Cuánto cuesta Hermes Agent: guía de precios y costes
Jun 16, 2026
/
Virginija J.
/
10 min Leer
¿Cuánto cuesta Hermes Agent? En general, el coste va de 5 a 80 USD al mes, según el modelo de lenguaje que uses para el razonamiento.
El software es gratuito bajo la licencia MIT, por lo que el coste viene de dos fuentes: el hosting VPS para ejecutar el agente y las llamadas a la API del LLM en cada paso de razonamiento.
El costo total se divide en cuatro partes:
- Hosting VPS: entre 4 y 25 USD al mes por el servidor que ejecuta el agente.
- Llamadas a la API del LLM: entre 2 y 60 USD al mes, según el modelo que se use para el razonamiento.
- Suscripción opcional a Nous Portal: 0 USD con el plan gratuito o 20 USD al mes con el plan Plus, que incluye herramientas integradas.
- Servicios de herramientas opcionales: búsqueda web, generación de imágenes, automatización del navegador y conversión de texto a voz cuando no están incluidos.
En comparación con ChatGPT Plus, que cuesta 20 USD al mes, o Claude Pro, que cuesta 17 USD al mes, una configuración económica de Hermes cuesta menos de la mitad. Una configuración prémium puede costar entre dos y cuatro veces más, pero no tiene límites de uso.
Que la configuración te compense o no depende del uso que le des. A partir de unos pocos cientos de sesiones de agente al mes, la rentabilidad mejora. Por debajo de ese umbral, una suscripción fija para consumidores es más económica y sencilla.
Hosting VPS
El hosting VPS es el costo mensual fijo del servidor que ejecuta Hermes Agent. El proceso del agente es ligero, por lo que una instancia con 1 GB de RAM y 1 vCPU cubre la mayoría de las configuraciones con LLM en la nube.
Recomendaciones de tamaño según la carga de trabajo:
- Mínimo: 1 GB de RAM y 1 vCPU, suficiente cuando el razonamiento lo gestiona un LLM en la nube.
- Automatización del navegador: entre 2 y 4 GB de RAM.
- Ollama local, modelos de 7B a 13B: mínimo 4 GB de RAM.
- Modelos locales de 70B. GPU sin servidor con facturación por segundo, alrededor de 40 a 80 USD al mes para un uso ligero. Una instancia siempre activa cuesta mucho más.
Entre los proveedores más habituales están Hostinger, con planes desde AR$ 11699.00/mes, Hetzner, DigitalOcean y opciones serverless como Modal, que se suspenden cuando no están en uso. La mayoría de las configuraciones cuestan entre 4 y 25 USD al mes.
Hostinger VPS con configuración de Docker en 1 clic cubre el rango de 1 a 4 GB de RAM que Hermes Agent necesita para configuraciones ligeras y de automatización del navegador.
Un error habitual al hacer tu presupuesto es creer que el precio inicial del VPS se mantiene. Las tarifas de renovación suelen ser más altas que las promocionales, así que planifica tu presupuesto según el precio de renovación y no según el precio de lanzamiento. Un plan que empieza en 4 USD al mes puede renovarse por entre 10 y 12 USD al mes.
La facturación por horas es otra trampa. Una instancia a 0,24 USD por hora cuesta unos 173 USD al mes si la dejas encendida de forma continua. Para los despliegues permanentes de Hermes, una tarifa mensual fija es mejor que la facturación por hora.
Llamadas a la API del LLM (inferencia)
Las llamadas a la API del LLM son el coste variable de cada solicitud que Hermes Agent. envía al modelo. Los proveedores cobran en dólares por cada millón de tokens de entrada y salida, y el ciclo de razonamiento del agente puede generar decenas de solicitudes en una sola sesión.
