Meet Our New Network Infrastructure

Before we had opened our data centers in the United Kingdom and the United States, we had some problems with our infrastructure. We had no automation, no version control for router configurations, a single uplink per-data center, stretched VLANs between racks, plus static routes with ECMP, causing a gap in case of anycast node failure.
As we outlined in a previous blog post, we started automating our network, and we rolled out our first automated processes in Singapore and the Netherlands. A few weeks ago, we installed the redundant uplinks using different peers and locations in the Netherlands, which eliminated the single point of failure.
We keep an eye on our SLO-defined uptime which is 99.9%. We always try to exceed this number by spending more time on testing scenarios such as “What would happen if we rebooted one of our spine routers?” or “What would happen if we were upgrading our servers periodically?”. We carry out these tests on ‘Gaming Day’. Oddly, it has nothing to do with gaming. We named it this because carrying out these tests feels like gaming: you move, you wait for a response from the system, and you try something again. While this process is lengthy, it means that our systems are always safe, up-to-date, and have the best possible quality for our clients.
To avoid spending our available SLO budget redundant connections and uplinks ensure high availability during routers upgrades or (un)planned data center maintenances.
Every server serving anycast must be connected with a ToR (top-of-rack) switch using a BGP protocol. Please note that we still have locations where we mix iBGP/eBGP sessions for internal peering. It’s not always easy to work with mixed iBGP/eBGP sessions, but it paves the way for experiments to make improvements.
Before launching anycast in the Netherlands and Singapore, the following for all data centers was adjusted:
- Removing static routes;
- Rebootstrapping anycast nodes with installed ExaBGP, which is responsible for announcements;
- Unifying routing configurations across all data centers.
As I have mentioned before, we used mixed types of peerings, both of which have their own pros and cons. However, standardization and simplicity are the keys to automation.
Hence, the configuration snippet for our servers is relatively simple and looks like this:
router bgp <leaf-private-as> neighbor SERVERS peer-group neighbor SERVERS remote-as 65030 neighbor SERVERS local-as 65534 no-prepend replace-as neighbor 2a02:4780:8::fefe peer-group SERVERS
- leaf-private-as is a unique AS number per rack, which identifies routes and forces in the eBGP connections. These avoid additional route reflectors in the middle.
- remote-as is the same for all servers in all data centers.
- local-as is the same as well to have ONE configuration that matters. From the server point of view, it’s enough to define prefixes to announce and that’s it, everything else is done automatically.
We have expanded our anycast usage as much as we can to help our new products. At first, we launched 000webhost.com’s reverse proxies with the anycast network. Then, we launched DNS and API services; even Redis slaves are using anycast addresses to discover master nodes. We are also planning to anycast for MySQL setups.
Last week we migrated our file manager to the anycast network as well. We deployed two instances per data center and had a problem with storing sessions for every location. However, centralized Memcached or Redis would be too slow for intercontinental connections. Should we spin up decentralized and dedicated sessions stored per data center? How about keeping single and unified /etc/php.ini for every deployment? Not a problem, anycast to the rescue again. And we have a single role per deployment.
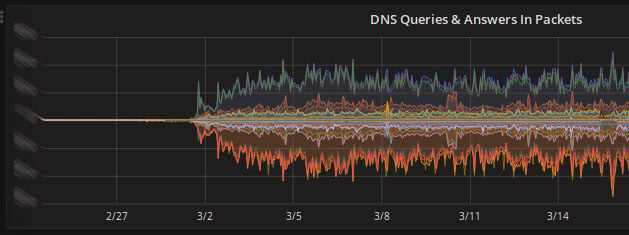
This is the DNS traffic switch to anycast for any1.hostinger.com and any2.hostinger.com.
To add more glue we use IPv6 everywhere internally(!) and almost everywhere externally. We even switched API calls and other critical parts through IPv6 instead of IPv4. Our new private network (10.0/16) has just become the IPv6 network. Operating both protocols literally means having high availability because if IPv4 is down, the traffic is likely to flow through the IPv6 path and vice versa. Even different upstream along the path could be picked for the destination.
We plan to provide a unique IPv6 address for every website or client. How cool is that? It would solve many issues. For instance, with IPv4, if IP is null-routed, many clients are affected if they point to the same IP. With IPv6 this is different since we can give unique IPv6 per website or client and avoid this kind of problem.
Conclusion
Over the last few months, we have massively improved our network infrastructure and we are certain that our clients will feel the huge performance gains we have made. In the near future, we will also upgrade the network in our United States data center.
But why are we making these changes? Our goal is to move to a fully redundant network to ensure as few interruptions as possible during upgrades for our customers.
The anycast we deployed in two new locations will speed up the DNS responses for our customers. What’s more, 000webhost.com and some Hostinger clients are now using anycast with three locations: the United States, the Netherlands, and Singapore.



