SRE Daily Life: Bleeding CART
As you know, we run Hostinger.com. It’s a critical component as it’s like our company’s greeting card. Even more, it’s the main gateway for onboarding new clients and making revenue through the /cart.
Initially, we only had one instance of our main website provisioned in a single data center located in the United Kingdom which was equipped with an archaic network infrastructure. We were experiencing lots of DDoS attacks.
A quick solution was to put the website under Cloudflare to mitigate these attacks. It worked well but not for long. As we were treating the symptoms, the actual problem persisted until we suffered a huge blackout when that aforementioned data center went down for more than 4 hours.
Scaling Issues
We decided to scale our application across the globe by launching two instances of applications per location. We use our global Anycast at the moment in three locations: Singapore, the United States, and the Netherlands. In total, we launched six instances.
Once the code was deployed, we encountered a problem with the database – what should we do to make it easily available and accessible?
Our developers determined that the database was mostly receiving read requests, so we decided to start using the Geo Percona XtraDB cluster. We launched one instance per location, in total – three.
Later, it turned out that the /cart endpoint mostly writes to the database. The workload was unexpected and unplanned. We decided to move the /cart logic to Redis. This raised another question – how to scale Redis to avoid the servers from melting down again? It’s mostly used for caching /cart for one month and for shared PHP sessions. And of course, it’s not as critical as the database. It would compensate for some write loads to the database.
We bootstrapped one Redis instance per location without any shared states between them. If a request comes to Europe, then it will use the European Redis instance. If the US, then the American, and so on.
World Domination Tour
Ok, so the solution wasn’t as future-proof as we wanted it to be. Now we had Cloudflare on top and a scaled application in multiple locations. But we ran into another issue. We noticed lots of ‘SQLSTATE MySQL gone away’ errors from our application. I started digging around and noticed that the XtraDB cluster shot timeout errors forming a quorum. As usual, there was no time to investigate it further, so we applied some quick fixes like an increased timeout for a cluster, retries, and window sizes for replication buffers. It worked around 5% better, but we still had timeouts, connection drops, and downtime. Then I checked the latency between XtraDB endpoints. There was a lot of packet loss between Asia and Europe.
I contacted the data center staff to re-route our prefixes through another upstream and the service was back online again. The latency between Asia and Europe is around 250ms, so we have 4 requests per second for writes because the XtraDB cluster acknowledges writes only if all the nodes in the cluster confirm.
The next day, the packet loss between locations started happening again. We contacted the data center guys and managed to fix the problem temporarily again. Eventually, we decided to get rid of the XtraDB cluster.
The next problem was how to keep high availability for database connections if one instance goes down. We launched a custom MySQL cluster solution based on ExaZK. The situation changed a lot.
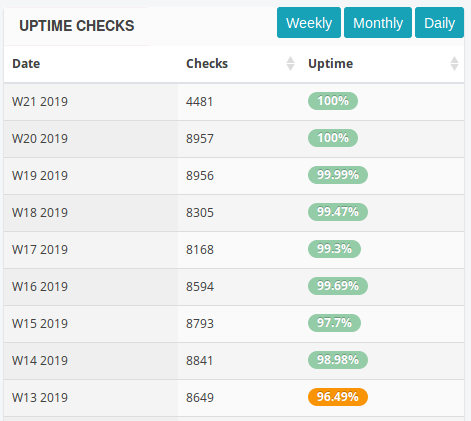
We monitored how the application performs with the new changes for about a week but still noticed huge spikes in response times. We then created a NewRelic account and started monitoring the whole application itself.
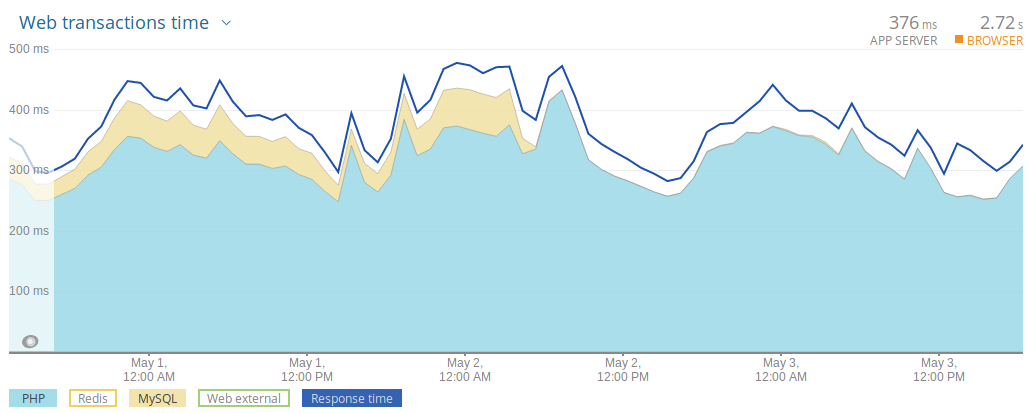
We got some really handy metrics related to MySQL slow queries and external resources. It was very clear what the problem was – we dubbed our MySQL instances with unnecessary read requests by receiving translations for a certain language. We settled out to generate translation files in the JSON format and load them quickly instead of querying the database with every request.