Los proveedores cobran por separado los tokens que envías (entrada) y los tokens que el modelo genera como respuesta (salida). Estos son los rangos de precios aproximados a mediados de 2026:
- Presupuesto: DeepSeek V4 Flash cuesta 0,14 USD por cada millón de tokens enviados y 0,28 USD por cada millón de tokens generados. GPT-5.4 Nano cuesta 0,20 USD por cada millón de tokens enviados y 1,25 USD por cada millón de tokens generados. Gemini 3.1 Flash-Lite cuesta 0,25 USD por cada millón de tokens enviados y 1,50 USD por cada millón de tokens generados.
- Gama media: Claude Haiku 4.5 cuesta 1,00 USD por cada millón de tokens enviados y 5,00 USD por cada millón de tokens generados.
- Premium: Claude Sonnet 4.6 cuesta 3,00 USD por cada millón de tokens enviados y 15,00 USD por cada millón de tokens generados. Claude Opus 4.8 cuesta 5,00 USD por cada millón de tokens enviados y 25,00 USD por cada millón de tokens generados.
- Agregador: OpenRouter ofrece más de 300 modelos con una sola clave de API y un pequeño recargo.
Hay dos factores que pueden afectar a la factura más allá del precio base. El primero es la tarificación por aciertos de caché. Por ejemplo, por cada millón de tokens de entrada, DeepSeek V4 Flash cobra 0,14 USD cuando no hay aciertos de caché y 0,0028 USD cuando sí los hay, lo que supone un descuento del 98%.
El precio con caché es más importante para Hermes que para los chatbots, porque el agente vuelve a enviar una carga fija de definiciones de herramientas en cada solicitud. Eso hace que el descuento se acumule a lo largo de una misma sesión.
El segundo mecanismo es el resumidor de compresión. Cuando una conversación supera el umbral predeterminado del 50% del contexto, Hermes envía una llamada adicional al LLM para comprimir el historial, lo que añade más tokens a la factura.
La forma en que hablas con el agente también influye en la factura. Hermes envía entre 6.000 y 8.000 tokens de definiciones de herramientas a través de la CLI y entre 15.000 y 20.000 tokens a través de pasarelas de mensajería como Telegram o Discord en cada solicitud.
Cambiar de una puerta de enlace a la CLI reduce la sobrecarga por solicitud entre 2 y 3 veces.
Con una configuración económica con DeepSeek V4 Flash, un día de uso intensivo de agentes de varios pasos cuesta solo unos pocos dólares en tokens. La misma carga de trabajo con Claude Opus 4.8 cuesta unas 30 veces más, ya que Opus cuesta 5 USD / 25 USD por millón de tokens, frente a los 0,14 USD / 0,28 USD de Flash.
Suscripción a Nous Portal (opcional)

Nous Portal es una suscripción opcional de Nous Research. Los planes de pago reúnen más de 300 modelos y cuatro herramientas principales, búsqueda web, generación de imágenes, conversión de texto a voz y automatización del navegador, en una sola factura.
Se lanzó el 27 de abril de 2026 y se conecta mediante una única configuración de OAuth con hermes setup –portal. Los niveles actuales son:
- Gratis: 0 USD al mes, con créditos de pago por uso a partir de 10 USD que se convierten uno a uno. Es decir, 10 USD equivalen a 10 USD de uso. Es suficiente para una evaluación rápida, pero no para cargas de trabajo reales..
- Plus: 20 USD al mes, con 22 USD de crédito de uso mensual.
- Super: 100 USD al mes, con 110 USD de crédito de uso mensual.
- Ultra: 200 USD al mes, con 220 USD de crédito de uso mensual y los límites de uso más altos de todos los planes.
Cada plan de pago incluye el crédito mensual indicado en cada ciclo de facturación. El plan gratuito es la excepción: no incluye crédito integrado ni Tool Gateway, por lo que está más pensado para una evaluación rápida que para un uso continuado.
Si ya estás pagando por separado herramientas de búsqueda web, generación de imágenes y automatización del navegador, el plan Plus de 20 USD suele ser más económico que contratar cada herramienta por separado. Nous Portal no es obligatorio: OpenRouter, las claves API directas de Anthropic u OpenAI y Ollama local también funcionan sin él.
