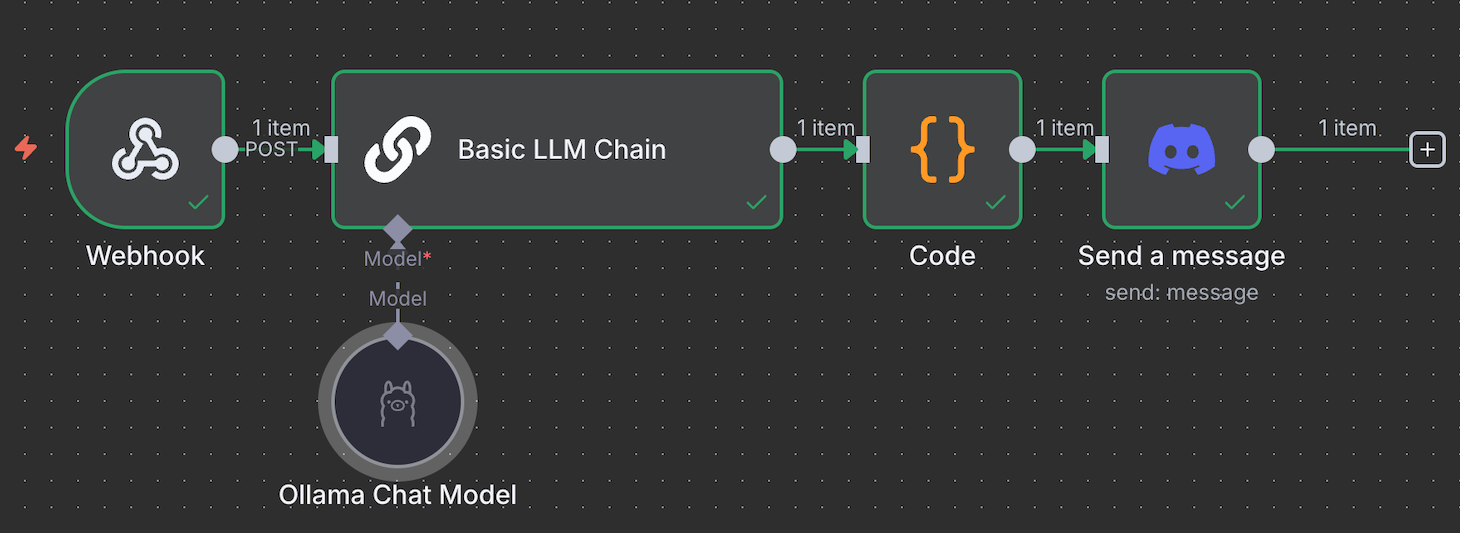
¿No estás seguro de cómo crear un flujo de trabajo completo?
n8n ofrece varios flujos de trabajo listos para usar que puedes importar fácilmente a tu lienzo. Esto te permite crear un sistema de automatización basado en IA sin necesidad de desarrollar el flujo de trabajo desde cero. Echa un vistazo a nuestro tutorial sobre las mejores plantillas n8n para descubrir flujos de trabajo curados y listos para usar con diversos fines.
Mejores casos de uso para la integración de n8n Ollama
Siendo una de las herramientas de automatización de IA más potentes, la integración de n8n con los LLM personalizables de Ollama te permite automatizar una amplia gama de tareas.
He aquí ejemplos de tareas que puedes automatizar con n8n y la IA:
- Flujo de trabajo automatizado de atención al cliente: utiliza los LLM de Ollama para generar respuestas a las consultas de los clientes, resumir tickets o enrutar incidencias en plataformas como Zendesk e Intercom, todo ello a través de n8n.
- Redacción de correos electrónicos en función del contexto: escribe automáticamente correos electrónicos para diferentes contextos o tareas utilizando Ollama. Por ejemplo, puedes redactar un mensaje para incorporar a un nuevo cliente potencial, recordar a los clientes el vencimiento de la suscripción y anunciar actualizaciones de productos mediante distintos eventos.
- Asistente de la base de conocimientos interna: usa n8n para consultar documentación interna, como Notion, Confluence o Airtable, e introduce los datos en Ollama para generar respuestas inteligentes o resúmenes para las consultas del equipo interno.