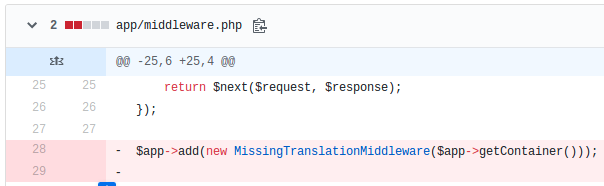

With this change, we cut the latency noticeably when JSON files were adopted for database requests.
Now we have another problem (not as critical as with the database) – JSON files are each around 500kb in size. They are read with every request and generate approximately 3k `read()` syscalls per second. 500kb / 8kb ~= 62 read()s to fully read the language’s file. For those who are interested I got those numbers using the Sysdig command:
# sysdig evt.args contains "json"
We still noticed a very high rate of timeouts in our monitoring tools. We quickly went through Grafana, Prometheus, and Graylog to double-check what’s going on and cross-reference with StatusCake, Pingdom stats.
The issue was that our top of rack switch was faulty and restarted a few times per day. You can check out the gaps in the graph below.
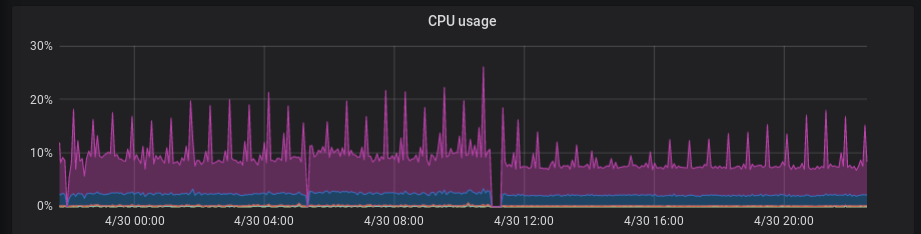
When this happened, ExaZK started to point to a live MySQL instance and it worked in an HA fashion. Eventually, we replaced our faulty network switch with a new one and we started having 100% uptime.
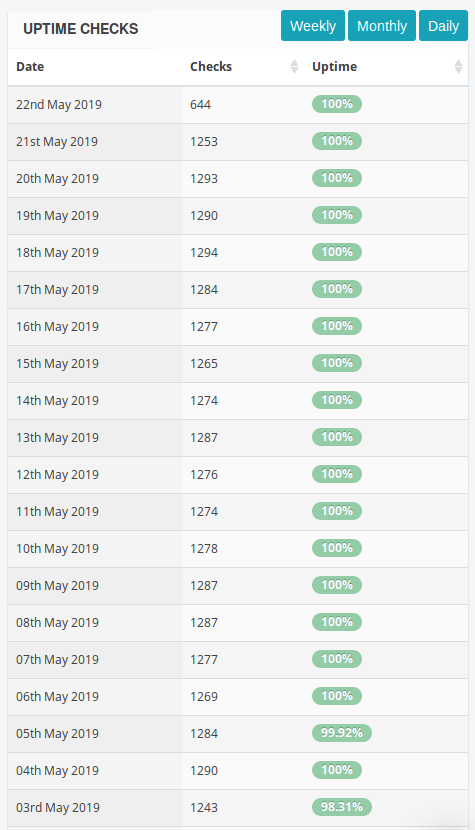
At the moment our website is working as shown in the screenshot below.
Improvements in the Roadmap
We’re planning to force cache translation JSON files directly in the browser to shift the load to the client-side. We’re also going to implement GeoDNS to pick the nearest location to the client’s source IP address. This is already tested in our development environment, but we’re waiting for a stable release of PowerDNS 4.2.
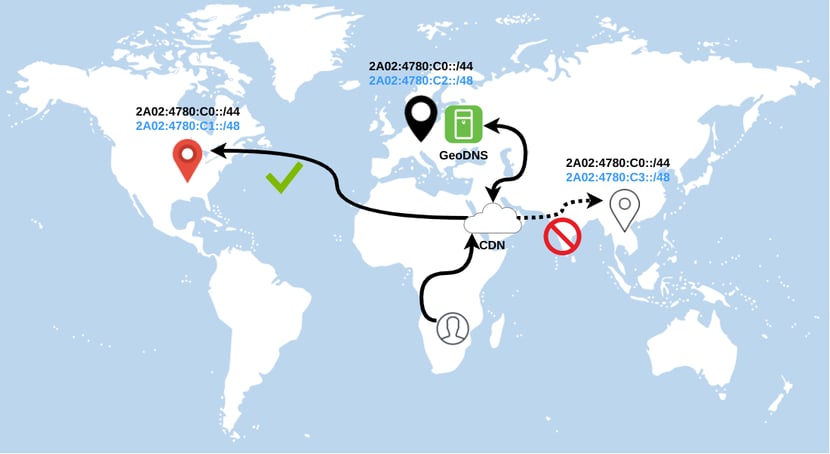
In the future, we would love to implement regional Anycast together with GeoDNS to failover to a live data center in case of failure. One global Anycast plus region allocated prefix. Both are overlapping prefixes that allow having smooth failover if one region goes down completely. For instance, if your GeoDNS server responds to a CNAME record with an IP of 2A02:4780:C3::1 for the CDN’s resolver and at that moment this region is down, new connections will be redirected to the shortest AS-PATH PoP because of the global Anycast overlapped network.