Servicios de herramientas (opcional)
Los servicios de herramientas son API externas que el agente Hermes llama cuando busca en la web, ejecuta un navegador, genera imágenes o convierte texto en voz. Si no los canalizas a través de Nous Portal, cada servicio cobra su propia tarifa según el uso.
Proveedores habituales por categoría:
- Búsqueda web: Firecrawl, Tavily, Exa.
- Automatización del navegador: Browser Use.
- Generación de imágenes: FAL.
- Texto a voz: ElevenLabs, OpenAI audio.
- Entorno aislado para ejecución de código: Modal.
Si les das un uso ligero, estos servicios solo añaden unos pocos dólares al mes. Si usas las herramientas con más intensidad, es cuando el nivel Nous Portal Plus incluido empieza a compensar.
La automatización del navegador es la herramienta que más CPU consume y a menudo exige pasar a un plan superior a un VPS con 1 GB de RAM.
Opción con hardware local (alternativa)
La opción de hardware local elimina el coste mensual de inferencia, pero requiere tener el hardware necesario y aceptar una menor calidad de razonamiento. Hermes Agent se conecta a un modelo que se ejecuta localmente mediante la API estándar compatible con OpenAI.
Requisitos de hardware según el tamaño del modelo:
- Modelos de 7B a 13B: mínimo 4 GB de RAM, o entre 6 to 8 GB VRAM para aceleración con GPU.
- Modelos de 27B: Apple Silicon con memoria unificada. Por ejemplo, un M3 Pro con 36 GB puede ejecutar un modelo de 27B con contexto de 64K.
- Modelos de 70B: GPU cloud serverless con facturación por segundo, alrededor de 40 a 80 USD al mes para un uso ligero. Una instancia siempre activa cuesta mucho más.
Entre las opciones iniciales más sensatas están Qwen 3 8B si buscas calidad con un presupuesto ajustado y Llama 4 Maverick si necesitas una mayor capacidad de razonamiento.
La mayoría de los portátiles de quienes desarrollan software pueden ejecutar Qwen 3 8B. El paso de compresión de Hermes Agent necesita un modelo auxiliar con una ventana de contexto de al menos 64K, así que no puedes reutilizar una configuración predeterminada de 4K de Ollama tal cual.
Los modelos locales quedan por detrás de Claude Sonnet en razonamientos complejos de varios pasos. Resuelven bien las tareas rutinarias, pero no aquellas en las que una sola inferencia errónea puede desencadenar una ejecución fallida.
Cómo reducir el costo de Hermes Agent
La forma más rápida de reducir tu factura de Hermes Agent es revisar tu configuración, no cambiar de modelo. Ajustar las herramientas, el modelo de compresión y los límites de gasto del proveedor puede reducir los costes sin cambiar tu LLM principal.
La configuración predeterminada del agente da por hecho que quieres todas las herramientas activadas y que resumamos las conversaciones de forma agresiva. Esas opciones predeterminadas pueden aumentar tus costos.
Cuatro tácticas, por orden de impacto:
- Pásate a un modelo compatible con caché: DeepSeek V4 Flash ofrece un 98% de descuento por aciertos en caché, que se acumula a lo largo de sesiones largas con agentes. En cargas de trabajo que dependen mucho de la caché, las mismas tareas pueden costar la mitad o menos que con Claude Opus.
- Elimina las herramientas que no uses: cambiar de una pasarela de mensajería a la CLI reduce entre 2 y 3 veces la sobrecarga de tokens por solicitud. Desactivar las herramientas que no utilizas puede reducirla aún más.
- Usa un modelo de compresión más económico: Hermes envía una solicitud de resumen por separado cuando una conversación supera el umbral predeterminado del 50% del contexto. Dirigir esa solicitud a un modelo económico como DeepSeek V4 Flash o GPT-5.4 Nano ayuda a reducir un coste oculto.