- Extracción y resumen de datos: utiliza n8n para ver documentos de texto entrantes, extraer su texto y extraer información clave con Ollama: útil para resumir informes, facturas o documentos legales.
- Producción automatizada de contenidos: genera contenidos con n8n y Ollama creando un flujo de trabajo que automatice el proceso de búsqueda de palabras clave, redacción y edición.
- Chatbots seguros para uso interno: crea chatbots internos que trabajen con datos internos confidenciales, donde n8n se encarga de la orquestación y Ollama ejecuta el LLM completamente offline por seguridad y privacidad.
¿Por qué deberías alojar tus flujos de trabajo n8n-Ollama con Hostinger?
Alojar tus flujos de trabajo n8n-Ollama con Hostinger aporta varias ventajas con respecto a utilizar una máquina personal o el plan de alojamiento oficial. Estas son algunas de sus ventajas:
- Mayor control: el servicio de alojamiento VPS n8n de Hostinger proporciona a los usuarios acceso root completo a la configuración y los datos de tu servidor. Esto te permite configurar tus entornos de alojamiento n8n y Ollama según tus preferencias específicas.
- Mayor privacidad: puesto que alojarás n8n y Ollama en un servidor que controla totalmente, tendrás libertad para ajustar los límites de acceso y la configuración de seguridad.
- Escalabilidad: los planes VPS de Hostinger son fácilmente actualizables sin tiempo de inactividad y ofrecen la plantilla de modo de cola n8n que te permite descargar tu tarea a múltiples trabajadores.
- Configuración simplificada: nuestras plantillas VPS te permiten instalar n8n u Ollama en un solo clic, haciendo que el proceso sea más eficiente.
- Fácil gestión: gestionar un VPS de Hostinger es fácil con el intuitivo panel de control hPanel o el terminal de navegador integrado. Los principiantes también pueden pedir a nuestro asistente de IA, Kodee, que realice tareas de administración del sistema a través del chat.

Uso del nodo LM Ollama de LangChain en n8n
LangChain es un marco que facilita la integración de los LLM en las aplicaciones. En n8n, esta implementación implica conectar diferentes nodos de herramientas y modelos de IA para lograr capacidades de procesamiento particulares.
En n8n, la función LangChain utiliza nodos Cluster: un grupo de nodos interconectados que trabajan juntos para proporcionar funcionalidad en tu flujo de trabajo.
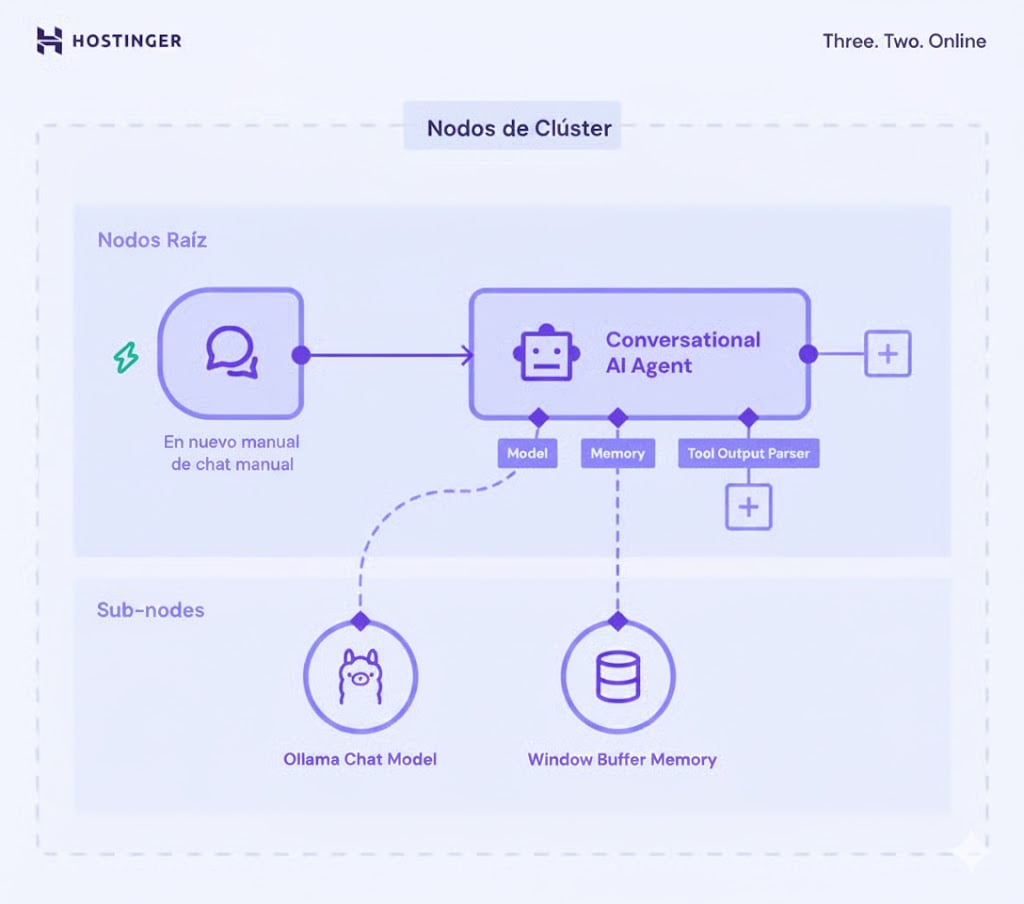
Los nodos del clúster constan de dos partes: los nodos raíz , que definen la funcionalidad principal, y los subnodos, que añaden la capacidad LLM o características adicionales.
La parte más importante de la implementación de LangChain en n8n es la Cadena dentro de los nodos raíz. Reúne y configura la lógica de distintos componentes de la IA, como el modelo Ollama y el nodo analizador sintáctico, para crear un sistema cohesionado.