- Establece límites de gasto para los proveedores: OpenRouter, Anthropic y OpenAI ofrecen límites mensuales de gasto estrictos. Fija un límite ligeramente por encima de tu presupuesto objetivo para evitar que un bucle descontrolado del agente genere cargos inesperados.
Las dos sorpresas de facturación más habituales son la sobrecarga de definición de herramientas y el resumidor de compresión. Si tu factura sube de forma inesperada, primero revisa la pasarela que elegiste.
Pasarte de Telegram a la CLI suele ser la solución más rápida. Luego comprueba si tu modelo principal admite precios de caché. Pasarte a DeepSeek V4 Flash puede reducir en un 50% o más una factura dominada por Claude en cargas de trabajo con mucho uso de caché.
Comparativa de costes: Hermes Agent, ChatGPT Plus, Claude Pro y OpenClaw Cloud
En comparación con los planes de consumo de tarifa fija, una configuración económica de Hermes cuesta menos, mientras que una configuración prémium intercambia una factura mensual más alta por un uso ilimitado. La tabla de abajo compara los costos mensuales habituales de una sola persona dedicada al desarrollo según los precios públicos vigentes en junio de 2026.
Plan | Costo mensual | Tipo de costo | Ideal para |
Hermes Agent (budget) | 5–8 USD | Variable (hosting + tokens) | Desarrolladores en solitario con cargas de trabajo ligeras |
Hermes Agent (premium) | 40–80 USD | Variable | Flujos de trabajo con modelos de vanguardia sin límites de uso |
ChatGPT Plus | 20 USD | Suscripción fija | Chat para un solo usuario con uso limitado |
Claude Pro | 17 USD | Suscripción de tarifa fija | Usuarios de Anthropic con uso limitado |
OpenClaw Cloud | 59 USD | Servicio gestionado de tarifa plana | Equipos que quieren una infraestructura de agentes predecible |
Hermes Agent te conviene si quieres control total y tu carga de trabajo se mantiene por debajo de 1 millón de tokens al día. Si prefieres una factura mensual predecible y no necesitas flujos de trabajo autónomos con agentes, una suscripción fija para consumidores puede ser mejor opción.
OpenClaw Cloud es la única alternativa gestionada de esta comparación. Las diferencias entre Hermes Agent y OpenClaw se reducen al modelo de implementación y al costo total.
¿Hermes Agent es más barato que ChatGPT Plus?
Depende del modelo que uses. Una configuración económica de Hermes Agent en Hetzner con DeepSeek V4 Flash cuesta a partir de unos 5 USD al mes, muy por debajo de los 20 USD al mes de ChatGPT Plus. Una configuración premium con Claude Sonnet 4.6 cuesta más.
El punto de equilibrio depende de dos factores. El uso de tokens determina cuándo una configuración premium pasa a ser más cara que la suscripción fija de 20 USD, mientras que el volumen de sesiones determina si el tiempo que dedicas a configurar y mantener Hermes Agent compensa el ahorro.
Cuándo merece la pena el costo de Hermes Agent y cuándo no
El costo de Hermes Agent tiene sentido cuando lo usas de forma habitual y con flujos de trabajo intensivos, no solo para preguntas ocasionales. Los casos de uso de Hermes Agent que realmente compensan son los trabajos de varios pasos que activan muchas llamadas al modelo y en los que una configuración permanente puede justificar su coste.
Por debajo de unos pocos cientos de sesiones de agente al mes, las suscripciones de consumo con tarifa plana suelen salir más económicas porque sus cuotas fijas se reparten entre un uso que no tienes que gestionar directamente.
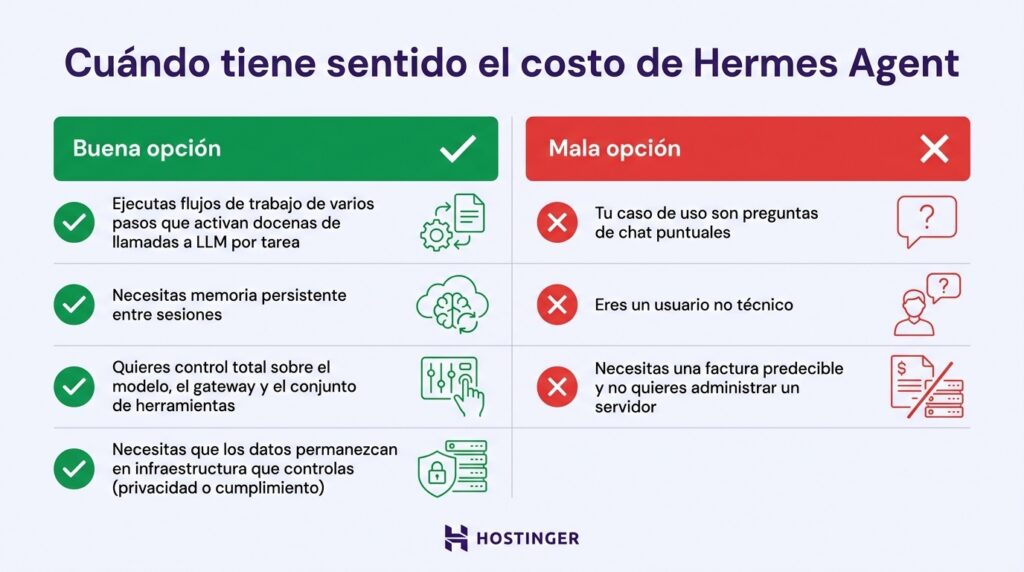
Es una buena opción cuando:
- Ejecutas flujos de trabajo de varios pasos que activan decenas de llamadas a modelos de lenguaje por cada tarea.
- Necesitas memoria persistente entre sesiones, algo que Hermes gestiona de forma nativa.
- Quieres tener un control total del modelo, la puerta de enlace y el conjunto de herramientas.
- Necesitas que los datos permanezcan en una infraestructura que tú controlas por motivos de privacidad o cumplimiento normativo.
No es una buena opción cuando:
- Tu caso de uso son preguntas puntuales de chat, no flujos de trabajo autónomos.
- Eres una persona sin conocimientos técnicos, ya que configurar Hermes Agent puede llevarte más tiempo del que te ahorra.
- Necesitas una factura predecible y no quieres gestionar un servidor.
Si tu caso de uso principal son preguntas puntuales, quédate con ChatGPT o Claude. Por encima de unos pocos cientos de sesiones al mes, el ahorro y el control pueden justificar la carga adicional.
Cómo calcular el presupuesto de tu agente Hermes
Para calcular el presupuesto de tu agente Hermes, elige primero el modelo y después el proveedor. Esa sola decisión puede multiplicar por 30 tu coste mensual, mucho más que cualquier elección de hosting.
Un LLM económico que funciona en un servidor de 4 USD al mes y un LLM de última generación que funciona en ese mismo servidor pueden generar facturas que difieren en aproximadamente 30 veces. Por eso, tu primera decisión de planificación debería centrarse en el modelo que tu carga de trabajo realmente necesita.
Una vez que hayas elegido un nivel de modelo, observa dos métricas en el panel de tu proveedor. El primero es el porcentaje de aciertos de la caché. En un modelo que aprovecha bien la caché, como DeepSeek V4 Flash, las definiciones de herramientas repetidas se almacenan en caché y pueden optar a un precio con descuento, así que la proporción debería aumentar con el tiempo.
La segunda es la cantidad de tokens por solicitud. La configuración de una CLI suele añadir entre 6.000 y 8.000 tokens de sobrecarga por solicitud. Si esa cifra sube a 15.000 o 20.000 tokens, puede que hayas cambiado a una pasarela de mensajería como Telegram o Discord, o que hayas añadido una herramienta que se conecta a través de una de ellas.
Por último, configura un recordatorio dos semanas antes de la fecha de renovación de tu VPS para que un aumento de precio no te tome por sorpresa.
All of the tutorial content on this website is subject to Hostinger's rigorous editorial standards and values.


Comentarios
0 responses