Aquí están las Cadenas en n8n y sus funciones:
- Cadena básica LLM: permite definir el mensaje que utilizará el modelo de IA y un analizador sintáctico opcional para reformatear la respuesta.
- Cadena de preguntas y respuestas de recuperación: permite recuperar datos procesados por la IA utilizando almacenes vectoriales, bases de datos diseñadas para almacenar información en formato numérico.
- Cadena de resumen: resume el contenido de varios documentos o entradas.
- Análisis del sentimiento: analiza el sentimiento del texto de entrada y lo clasifica en categorías como positivo, neutro y negativo.
- Clasificador de texto: clasifica los datos de entrada en diferentes categorías creadas por el usuario en función de los criterios y parámetros especificados.
Al crear un flujo de trabajo en n8n, también puedes encontrar Agentes: subconjuntos de Cadenas con capacidad para tomar decisiones. Mientras que las Cadenas operan basándose en un conjunto de reglas predeterminadas, el Agente utiliza el LLM conectado para determinar las siguientes acciones a realizar.
¿Qué sigue después de conectar n8n con Ollama?
Como las tendencias de automatización siguen evolucionando, implantar un sistema automático de procesamiento de datos te ayudará a mantenerte por delante de la competencia. Junto con la IA, puedes crear un sistema que lleve el desarrollo y la gestión de tus proyectos al siguiente nivel.
La integración de Ollama en el flujo de trabajo del n8n aporta una automatización basada en IA que va más allá de las capacidades del nodo incorporado y la compatibilidad de Ollama con varios LLM te permite elegir y adaptar diferentes modelos de IA para que se ajusten mejor a tus necesidades.
Comprender cómo conectar Ollama a n8n es sólo el primer paso para implantar la automatización basada en IA en tu proyecto. Dado el gran número de casos de uso posibles, el siguiente paso es experimentar y desarrollar el flujo de trabajo que mejor se adapte a tu proyecto.
Si es la primera vez que trabajas con n8n u Ollama, Hostinger es el lugar ideal para empezar. Además de planes VPS repletos de funciones, disponemos de un completo catálogo de tutoriales sobre n8n que te ayudarán a iniciar tu viaje de automatización.
Todo el contenido de los tutoriales en este sitio web está sujeto a los rigurosos estándares y valores editoriales de Hostinger.

Diego es comunicador social, especialista en publicidad digital que trabaja constantemente en mejorar sus conocimientos de marketing digital, enfocándose en contenido y SEO. Idiomas, series, libros y cursos en internet son sus hobbies principales, además de los deportes. Este es su perfil de LinkedIn.

Comentarios
0 responses